The Upcoming Cloud SSA and Next Generation Hybrid Search: Initial Thoughts
At the Microsoft Ignite Conference last week, we got our first look at the upcoming SharePoint Cloud Search Service Application (Cloud SSA), which enables on premise environments to push content to a Search Index running in SharePoint Online (SPO). And with it coming to SharePoint 2013 by the end of the year (and to SharePoint 2016 upon its release), we'll be able to leverage this sooner than we thought, too.
What's in a name?
So here's the first dilemma… nomenclature. When anyone asks me about Hybrid Search, I now have to first ask questions to clarify what they mean. Hybrid Search as we've known until now heavily relates to remote query federation – e.g. how to query a remote SharePoint SSA and locally render those results. This workload and functionality will still play a role in the world with a Cloud SSA (although the use case will be slightly different and less commonly used). So, going forward, I will now differentiate these as (and to knowledge, these are not official terminology):
- "Hybrid Search" when talking the next generation hybrid empowered by the Cloud SSA
- If I'm directly comparing the new/previous hybrid models in the same sentence and need to draw a very clear distinction, I'll try to more explicitly refer to "[NextGen] Hybrid Search")
- And Hybrid-Search-as-we-knew-up-to-Ignite (which relates more to the query federation aspects) more simply as "Classic Hybrid Search"
With the Cloud SSA, Hybrid Search evolves by adding the new dimension of crawling. I also expect this to shift many of the Search-related workloads and use cases further into SPO where you can take advantage of enormous scale (without having to manage that infrastructure) and new functionality like Delve for all content.
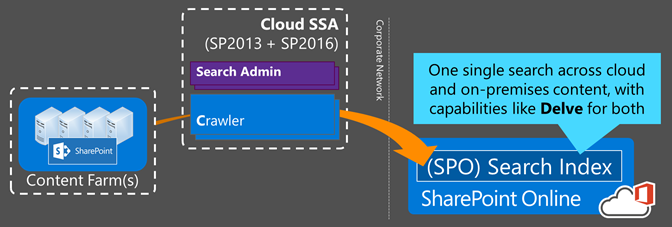
So, to better explain, let's first take a look back at how we got here.
Classic Hybrid Search was a good step...
A few years back, we began learning about Hybrid Search between SP2013 and SPO. Simplistically speaking, that "hybrid" is largely just query federation (plus lots of goodness involving OAuth trusts, Azure ACS, DirSync, UPA, and reverse proxy). In this classic form, a single user query would then perform two separate queries under the covers to each disparate Search Index – one to an on premise SSA and a second to SPO.
We illustrated this flow in our recent session at Microsoft Ignite (BRK3176) "Effective Search Deployment"
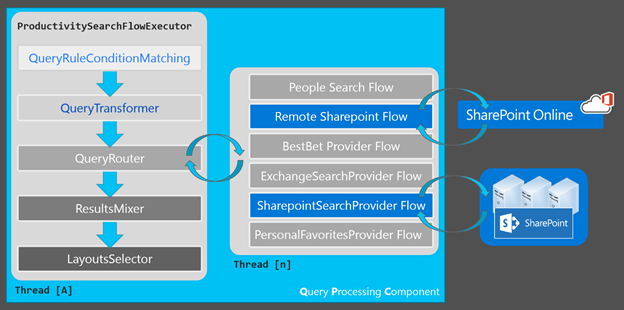
With two separate indices, there is no way to correlate the calculated rank score for results across the two systems and thus no way to reliably interleave the two result sets into a single set of rendered results for the user... hence, Result Sets, which provide a bit of a best effort to mix the results together.
Over time, we began seeing admins evolve away from Result Sets and instead using separate Search Verticals, such as one named "On Premise" (or "Intranet") and another "Office365" (or "Cloud"). This evolution became more popular because Result Sets are typically only configured to show three to five results and refinement navigation is much more meaningful when used with the entire set of results.
Although much better than having two different sites for searching content, users still needed to know where to Search with separate verticals, meaning, they somewhat needed to be aware of where the content lived. Ideally, the location of content would be abstracted. For example, when searching in Bing, you generally don't know or care where the content originated and your users shouldn't either (understandably, internet search is much different animal than intranet search, but the analogy here still applies).
Before going on, I want to reiterate that I am not part of the Product Group and that I have no decision making authority over any of this. Although I am an employee of Microsoft, do not consider this official in any way and please treat these writings as my own observations made on publically announced information combined with experience with SharePoint 2013… |
…but the Cloud SSA will change the game (and will be cloud first)
As stated above, I expect this to shift many of the Search-related workloads and use cases further into SPO. I also expect this to change User behaviors and in doing so, change our point of reference altogether when talking Hybrid Search to be "cloud first".
For example, in the classic implementations, the point of hybrid seemed to be "how can I include queries from SPO in my search results from on prem?" implicitly making the on premise environment the primary actor. With the Cloud SSA, that seems to flip – particularly when talking the role of Search – where the scenario seems much more cloud-centric (or at least, could greatly minimizes the resources tied to the on prem piece).
The once significant roles to architect and manage operational resources for an on premise Search implementation get absorbed into SPO. This should free up organizations to focus resources beyond simply managing the infrastructure and instead looking deeper into aspects such as UI/UX and relevancy (e.g. query rule, result sources, etc) …all of which will be managed in SPO.
End users will greatly benefit, too. As Jeff Fried stated in this insightful piece on the Future of SharePoint Search:
Search is the primary integration point for hybrid today because it separates the user experience from the location of the content - you shouldn't care where content lives as long as you can find it quickly and work with it easily.
…we began to see this emerge with Classic Hybrid scenarios, but with the limitations described earlier.
The Cloud SSA – with one Search index providing one complete set of results with all the new bells and whistles that come to SPO first (e.g. Delve) – moves us MUCH, MUCH closer to achieving that content abstraction layer that acts as a single point of integration …and that gets updated (without interruption) on a much faster interval than possible in an on premise deployment ...and with the benefits inherit to cloud economics and scale.
What's not to love here?
On the Architecture, Operations, and Administration front
The number of servers to deploy, manage, and monitor should drop substantially with the Cloud SSA – by 65% in the very realistic example provided by Kathrine/Manas in their session. But to take that a step further, the Cloud SSA only has Crawl and Admin Components (plus Crawl Store and Admin DBs), meaning you DON'T have Content Processing Components, Analytics Processing Components, Index Components, or Query Processing Components.
To highlight why that matters, just look at this cheat sheet we used in our session to describe the performance impact of the various components in a SharePoint 2013 farm…
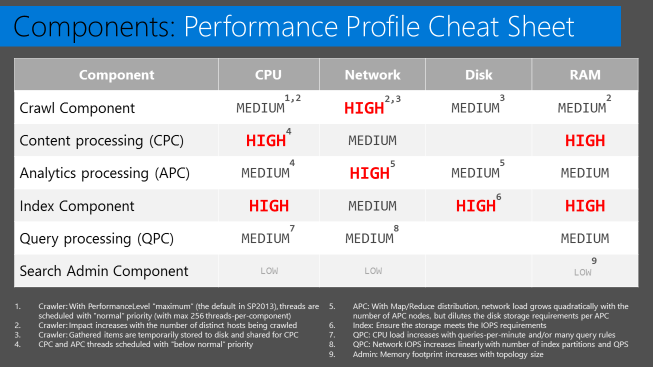
…that's a lot of resources – CPU, Disk, Network, and RAM to reclaim and a much simplified system to monitor/troubleshoot (anecdotally, our session "How to manage and troubleshoot Search" is still the second highest rated session from SPC14 tagged SharePoint 2013, which should speak to the complexities of troubleshooting it).
Don't get me wrong, I still expect problems to occur and support tickets to get created. But the logic to orchestrate crawls, which the Crawl Component manages, appears to be unchanged from SharePoint 2013 and the overall flow for crawling a specific item is still very similar, too. Because the gathering and orchestration logic is largely the same, I expect many of the same problems, which typically fall into one the following categories:
- Content access issues including authentication, permissions, and/or networking/proxy issues
- Overwhelmed content repositories that cannot handle the browsing load from the crawler
- Crawl thread starvation typically caused by crawling too many hosts concurrently or crawling slow repositories that prevent crawl threads from being released in a timely fashion
- I'm currently working on PowerShell to proactively spot these
- Stuck crawls usually related to an underlying database issue and/or synchronization failures in the SharePoint Server Search Service Instance
…but these are all foreseeable and we have built deep skill sets for monitoring/troubleshooting/isolating these types of issues.
The key difference for crawl flow in the Cloud SSA occurs where the feeding stage existed in SharePoint 2013. In the slide showing the logical architecture for crawling with Cloud SSA, we see "crawling and parsing" as steps 1 and 2. The "crawling" part here refers to the orchestration and gathering pieces described above. In other words, "crawling" here could have easily been labeled "gathering" instead. The "parsing" stage in the Crawl Component, however, is new…
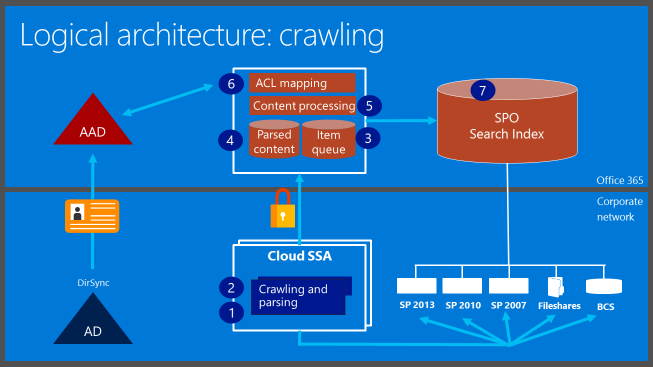
Some Speculation on the Crawl Component in the Cloud SSA
From the BRK3134, we know iFilters will run at the Crawl Component (which is different than SP2013) and that the Cloud SSA will send parsed content to the "cloud" in batches. We also heard that beyond a new "ACL mapping" stage, the remainder of content processing is largely the same that we had in SP2013. And, in the Q&A after the session, I heard the Cloud SSA and a [Classic] SSA would be dedicated to their respective workloads. In other words, if you wanted to push content to the cloud and also implement a local index, you would have to configure two separate SSAs… one Cloud SSA and one Classic SSA.
I'll dig into the gritty details in a future post once I get my hands on this to test. In meantime, given the puzzle pieces we now have, this sounds like the re-ordering of a few key stages to implement the core of this change. If so, that is a good thing because our learning curve should be much flatter.
In SharePoint 2013, the Crawl Component's "Content Plugin" logically submits gathered items ("feeding") to the Content Processing Components in batches. I use the words "logically submits" because the item being submitted is actually just a structured payload will all the crawled proprieties and values received from the Protocol Handler along with a special path property with a UNC path to the gathered blob now sitting in the Crawl Component's temporary storage. In the Content Processing Component, the "DocParsing" stage (the first stage in the insert/update crawl processing flow) uses the UNC path to reach back to the Crawl Component and parse the item.
In the Cloud SSA, I highly suspect the [Crawl Component's] Content Plugin from SP2013 got replaced with a new plugin that would handle parsing and feeding [parsed items] to the "cloud", which would explain why separate SSAs would be required for the different workloads (e.g. different plugins feeding to either the "cloud" or to on premise). The parsing logic for the Crawl Component described in the BRK3134 session sounds a whole lot like the "DocParsing" stage from SP2013, so I suspect that it essentially got refactored from the Content Processing Component and injected into the Crawl Component. If so, we should expect to see the CPU requirements for the crawl component increase.
Likewise, the batching logic – also described in the BRK3134 session – sounds VERY similar to the batching logic we already have in SP2013. However, I see two key differences. First, the Cloud SSA Crawl Component encrypts the parsed content being submitted to the "cloud". Second, by only sending parsed content to the "cloud", the size of each processed item should be substantially smaller than the actual content that was crawled (whereas in SP2013, the entire item goes across the wire between the Crawl Component and the Content Processing Component).
And as we wrap, I just want to reiterate:
Treat these speculations solely as my own and do not consider this official documentation in any way .
In Summary…
With any new technology, I expect hiccups along the way particularly during the role out and when people find ways to do very unexpected things (do a tour in the support trenches and you will understand what I mean). But the foundation has evolved and been hardened by lessons learned from many on premise environments and very large scale SPO implementations. I am optimistically confident that the problems we face are both largely foreseeable/manageable and that the mammoth benefits will easily supersede any bumps in the learning curve.
I will be interested to see how they implement the tools to monitor/troubleshoot (being said, I was happy to see the CrawlLogs still existing in the on premise environments as seen in the demos) and how signals from on premise will get fed into Delve (and, in case you've read somewhere else, Delve is only going to exist in SPO, but also applies to the on premise content getting pushed to the SPO Index). And I am curious how they'll deter someone from trying to crawl the internet.
In the short term, I am truly excited to get my hands on the Cloud SSA to test and explore. But in the long term, I am even more excited about the paradigm shift this will bring and see how it moves our focus on how to innovate with Search rather than simply managing it.
…times like these make it exciting to work for Microsoft.