Columnstore Index Performance: SQL Server 2016 – Aggregate Pushdown
SQL product team has made significant improvements in columnstore index functionality, supportability and performance during SQL Server 2016 based on the feedback from customers. This blog series focuses on the performance improvements done as part of SQL Server 2016. Please refer to previous blog No performance cliff in this series for details.
Aggregates are a very common construct in analytics queries. For example, you may want to aggregate sales per quarter for each products you sell. With columnstore index, SQL Server processes aggregate in BatchMode thereby delivering order of magnitude better performance when compared to rowstore. SQL Server 2016 takes the aggregate performance to the next level by pushing aggregate computations to the SCAN node. Yes, this improvement is on top of BatchMode execution.
The picture below shows and aggregate query that processes 10 million rows and computes a single aggregate SUM of Quantity sold from the SALES table SELECT SUM (Quantity) FROM SALES
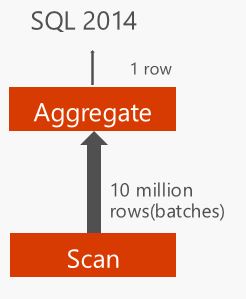
SQL Server 2014 scans these 10 million rows in batches (e.g. 900 rows) and sends these batches to Aggregate operator to compute the aggregate. The picture below shows 10 million rows moving from SCAN node to the Aggregate node.
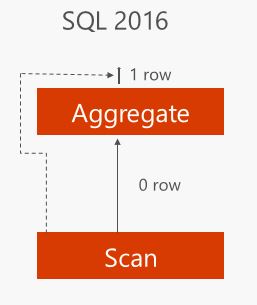
In SQL Server 2016, the aggregate operator itself is pushed to the SCAN node (i.e. closer to the source of the data) and the aggregate is computed there for compressed rowgroups. The picture below shows that 0 rows moved from SCAN node to the AGGREGATE node. This is because the aggregate was computed at the SCAN node. The dotted line shows the computed aggregate, 1 row in this case, was sent internally to the output of AGGREGATE node. Couple of important points to note
- The structure of Query plan structure is identical between SQL Server 2014 and SQL Server 2016 and the main difference is how the rows are processed. For this reason, Aggregate pushdown optimization is available across all database compatibility levels.
- Aggregate push down is only done for the rows in compressed rowgroup. The rows in delta store will flow from SCAN node to the AGGREGATE node like before
Let us now look at a concrete example that contrasts the aggregate processing between SQL Server 2014 and SQL Server 2016.
SQL Server 2014
The picture below shows a aggregate query and its execution plan. Note that all 11 million row flow from SCAN node to the AGGREGATE node.
The query execution time for this query was as follows
SQL Server Execution Times: CPU time = 547 ms, elapsed time = 389 ms. 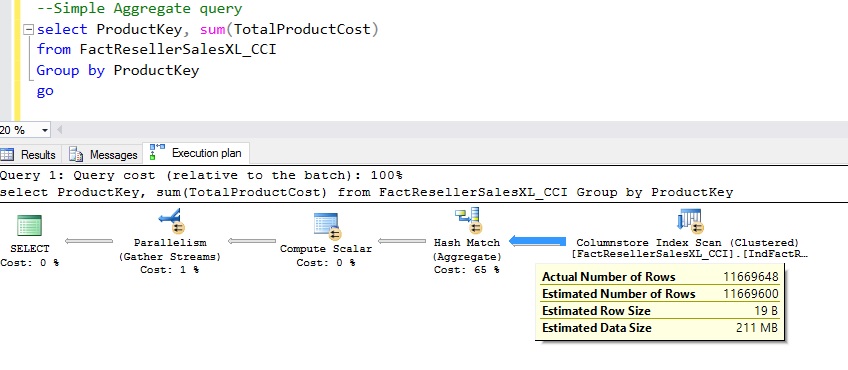
SQL Server 2016
The same query was run ‘as is’ on SQL Server 2016 and as the picture below shows the aggregate computation was indeed done at the SCAN node. The query execution time for this case was 2x lower than what we saw with SQL Server 2016. A more interesting number is the CPU time which was 3x lower than SQL Server 2014. In actual production workloads, we have seen much more dramatic performance gains.
SQL Server Execution Eimes CPU time = 171 ms, elapsed time = 167 Ms.
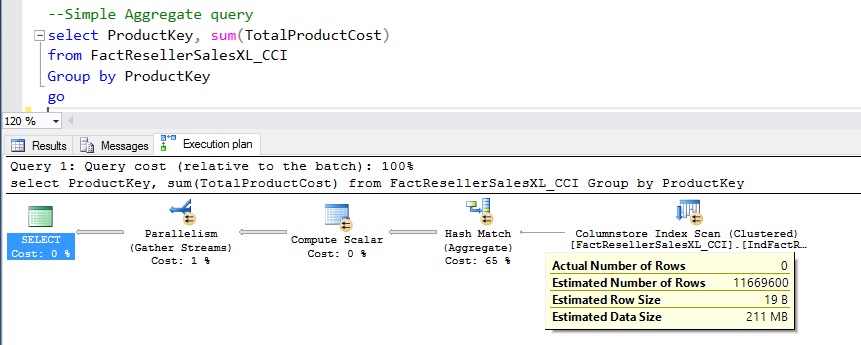
Other interesting thing to notice is that the SCAN node has a property to show the number of rows that were aggregated locally. As expected for the example above, as shown in the picture below, all the rows were aggregated locally 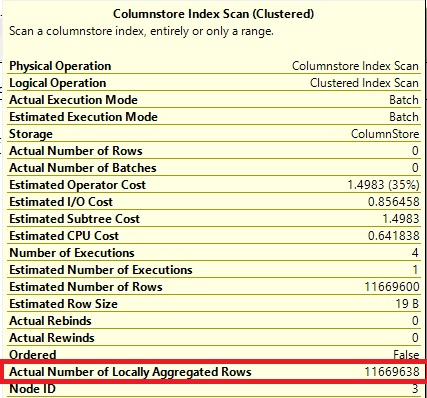
To show that Aggregate pushdown optimization is not a available for rows in delta rowgroup, I copied 50k rows into new table temp_cci with clustered columnstore index and then I ran the same aggregate query as shown in the picture below. Note, that all 50k rows are flowing from SCAN node to AGGREGATE node
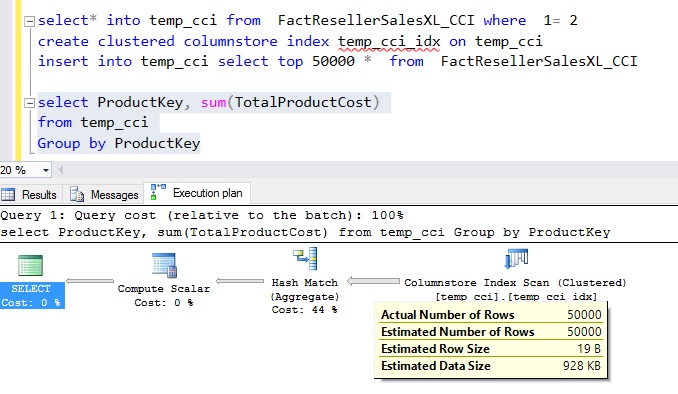
In summary, Aggregate Pushdown will give you the performance boost automatically when you upgrade your application to SQL Server 2016 requiring no changes to your query. Here are the supported cases for Aggregate push down
- The aggregates are MIN, MAX, SUM, COUNT and COUNT(*)
- The input and output datatype fits within 64 bits value.
- Tiny int, int, big int, small int, bit
- Small money, money, decimal and numeric which has precision <= 18
- Small date, date, datetime, datetime2, time
Aggregate push down is not supported for
- Distinct aggregate.
- String column
- Virtual column
Thanks,
Sunil Agarwal
SQL Server Tiger Team
Twitter | LinkedIn
Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam