SQLSweet16!, Episode 3: Parallel INSERT … SELECT
Sanjay Mishra, with Arvind Shyamsundar
Reviewed By: Sunil Agarwal, Denzil Ribeiro, Mike Ruthruff, Mike Weiner
Loading large amounts of data from one table to another is a common task in many applications. Over the years, there have been several techniques to improve the performance of the data loading operations. SQL Server 2014 allowed parallelism for SELECT … INTO operations. However, the users needed more flexibility, in terms of placement of the target table, existing data in the target table, etc., which are not possible with the SELECT … INTO statement. Loading data into an existing table (with or without existing data) through an INSERT … SELECT statement has been a serial operation. Until SQL Server 2016.
SQL Server 2016, under certain conditions, allows an INSERT … SELECT statement to operate in parallel, thereby significantly reducing the data loading time for these applications. A hidden gem!
Figure 1 illustrates loading time with and without parallelism. The test was performed on an 8-core machine (Figure 3 shows the degree of parallelism achieved), on a table with 50 million rows. Your mileage will vary.
[caption id="attachment_2985" align="alignnone" width="827"]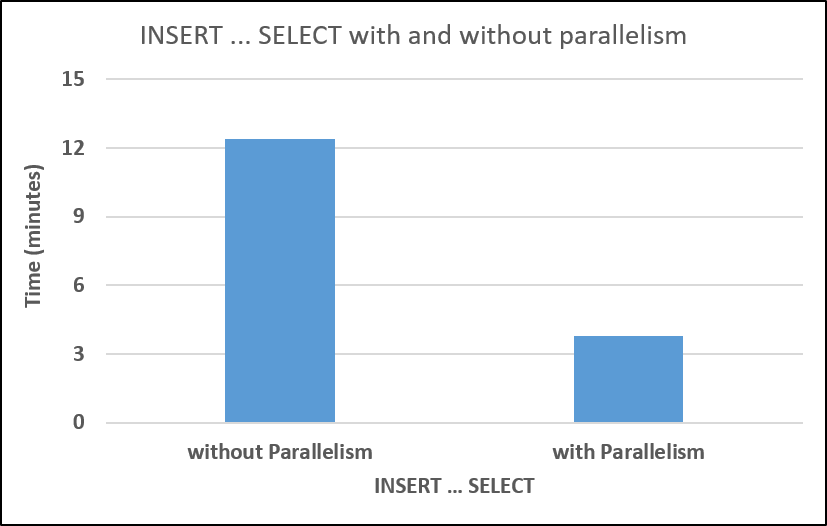 Figure 1: INSERT ... SELECT with and without parallelism (SQL Server 2016)[/caption]
Figure 1: INSERT ... SELECT with and without parallelism (SQL Server 2016)[/caption]
Important to Know
Two important criteria must be met to allow parallel execution of an INSERT … SELECT statement.
- The database compatibility level must be 130. Execute “SELECT name, compatibility_level FROM sys.databases” to determine the compability level of your database, and if it is not 130, execute “ALTER DATABASE <MyDB> SET COMPATIBILITY_LEVEL = 130” to set it to 130. Changing the compatibility level of a database influences some behavior changes. You should test and ensure that your overall application works well with the new compatibility level.
- Must use the TABLOCK hint with the INSERT … SELECT statement. For example: INSERT INTO table_1 WITH (TABLOCK) SELECT * FROM table_2.
There are a few restrictions under which parallel insert is disabled, even when the above requirements are met. We will cover the restrictions, and work arounds, if applicable, in a separate blog post.
How to know you are getting parallelism
The simplest way to check for parallelism is the execution plan. Figure 2 shows an execution plan for an INSERT … SELECT statement without parallelism.
[caption id="attachment_2986" align="alignnone" width="975"]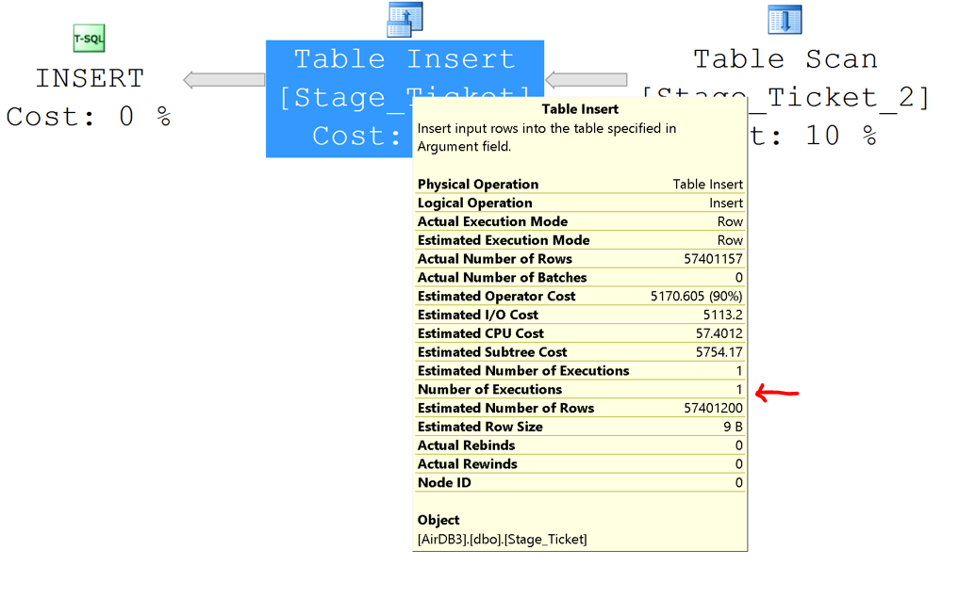 Figure 2: INSERT ... SELECT execution plan without parallelism[/caption]
Figure 2: INSERT ... SELECT execution plan without parallelism[/caption]
Under appropriate conditions, the same statement can use parallelism, as shown in Figure 3.
[caption id="attachment_2976" align="alignnone" width="1000"]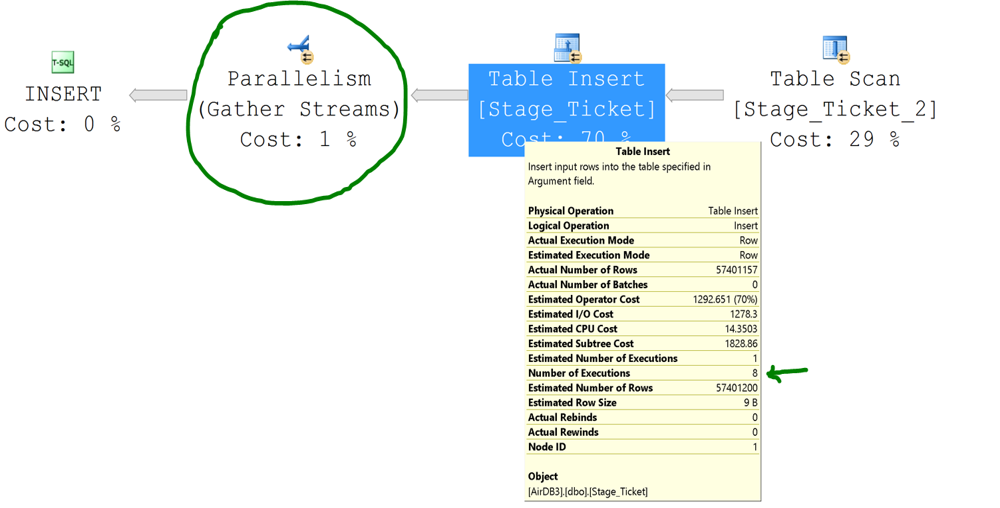 Figure 3: INSERT ... SELECT execution plan with parallelism[/caption]
Figure 3: INSERT ... SELECT execution plan with parallelism[/caption]
Call to Action
Tell us about your application scenarios where you plan to use this functionality. Also if you are already taking advantage of this hidden gem, share some data points, such as data volume, load time, the benefits you are seeing from parallelism, etc.