Addressing large memory grant requests from optimized Nested Loops
Optimized Nested Loops (or Batch Sort) is effectively an optimization aimed at minimizing I/O during a nested loop when the inner side table is large, regardless of it being parallelized or not.
The presence of this optimization in a given plan may not be very obvious when you look at an execution plan, given the sort itself is hidden, but you can see this by looking in the plan XML, and looking for the attribute Optimized, meaning the Nested Loop join may try to reorder the input rows to improve I/O performance. You can read more about optimized Nested Loops in Craig Freeman's blog.
We have encountered cases of performance issues where the root cause is tracked back to an extreme memory grant request from a query with these Batch Sorts. When the Optimizer uses a optimized Nested Loop join or "Batch Sort", the estimated used for memory grants can be much larger than the memory used for the operation.
The issue occurs when the outer table of the Nested Loop join has a predicate that filters the result to a small input, but the batch sort appears to be using an estimate for cardinality that is equivalent to the entire outer table. This can result in a perceived excessive memory grant which in a very concurrent server can have several side-effects, like OOM conditions, memory pressure for plan cache eviction, or unexpected RESOURCE_SEMAPHORE waits. We have seen how a single query that match this pattern can actually get several GB’s of granted memory on high-end machines (1TB+ RAM).
One option until now would be to disable this feature globally using Trace Flag 2340, as described in KB 2801413. However, in SQL Server 2016 RC0 we have changed the behavior to maintain the advantage of the optimization, but now the max grant limit is based on the available memory grant space. This improvement also translates into better scalability, in the sense more queries can be executed with a smaller memory footprint. We are looking at back porting this behavior to an upcoming have ported this behavior to SQL Server 2014 Service Pack 2, and as usual deliver added value to in-market versions.
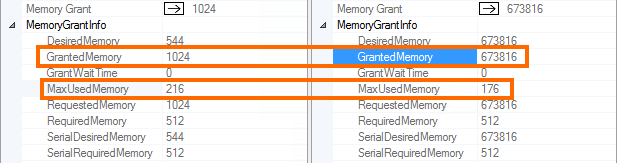
You can see below the difference of granted memory for the same query (left is SQL Server 2016 RC0, right is SQL Server 2014). The ratio between granted memory and the max used memory is proportionally very large on the right side.
Pedro Lopes (@sqlpto) – Senior Program Manager