Upgrade your SQL Server to scale before adding new hardware
In SQL Server Tiger team, we closely partner with our customers and partners to ensure they can successfully run and scale their Tier 1 mission critical workloads and applications on SQL Server. Based on our experience and interactions with customers, we found that most customers running older releases of SQL Server and experiencing performance and scalability issues for their workload on SQL Server would plan throw more hardware at the problem keeping the application and SQL Server version unchanged. The challenge with this approach is, you are expecting a software written and tested on servers available more than a decade ago to run and scale out of the box on modern high-end servers with large memory, high core density socket configuration. While the software may work, but it may not scale and in some occasions, may perform poorly especially if you are hitting memory object scaling issues (CMEMTHREAD) as now you have more resources to run concurrent threads in parallel, but all threads wait on a single memory object for memory which becomes a point of contention and bottleneck on the high-end server.
The following SQLOS and memory enhancements in SQL Server 2016/2017 allows SQL Server engine to scale out of the box on high end servers.
Dynamic Memory Object Scaling – This improvement dynamically partitions memory objects from single unpartitioned object to NUMA level (1 per each node) and further down to CPU nodes (1 memory objects per cpu) depending on the contention factor on the memory object.
Dynamic Database lock partitioning – This improvement partitions the database locks (SH) which minimizes the hash collisions when the concurrent connections are higher on a single database which is common when you move to high end servers.
SOS_RWLock Redesign - The SOS_RWLock is a synchronization primitive used in various places throughout the SQL Server code base. With SQL Server 2016, SOS_RWLock uses optimistic concurrency while accessing database state that minimize blocking and allows reader/writer workload to scale out of the box.
Indirect Checkpoint – As I explained in my previous blog post, indirect checkpoints not just smoothens the IO burst on large memory servers but also enables dirty page tracking per databases and schedulers which decouples the dirty page scans from the memory size and allows checkpoints for databases to scale independent of the buffer pool size.
Note: When you upgrade the databases from lower version, indirect checkpoint is **NOT** turned ON by default for upgraded database. You will need to explicitly turn it ON by setting target_recovery_time for the databases.
Auto Soft NUMA - This improvement sub-partitions the NUMA nodes to further partition and scale some of the internal structures (CMEMTHREAD) which is very useful on high density processor machines.
In addition, upgrading to SQL Server 2016/2017 allows you to leverage new features like Columnstore Indexes, In-Memory schema only temp tables, table variables, parallel inserts to further scale your workload if you can afford some database schema changes.
In most scenarios, customers choose to add new hardware as opposed to upgrading their SQL Server since the general perception is that cost of upgrade is high. While before you go with this anecdotal assumption, it is important to assess and estimate the cost of upgrade. This is where a tool like Data Migration Assistant (DMA) can be very valuable. DMA is a complete rewrite and makeover of the SQL Upgrade Advisor tool. The team has done great job with DMA to help identify blockers for upgrade and also provide guidance on how to overcome them. In addition, DMA assesses the databases against multiple compatibility levels in single run to provide a recommendation on which DBCompat setting would be a right fit for your database application. Running DMA would allow you to accurately estimate the cost, changes and risk involved in upgrade.
Further, when you upgrade, we recommend keeping the database compatibility level to the older version with query store turned ON. Later, you can test to change the DBCompat level to the latest level and use query store to identify the queries which have regressed.
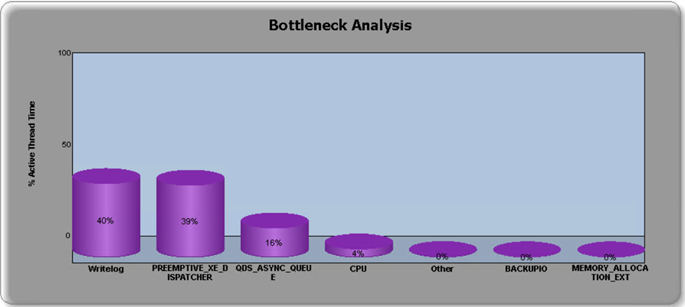
Let me back the above theory and claim with some data as we recently put this approach to practice with one of our customer running Tier 1 mission critical workload on SQL Server 2008 R2. The customer's business was growing and the concurrent workload on their server increasing such that the application started to see poor response time and timeouts. They had established a performance baseline with around 16-18K Batch Requests/ sec and observed when the workload exceeds 19-20K Batch Requests/sec, the application starts to see poor response time and timeouts. Based on the investigation by our CSS teams, it was found the workload was hitting memory object contention which is not partitioned in SQL Server 2008 R2 limiting the concurrency and scalability of the application. The initial plan by customer was to add more hardware resources to scale, but we were confident that would not solve the issue and can potentially make it worse. We recommended them to run DMA and assess their database schema and TSQL code to see if there are any upgrade blockers. We found that there were few stored procedures using TSQL syntax which were deprecated but it was never being used so we could ignore them.
After some functional testing it was clear the application just works on SQL Server 2016 SP1 CU5 under DBCompat 100 without making any code changes. Next, we wanted to test if upgrading to SQL Server 2016 solves the original scalability issue which the application originally experienced. We ran some application performance and stress tests adding more workload (22-25K Batch Requests/sec) first on SQL 2008/Windows 2008 R2 to establish baseline and later on upgraded SQL 2016/Windows Server 2012 to perform A/B testing keeping the hardware and application unchanged.
Following are the results of the A/B testing of application for the same workload running against SQL 2016 v/s SQL 2008.
With Indirect Checkpoint, the IO spikes reduced significantly to smoothen the IO flushes as shown below with max of 70 pages/sec compared to 250 pages/sec in SQL 2008 R2.
SQL 2016 (Background Writer Pages/sec)
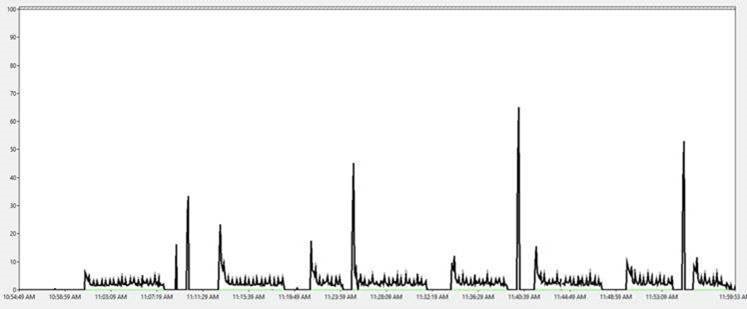
SQL 2008 (Checkpoint Pages/sec)
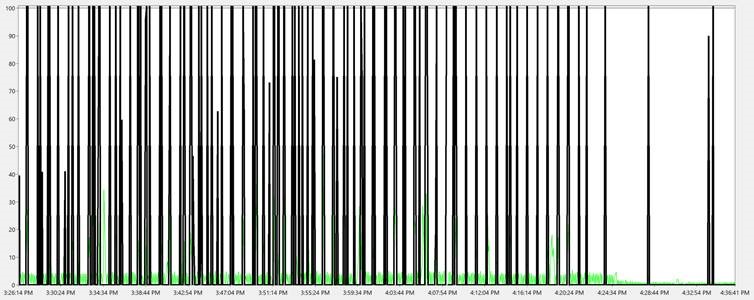
The Total Latch wait time reduced to 2.4 ms compared to 26 ms in SQL 2008 run.
SQL 2016

SQL 2008

LOCK_HASH spinlock reduced and SOS_RWLOCK spinlock waits vanished as expected in SQL 2016.
SQL 2016
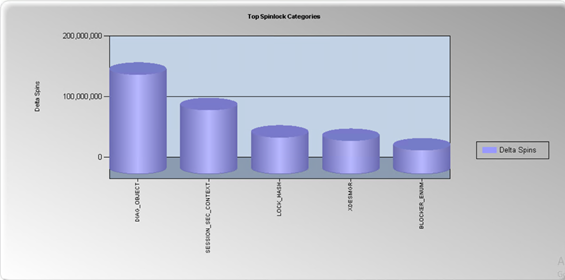
SQL 2008
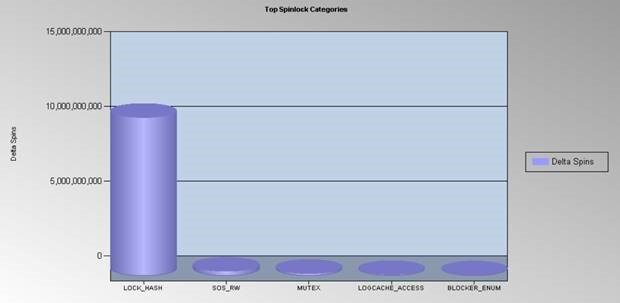
We tested and identified the following configuration in SQL Server 2016 gave us the best results from performance, scale and supportability perspective. There is no impact observed on the application performance with Query store turned ON except for a bit more memory consumed and Disk flushes (Disk bytes/sec) but considering how useful it is for DBAs to quickly narrow down and identify query regressions on production servers, it is worth it.
SQL Server 2016 SP1 CU5 (Build 13.0.4451.0)
Query Store turned ON with following configuration
ALTER DATABASE <database name>
SET QUERY_STORE
( OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30),
DATA_FLUSH_INTERVAL_SECONDS= 900,
MAX_STORAGE_SIZE_MB = 1024,
INTERVAL_LENGTH_MINUTES= 15,
SIZE_BASED_CLEANUP_MODE = AUTO,
QUERY_CAPTURE_MODE = AUTO,
MAX_PLANS_PER_QUERY = 1000
);Trace flag 7752 turned ON to enable async load of Query store.
Indirect checkpoint turned on for user databases with target_recovery_time = 60 seconds
DBCompat for user databases: 100
Scaling up further with In-Memory temp tables in SQL Server 2016
Once we go passed some of the initial bottlenecks which throttles the workload on lower version, it might expose you to the cracks or some other choking point as you continue to stress test and increase the concurrency. In most workload, after a certain tipping point, the response time again starts to suffer due to tempdb allocation or metadata contention or log flushes assuming there are no other blocking in the database. In SQL Server 2016/2017, we can overcome this and enable workload to scale further with memory by converting temp tables, table variables for some of the highly executed stored procedures and high touch tables to in-memory. The right candidates (tables or stored procedure) for in-memory tables can be discovered easily using the Transaction Performance Analysis Overview report in SSMS.
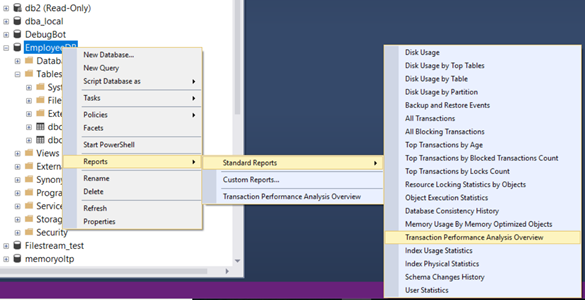
In our lab, we discovered a session state table and very highly executed stored procedure as good candidates to convert to in-memory table using the approach documented here. This change further boosted the scale of the application where we achieved sustained consistent response times with higher workload as there was no logging overhead or tempdb allocation overhead.
If you are unable to convert the tables to schema only tables, you can leverage storage class memory (NVDIMM-N non-volatile storage) and SQL Server's persistent storage buffer available starting SQL 2016 SP1 to further scale your workload minimizing the writelog overhead. If you use low latency flash array for log files, the WRITELOG waits can also be reduced to minimum (4-8ms).
As explained above, it makes more sense to upgrade your SQL Server first before upgrading your hardware since upgrading SQL Server and OS itself can provide better scale out of the box even if the hardware remains the same. In addition, with latest SQL Server version, you can leverage latest features and innovations built on top of some of the latest hardware technology to make the best use of modern hardware to scale your workload further up.
Parikshit Savjani
Senior PM, SQL Server Tiger Team
Twitter | LinkedIn Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam