SQL Server 2016, Minimal logging and Impact of the Batchsize in bulk load operations
One of the design goals of SQL Server 2016 was to improve performance and scalability of the engine out of the box to make it run faster without the need of any knobs or trace flags for customers. As a part of these improvements, one of the enhancements made in the SQL Server engine code was turning on bulk load context (also referred as fast inserts or fast load context) and minimal logging by default when performing bulk load operations on database with simple or bulk logged recovery model. If you are not familiar with minimal logging, I would highly recommend reading this blog post from Sunil Agrawal where he explains how minimal logging works in SQL Server. For bulk inserts to be minimally logged, it still needs to meet the pre-requisite conditions which are documented here.
As part of these enhancements in SQL Server 2016, you no longer need to enable trace flag 610 for minimal logging into indexed table and it joins some of the other trace flags (1118, 1117, 1236, 8048) to become of part of the history. In SQL Server 2016, when the bulk load operation causes a new page to be allocated, all of the rows sequentially filling that new page are minimally logged if all the other pre-requisites for minimal logging discussed earlier are met. Rows inserted into existing pages (no new page allocation) to maintain index order are still fully logged, as are rows that are moved as a result of page splits during the load. It is also important to have ALLOW_PAGE_LOCKS turned ON for indexes (which is ON by default) for minimal logging operation to work as page locks are acquired during allocation and thereby only page or extent allocations are logged.
With the changes in SQL Server 2016, the table that summarizes minimal logging condition in our popular Data Loading Performance Guide changes to below
| Table Indexes | Rows in table |
Hints |
With or Without TF 610 |
Concurrent possible |
| Heap | Any | TABLOCK | Minimal | Yes |
| Heap | Any | None | Full | Yes |
| Heap + Index | Any | TABLOCK | Depends (3) | No |
| Cluster | Empty | TABLOCK, ORDER (1) | Minimal | No |
| Cluster | Empty | None | Minimal | Yes (2) |
| Cluster | Any | None | Minimal | Yes (2) |
| Cluster | Any | TABLOCK | Minimal | No |
| Cluster + Index | Any | None | Depends (3) | Yes (2) |
| Cluster + Index | Any | TABLOCK | Depends (3) | No |
(1) If you are using the INSERT … SELECT method, the ORDER hint does not have to be specified, but the rows must be in the same order as the clustered index. If using BULK INSERT the order hint must be used.
(2) Concurrent loads only possible under certain conditions. See "Bulk Loading with the Indexes in Place". Also, only rows written to newly allocated pages are minimally logged.
(3) Depending on the plan chosen by the optimizer, the nonclustered index on the table may either be fully- or minimally logged.
Impact of Batchsize in bulk load operations
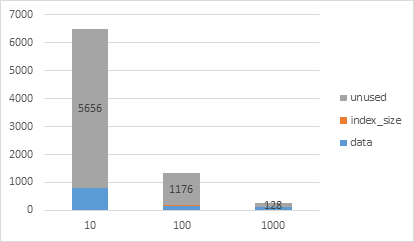
While minimal logging and bulk load operations helps improve the performance of data load operations in indexes when data is pre-ordered or sequentially loaded, batchsize plays a critical role to achieve faster performance with efficient space utilization of the page and extent allocated by the bulk load operations. With fast load context, each bulk load batch acquires a new extent(s) bypassing the allocation cache to lookup for an existing extent with available free space to optimize insert performance. This means if you utilize smaller batchsize for e.g. 10 rows per batch, a new extent of size 64KB is reserved for each 10 records batch with the remaining pages in the extent unused but reserved for the object resulting into inefficient space utilization.
Thanks to Dan Guzman(b) who provided us with a repro of this scenario in SQL Server 2016 where we bulk load 1000 records with different batchsizes and the results of sp_spaceused is as shown below. You can see from the chart below, bulk load with batchsize of 10 rows leads to highest unused space followed by batchsize of 100 and least unused space when we use batchsize of 1000 which loads all records in single batch.
| BatchSize | Data (KB) |
index_size(KB) |
Unused (KB) |
Reserved (KB) |
| 10 | 808 |
8 |
5656 |
6472 |
| 100 | 168 |
8 |
1176 |
1352 |
| 1000 | 128 |
8 |
128 |
264 |
It is also important to remember in minimal logging mode, data pages are flushed as soon as the batch is committed as we do not log all records and only allocations are logged. Hence if we choose a large batch size it can lead to write IO bursts and if the IO subsystem is not capable of handling the write IO burst, it can adversely affect the performance of bulk load operation and all other transactions running on SQL Server instance at that time.
It is therefore important to choose a batchsize which is multiple of the size of an extent (64KB) based on the average row size so that the rows efficiently fills the space within the extent and further the write IO size is limited to 64KB which is handled easily by most IO subsystem. Depending on the underlying disk IO performance, you can choose a batchsize anywhere between the size of 1 extent (64KB) to 64 extents (4MB), to strike a balance between efficient space utilization and optimal bulk load performance.
If for any reason, you cannot change the batchsize or if you are not seeing an improved data load performance with default minimal logging behavior, you can disable fast inserts behavior in SQL Server 2016 using trace flag 692 which we have documented here. We do not anticipate under normal circumstances this trace flag will be required for customers.
On a side note, we have many customers hitting AV with merge statement against database in simple recovery model as reported in connect item here. While we are working on the fix for the issue which will be released in upcoming servicing releases for SQL Server 2016, in the interim until the fix is made available, you can workaround the issue by using trace flag 692 at the session level or server level which disables minimal logging. Alternatively, you can also switch to full recovery model which also disables minimal logging but it can lead to increased transaction log management overhead.
Parikshit Savjani
Senior PM, SQL Server Tiger Team
Twitter | LinkedIn
Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam