How we made backups faster with SQL Server 2017
In my previous blog post on enhancements in SQL Server 2017, we briefly introduced improved backup performance for smaller databases in SQL Server 2017 on high end servers. In the recent PASS Summit 2017, Pedro and I delivered a session on Intelligent diagnostics where we explained how we leveraged the indirect checkpoint heuristics to enable faster backups. In this blog post, I would elaborate more to share some of the internals details which enabled us to make this improvement.
Indirect Checkpoints is not just about predictable recovery, it enables SQL Server to scale and run faster
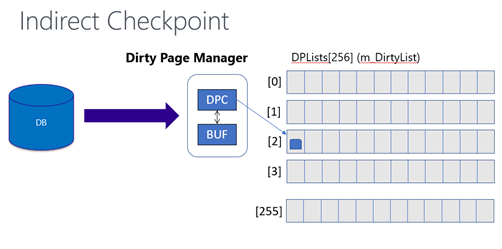
In SQL Server 2012, indirect checkpoint was first introduced in SQL Server and it was made a default algorithm for all new databases starting SQL Server 2016. SQL Server maintains a buffer list array to track all buffers in the buffer pool. This array avoids scanning individual buffers and makes it fast and easy to scan the list instead. When automatic checkpoint is triggered for a database, the buffer list is scanned to identify all the dirty buffers which belongs to that database and needs to be flushed. The size of buffer list array is proportional to the physical memory on the server and max server memory set for the instance. For instance, for a 4TB system, the length of the array is roughly 500 million data structures. As the only way to determine whether a buffer is dirty or not and belongs to the database is by scanning the full list, the scanning of buffer list during checkpoints gets increasingly slower and languishes noticeably on high end servers with large memory.
In RDBMS, whenever tables get larger, one of the technique to tune and optimize the scans on the tables is by partitioning it. With indirect checkpoints, we do the same.
In indirect checkpoint, for every database which has target_recovery_time set, a dirty page manager and dirty page list is created. The dirty page list is further partitioned by scheduler allowing the dirty page tracking to scale further. This decouples the dirty page scan for a given database from the size of the buffer pool and allows the scan to scale and be much faster than automatic checkpoint algorithm.
As Bob Dorr mentions in his blog here, a new database creation process in SQL Server 2016 requires only 250 buffers to scan as opposed to 500 Million buffers with former algorithm. This is the rationale for making indirect checkpoint a default which is much more scalable algorithm to track dirty pages in the buffer pool compared to automatic checkpoints.
Backup Performance Improvement
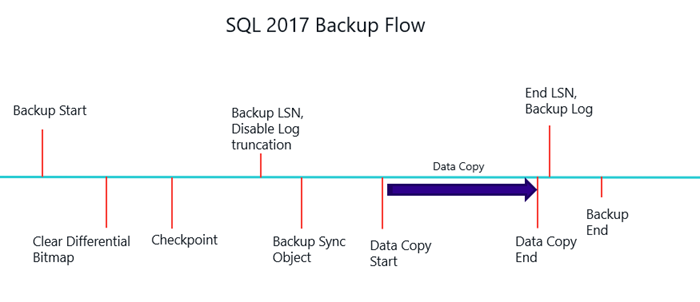
Following is an oversimplified version of backup flow in SQL Server. There are couple of places in the backup where we need to iterate and scan through the buffer pool to drain out pending modifiers or IO writes to buffers before we move on to data copy operation for backup.
The first iteration is when we clear the differential bitmap. In this case, after clearing differential bitmap, we want to make sure all the buffer modifiers which started before clearing the differential bitmap are determined.
The second iteration is when we create a backup sync object. Backup sync object is used to track all the new modifications in the pages when the data pages are copied from storage to backup file. Backup sync object can only track future modifications so we need to first drain out all pending IOs before we start the data copy. To identify any pending IO we iterate through the buffer pool and try to acquire a latch. If the buffer is pending on IO, latch cannot be acquired and we wait to flush the buffer.
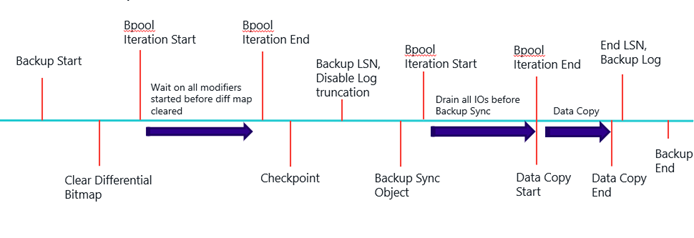
In SQL Server 2017, we eliminated the buffer pool iteration at both places by alternatives that make backups faster. To eliminate first iteration, we made use of indirect checkpoint prepare to dirty list to identify all the modifiers for that database which started before the clearing of differential bitmap. To eliminate second iteration, we made use of the IO dispensers maintained by SQL Server at a lower level which tracks all pending page IO operations. The new backup flow is as shown below (again oversimplified)
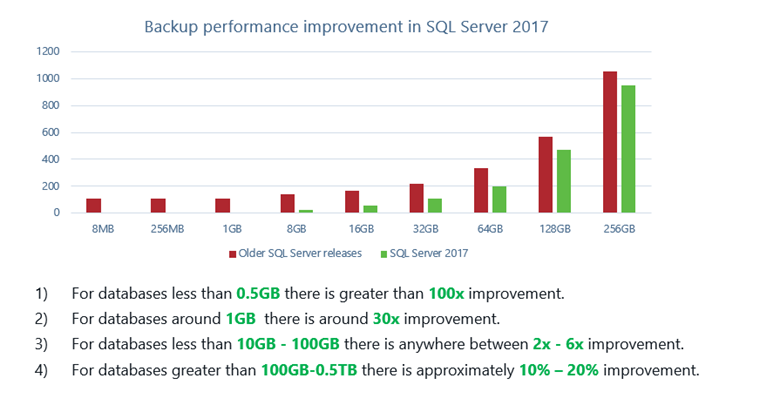
With the previous algorithm while backing up smaller databases including system databases on high end server with large memory, the iteration through buffer pool (scanning ~2*500 million buffers) itself consumes long time relative to the actual data copy operation. This is where thanks for indirect checkpoint, we see an immediate performance boost in backup performance. Following is the performance results comparison for backups performed on databases of various sizes performed on 2TB memory server. For smaller databases, we see improvements from 30x-100x where buffer pool scan time is dominant compared to data copy time. As the database size increases, the data copy time becomes dominant where the performance improvement appears to be relatively small.
Parikshit Savjani
Senior PM, SQL Server Tiger Team
Twitter | LinkedIn
Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam