Locality Sensitive Hashing (LSH) and Min Hash
[Indyk-Motwani’98]
Many distance related questions (nearest neighbor, closest x, ..) can be answered more efficiently by using locality sensitive hashing, where the main idea is that similar objects hash to the same bucket.
LSH function:
Probability of collision higher for similar objects
Hash data using several LSH functions
At query time, get all objects in the bucket where query object hashes to. Then compute similarity and find the closest one.
Main point: LSH reduces the candidates for similarity comparison
Example of LSH function:
Set S of d integers.
h(S) = list of integers at k random indexes (r)
S = {12, 9, 13, 98 , 2, 4, 43, 21, 53, 99}
k=3, r={3, 5, 9}
h(s) = 98499
Similar sets have high probability of hashing to 98499.
Use multiple different LSH functions, get a union of results as candidates.
P(h(p)=h(q)) looks like this:
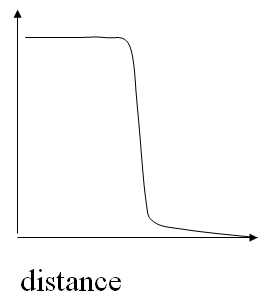
By controlling parameters, k and n the number of hash functions we can control steepness and position of the curve.
LSH with Min Hash
Simple trick: the hash functions of MinHash can serve as LSH functions.
Recall min hash signature matrix has Sets (column) vs hash functions (rows).
Partition k hash functions into bands b bands or r hash functions. (br=k)
b bands --> n LSH functions
r --> k
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace SetSimilarity
{
class LSH<T>
{
int m_numHashFunctions;
int m_numBands;
Dictionary<int, HashSet<int>> m_lshBuckets = new Dictionary<int, HashSet<int>>();
HashSet<T>[] m_sets;
int[,] m_minHashMatrix;
const int ROWSINBAND = 5;
//first index is Set, second index contains hashValue (so index is hash function)
public LSH(int[,] minHashMatrix, HashSet<T>[] sets)
{
m_numHashFunctions = minHashMatrix.Length/sets.Length;
m_numBands= m_numHashFunctions / ROWSINBAND;
m_sets = sets;
m_minHashMatrix = minHashMatrix;
for (int s = 0; s < sets.Length; s++)
{
for (int b = 0; b < m_numBands; b++)
{
//combine all 5 MH values and then hash get its hashcode
//need not be sum
int sum = 0;
for (int i = 0; i < ROWSINBAND; i++)
{
sum += minHashMatrix[s, b*ROWSINBAND+i];
}
if(m_lshBuckets.ContainsKey(sum))
{
m_lshBuckets[sum].Add(s);
}
else
{
var set = new HashSet<int>();
set.Add(s);
m_lshBuckets.Add(sum, set);
}
}
}
}
public int FindClosest(int setIndex, MinHash minHasher)
{
//First find potential "close" candidates
HashSet<int> potentialSetIndexes = new HashSet<int>();
for (int b = 0; b < m_numBands; b++)
{
//combine all 5 MH values and then hash get its hashcode
int sum = 0;
for (int i = 0; i < ROWSINBAND; i++)
{
sum += m_minHashMatrix[setIndex, b * ROWSINBAND + i];
}
foreach (var i in m_lshBuckets[sum])
{
potentialSetIndexes.Add(i);
}
}
//From the candidates compute similarity using min-hash and find the index of the closet set
int minIndex = -1;
double similarityOfMinIndex = 0.0;
foreach (int candidateIndex in potentialSetIndexes.Where(i => i != setIndex))
{
double similarity = minHasher.ComputeSimilarity(m_minHashMatrix, setIndex, candidateIndex);
if (similarity > similarityOfMinIndex)
{
similarityOfMinIndex = similarity;
minIndex = candidateIndex;
}
}
return minIndex;
}
}
}
For some (large) number of sets with some (large) number of values, computing hash matrix is expensive, but after that finding the closes set takes 10000 times less than doing so by computing hamming distance using the Jaccard measure. Of course, one can compute n^2, distances beforehand, and at query-time do only n comparisons. Depending on the LSH design that may or may not take less time than fn fraction comparisons (because the constant overhead factor is larger).
The other advantage of MinHash+LSH is to reduce size of the signature - i.e size of data that is necessary to maintain (or communicate) in order to ask distance-related questions.