SP2013 Crawling *Explained: Starting the Crawl Deep Dive (Part 2)
With VerboseEx logging enabled, the crawl of a single item (or interchangeably, a "document") can generate more than 6000 ULS events, at times making troubleshooting a particular document analogous to finding the needle in the haystack. In this series of posts, I first described the high level orchestration for crawling a document. In this and upcoming posts, I'll again show the same overall flow, but this time using key ULS events to illustrate a deep dive through an expected path when crawling an item.
Orchestrating the Crawl of an Item
During the crawl of a Content Source, the Crawl Component manages the flow of items – from gathering from the content repository, content submission (aka: "feeding") to the Content Processing Components, and callbacks handling for the overall status of a given item. The Crawl Component also maintains the Search Crawl Store DB as the central repository for all crawled documents and tracks the lifecycle for each Document (e.g. the access URL for each item that has been crawled, the last crawl time and crawl status of each item [success, error, warning], and deletion status) in the MSSCrawlUrl table, with each item identified by its DocID.
In this scenario, I first performed a full crawl, added a new document (OfficeSpace.docx), increased logging to VerboseEx, and then captured ULS while performing an incremental crawl. From the Crawl Log, we can see this item has a DocID 1047491, which becomes a valuable data point as we progress through these ULS events. 
Starting the Incremental Crawl …a view from ULS
First, we start with a pop quiz: Where can I find the admin component in SharePoint 2013?
Kudos if you answered with the question "which one?" because there are several possible answers here ranging from one or more "Admin Components" in the topology (which, to me, would be more accurately named the Juno and Index Admin Component), timer jobs (e.g. the "Application Server Administration Services Timer Job"), service applications (e.g. the "SharePoint Web Admin Service Application", which is tightly coupled with the "Legacy Admin Component"), stored procedures in the Search Admin DB (e.g. proc_MSS_CrawlAdmin), and several other administrative threads keeping the Search system running (e.g. the Generation Controller, the Cluster Manager, the System Manager, and so on) that could all arguably be considered an "admin" component.
In this case, when the user goes to Central Admin -> Search Administration -> Content Sources and starts the crawl, the web parts in this page interface with the SharePoint Web Admin Service Application (SearchAdmin.svc), which then utilizes the SearchApi (Object Model) under the covers. This SearchAdmin.svc runs on the server with the Legacy Admin component ( $SSA.AdminComponent).
| Although a bit of a tangent, it's worth noting that the Legacy Admin (which runs in the context of mssearch.exe) is different than the "Admin Component" displayed in the Search Topology (which runs in the context of noderunner.exe). Being said, the Search system does attempt to keep the Legacy Admin running on the same server as the Primary Admin Component in the Search Topology – the ULS message "synchronizing legacy admin" provides a clue to this behavior. This legacy component performs some internal functionality largely related to SSA-level objects (e.g. process Index reset) and content sources (e.g. start, pause/resume, and stop crawls), but is designed to be hidden from the world (e.g. public facing properties/methods are now obsolete in SP2013 and thus removed from MSDN documentation as such). |
In somewhat simplified terms, get the ULS logs from the server $SSA.AdminComponent.ServerName, and look for the Verbose message such as the following showing the start of the crawl:
02/27/2015 18:11:06.11 mssearch.exe (0x133C) 0x2E4C
SharePoint Server Search Crawler:Gatherer Plugin e5ho Verbose
**** CGatherer::SQLExecuteCrawlAction CS_ID 2
Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a
ExecuteAction ACTION_ADMIN_START_CRAWL_REQUESTED
This one log message is fairly informative…
First, this reinforces the notion of the crawl start goes through the Legacy Admin – from this message, compare the reference to "Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a" with the output of following PowerShell:
$SSA.AdminComponent | SELECT Name, ServerName, Initialized, Server
Name : 56bc7805-d4b1-4c29-8471-fbe0b39bf14a
ServerName : WAITER1
Initialized : True
Server : SearchServiceInstance
The "process" column in this ULS event also confirms that the Legacy Admin runs within mssearch.exe, which corresponds to the "SearchServiceInstance" in the PowerShell output above (this should also dispel any notion that mssearch.exe only runs the Crawl Component ...on this Waiter1 server, I have no Crawl Component).
Also from this ULS event, we can see the content source to which the request applies to Content Source ID 2. By hovering over a content source link in Central Admin, you can quickly verify its ID from the URL as seen below (e.g. notice the cid=2 in the highlighted query string below)
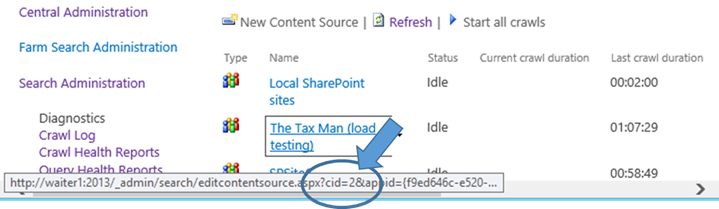
And finally, we see the action being requested (ACTION_ADMIN_START_CRAWL_REQUESTED) from the Search Admin database – specifically, from the stored procedure proc_MSS_CrawlAdmin, which then creates a new row in the MSSCrawlHistory.
You may also notice a message such as the following appear in the logs of Central Admin…
02/27/2015 18:11:06.11 w3wp.exe (0x2144) 0x1EFC
SharePoint Server Search Admin Audit 97 Information An incremental crawl was started on 'The Tax Man (load testing)' by CHOTCHKIES\bspender
I've seen cases where this got reported (not by the Search system, but by Central Admin) even when a failure prevented the actual crawl start request (ACTION_ADMIN_START_CRAWL_REQUESTED) failed. Therefore, treat this only as an informational message… not an authoritative marker that the crawl has started.
Orchestration by the Master
From here with the new crawl created (e.g. new row in MSSCrawlHistory), one of the Crawl Components is designated with a "master" role and takes over the orchestration of the crawl for this content source. As such, this "master" component is sometimes called the Gatherer Admin.
To identify the master Crawl Component, run the following SQL query from the Search Admin DB:
SELECT CrawlComponentNumber, ServerName FROM [ctk_SSA].[dbo].[MSSCrawlComponents] WHERE Master = 1
CrawlComponentNumber ServerName
1 WAITER2
Opening ULS on the server with the "master" crawl component, look for the Verbose message such as the following showing this Crawl Component step through the initialization process:
02/27/2015 18:11:06.06 mssearch.exe (0x17F8) 0x1180 SharePoint Server Search Crawler:Gatherer Plugin e5hp Verbose
**** CGatherer::SQLExecuteCrawlAction Crawl 228
Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1 ExecuteAction ACTION_MASTER_CRAWL_STARTING1
From this message, notice we also have a specific CrawlID (Crawl 228), which is the identifying column in the MSSCrawlHistory table. This Craw History table gives us vital information such as the Crawl Type (e.g. full [1], incremental [2], or delete [6] crawl), the status/substatus (which gives you the *real crawl state), the request time (which is typically the time Legacy Admin requested the crawl to start, but it may also be updated when attempting to pause or stop a crawl), the start time (the point at which the crawl moves from "starting" to "started"), and the end time.
Before diving into the next few messages, I want to first discuss the conceptual model of Crawl state management as a finite state machine. On Wikipedia, a finite state machine is described as "an abstract machine that can be in one of a finite number of states. The machine is in only one state at a time; the state it is in at any given time is called the current state. It can change from one state to another when initiated by a triggering event or condition; this is called a transition". Similarly, the SharePoint Crawl is stateful with transitional "ing" states (e.g. Starting, Completing, Stopping, and Pausing) and corresponding states at rest (e.g. Started, Completed, Stopped, Paused).
The overall Crawl state (such as Starting or Started [crawling]) is managed by the proc_MSS_CrawlAdmin and defined by the combination of Status/SubStatus values in the MSSCrawlHistory table as well as the state of any given Crawl Component for a particular crawl (tracked in the MSSCrawlComponentsState table). The crawl components continually synchronize with the states in the Search Admin DB and the number of items pending processing from the Crawl Store databases. The Crawl Components interact with the Search Admin DB by submitting "CrawlAction" codes (such as ACTION_ADMIN_START_CRAWL_REQUESTED and ACTION_MASTER_CRAWL_STARTING1 seen above… and more to come below).
After this point…
02/27/2015 18:11:06.14 mssearch.exe (0x17F8) 0x1180
SharePoint Server Search Crawler:Gatherer Plugin e5ek Verbose CGatherer::ProcessStartCrawlRequest 228 Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1 NewStatus = CRAWL_STATUS_STARTING, NewSubStatus = CRAWL_SUBSTATUS_ADD_SAS /*Add Start Addresses*/
…the crawl will then be in the Starting state (i.e. NewStatus = CRAWL_STATUS_STARTING) with the first sub-step of this phase involving the retrieval of the start addresses for this content source from the registry and adding them into the crawl queue (i.e. NewSubStatus = CRAWL_SUBSTATUS_ADD_SAS).
02/27/2015 18:11:06.15 mssearch.exe (0x17F8) 0x1180 SharePoint Server Search Crawler:Gatherer Plugin dw3a VerboseEx
CGatherAddLink::InsertLink: InsertRow on TempTable succeeded,
URL https://taxes.chotchkies.lab, CrawlID 228, SourceDocID -1
Troubleshooting tip: This is a fairly straightforward step so if things hang up here, I typically start looking for an underlying database issue such as a full transaction log.
From here, the flow slightly (and temporarily) diverges for Incremental versus Full crawls…
Incremental Crawls
Rather than processing everything, an Incremental crawl only processes the changed items including those that failed in the last crawl – the initial work to identify and seed the roots of processing begins here (think of this as an extension to the previous step of loading start addresses)…
02/27/2015 18:11:06.18 mssearch.exe (0x17F8) 0x11E0
SharePoint Server Search Crawler:Gatherer Plugin e5hw Verbose
**** CGatherer::SQLExecuteCrawlAction Crawl 228 Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1 ExecuteAction ACTION_MASTER_SEED_INC_CRAWL
The crawl then moves into the second sub-step of the Starting phase…
02/27/2015 18:11:08.05 mssearch.exe (0x17F8) 0x1180 SharePoint Server Search Crawler:Gatherer Plugin e5hq Verbose
**** CGatherer::SQLExecuteCrawlAction Crawl 228 Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1
ExecuteAction ACTION_MASTER_CRAWL_STARTING2
Full Crawls
In this case, there would be no additional steps needed to progress to the second sub-step of the Starting phase, which is waiting for all Crawl Components to join this crawl…
SharePoint Server Search Crawler:Gatherer Plugin e5c1 Verbose CGatherer::PingCrawl 228 Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1
NewStatus = CRAWL_STATUS_ STARTING,
NewSubStatus = CRAWL_SUBSTATUS_WAIT_CC
Although you won't explicitly see this event e5c1 when going down the Incremental crawl path, the ACTION_MASTER_CRAWL_STARTING2 is functionally equivalent in that the sub-status also gets updated to Waiting on Crawl Components. Thus, these two messages can be treated as interchangeable.
Enter the Crawl Component(s)
Up to this point, the steps have followed the actions of the "master" Crawl Component, but now we'll begin to invite all other Crawl Components to join this crawl. More specifically, the "master" Crawl Component actually has two logical roles running in separate contexts – the Gatherer Admin (described above) and that as a Gatherer, which handles the orchestration of crawling specific items (e.g. pulling a batch from the crawl queue, retrieving it from the content repository, feeding it to the CPC for processing, and handling the callbacks from the CPC). All of the non-master Crawl Components only perform the Gatherer role.
Earlier, I noted that the Crawl state is managed as a finite state machine. That same concept applies here, too in that the Gatherer Admin communicates with each of the Gatherer roles through "tasks" created in the Search Admin DB (such as various Status/SubStatus combinations or Request values in the MSSCrawlHistory) and will continually "ping" the Search Admin DB to check the status of the task:
02/27/2015 18:11:08.05 mssearch.exe (0x17F8) 0x1180 SharePoint Server Search Crawler:Gatherer Plugin e5bn Verbose
CGatherer::PingCrawl 228, component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1
In general, when transitioning a Crawl from one state to another (e.g. from Starting to Started [Crawling] to Completing to Completed), the overall Crawl will first move to a transitional state (e.g. Starting) and then wait for the Crawl Components to move to the new desired state first. Once the components have all moved to the new desired state (in this scenario, the crawl is waiting for the Components to move to Started) , then the overall Crawl state can follow. In other words, once the components have moved to Started, then the crawl can then also move to Started.
As seen in the messages above, the Gatherer Admin had recently asked all of the Gatherers to join this crawl 228 (e.g. CRAWL_SUBSTATUS_WAIT_CC) and is now repeatedly firing the following action until all components successfully join…
02/27/2015 18:11:10.05 mssearch.exe (0x17F8) 0x1180
SharePoint Server Search Crawler:Gatherer Plugin e5hr Verbose
**** CGatherer::SQLExecuteCrawlAction Crawl 228
Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1
ExecuteAction ACTION_MASTER_QUERY_CRAWL_STARTED
…internally in the proc_MSS_CrawlAdmin, a query is made to determine if the MSSCrawlComponentsState table has any Crawl Components for this crawl 228 that have not reported as started (e.g. CRAWL_STATUS_STARTED). If so, then the Gatherer Admin will loop and continue to fire the same action above …if there is busted crawl component that cannot start for whatever reason, this will essentially turn into an infinite loop and the crawl will appear stuck in starting (…completing …pausing …stopping …whatever)
Troubleshooting tip: If things hang up here, the crawl is waiting for a particular Crawl Component. Look in the MSSCrawlComponentsState table for rows matching this Crawl ID and determine which component has not yet moved into Started [4] state and start troubleshooting that component.
Debugging hint: The logic in this stored procedure is visible to the public… from a test system, try opening it up and searching for these actions J
Whereas the Gatherer Admin drives tasks, the Gatherer(s) will actively monitor for these tasks (e.g. triggers) by loading the status from the Search Admin DB and then react accordingly. When joining the crawl, each Crawl Component in the SSA will each individually report via the following action:
02/27/2015 18:11:10.05 mssearch.exe (0x17F8) 0x22FC
SharePoint Server Search Crawler:Gatherer Plugin dww2 Medium processing status change (1) NSC_START,
(56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1, Portal_Content)
thread id 0x22fc
02/27/2015 18:11:10.05 mssearch.exe (0x17F8) 0x22FC
SharePoint Server Search Crawler:Gatherer Plugin e5ht Verbose
**** CGatherer::SQLExecuteCrawlAction Crawl 228
Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1
ExecuteAction ACTION_COMPONENT_CRAWL_START_DONE
…which updates the Status of this component in the MSSCrawlComponentsState table to Started [4].
Troubleshooting tip: In all but one of these previous messages, the steps were performed by the Gatherer Admin and logged by the same thread id 0x1180. Notice however that these two messages above – performed by the Gatherer role – got logged by thread id 0x22FC. Filtering by thread id can sometimes help reduce the noise when attempting to follow one role or the other.
This time, when the Gatherer Admin fires the ACTION_MASTER_QUERY_CRAWL_STARTED…
02/27/2015 18:11:12.05 mssearch.exe (0x17F8) 0x1180 SharePoint Server Search Crawler:Gatherer Plugin e5hr Verbose
**** CGatherer::SQLExecuteCrawlAction Crawl 228 Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1
ExecuteAction ACTION_MASTER_QUERY_CRAWL_STARTED
…the query is satisfied and can then progress the crawl from Starting to Started
02/27/2015 18:11:12.05 mssearch.exe (0x17F8) 0x1180
SharePoint Server Search Crawler:Gatherer Plugin e5c3 Verbose
CGatherer::PingCrawl 228
Component 56bc7805-d4b1-4c29-8471-fbe0b39bf14a-crawl-1
NewStatus = CRAWL_STATUS_STARTED, NewSubStatus = CRAWL_SUBSTATUS_CRAWLING
Tee Up the Real Work…
This becomes the point where we shift context. Up to now, the concept of "crawling" was in regards to a content source level operation (e.g. starting the crawl on content source id 2). From here, the "crawling" typically refers to an action done on a specific item (e.g. crawling item https://foo) …but we will be covering that aspect of crawling in future posts. In the meantime, I leave you with this cliff-hanger lead into the next post.
With the crawl now Started (Central Admin displays this as "Crawling"), the Gatherer will spawn another thread to start pulling items from the crawl queue (e.g. the start addresses and any applicable links from the ACTION_MASTER_SEED_INC_CRAWL step), which begins a "transaction" for these items:
02/27/2015 18:11:12.17 mssearch.exe (0x17F8) 0x2620
SharePoint Server Search Crawler:Gatherer Plugin e5jl Verbose
gatherer SQL thread 0x2620 started
02/27/2015 18:11:12.17 mssearch.exe (0x17F8) 0x2620
SharePoint Server Search Crawler:Gatherer Plugin e5jp Verbose
Gatherer LoadTransactions thread running, Crawl 228
02/27/2015 18:11:12.17 mssearch.exe (0x17F8) 0x2620
SharePoint Server Search Crawler:Gatherer Plugin e5e7 VerboseEx
CCGatherer::LoadTransactionsFromCrawl, Application=SSA,
Project=Portal_Content , crawlID=228,
docID=1500, URL=https://taxes.chotchkies.lab,
dwTransactionLoaded=1
02/27/2015 18:11:12.17 mssearch.exe (0x17F8) 0x2620
SharePoint Server Search Crawler:Gatherer Plugin e5e7 VerboseEx CCGatherer::LoadTransactionsFromCrawl, Application=SSA,
Project=Portal_Content, crawlID=228,
docID=1501, URL=sts4://taxes.chotchkies.lab,
dwTransactionLoaded=2
02/27/2015 18:11:12.17 mssearch.exe (0x17F8) 0x2620
SharePoint Server Search Crawler:Gatherer Plugin e5e7 VerboseEx
CCGatherer::LoadTransactionsFromCrawl, Application=SSA,
Project=Portal_Content , crawlID=228,
docID=1502, URL=topicpages://taxes.chotchkies.lab,
dwTransactionLoaded=3
02/27/2015 18:11:12.17 mssearch.exe (0x17F8) 0x2620
SharePoint Server Search Crawler:Gatherer Plugin e5e7 VerboseEx
CCGatherer::LoadTransactionsFromCrawl, Application=SSA,
Project=Portal_Content, crawlID=228,
docID=1503, URL=sts4://taxes.chotchkies.lab/contentdbid={4bb174f0-b860-4848-9b06-b1b3c0a0b4d0},
dwTransactionLoaded=4
…and so on.
From here, the items are requested/retrieved from the applicable content repository and once retrieved, submitted to the Content Processing Component. Once processed, the Crawl Component will receive a callback from the CPC allowing the transaction to complete.
In coming posts: Continuing to peel back the onion…
So far in this series, we covered:
- A high-level view to orchestrating the crawl
- A deep dive look at starting the crawl /* this post */
- Enumeration/Discovery
- Concepts
- Illustrating through ULS /* next in the series */
- Simulating with PowerShell
And in coming posts, we will then deep dive into each of the following areas in separate posts:
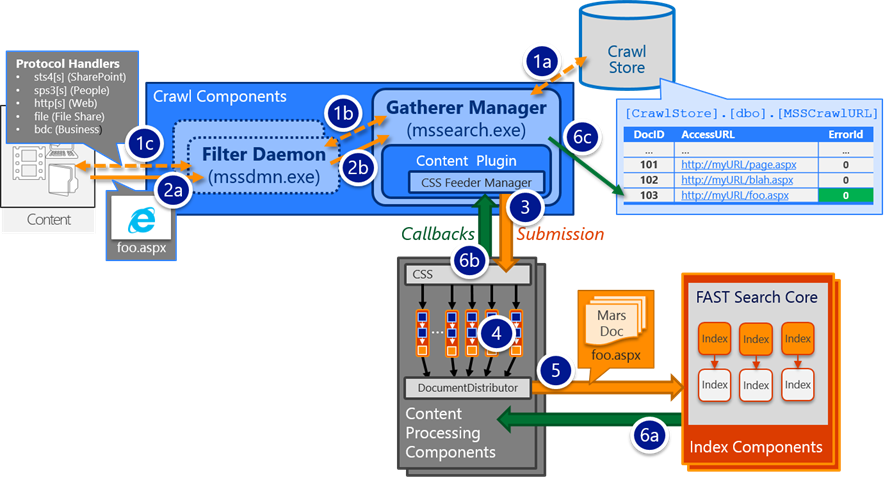
- Enumeration/Discovery: The process where the Crawl Component:
- Asks for the links to items from the content repository (e.g. "what items do you have within this start address?")
- And then stores these emitted/discovered links in the "crawl queue" (the MSSCrawlQueue table in the Crawl Store Database)
- Gathering: The process of the Crawl Component retrieving [think: downloading] the enumerated items (e.g. using links from the crawl queue)
- Each Crawl Component independently earmarks a small sub-set of items from the MSSCrawlQueue to be gathered/processed; once earmarked, the item is considered part of a "search transaction"
- Feeding: The process of the Crawl Component submitting the gathered items to the Content Processing Component(s)
- Processing: The process of the Content Processing Component converting the documents into a serialized object of Managed Properties (aka: "Mars Document")
- The CPC will produce one Mars Document for each item gathered/fed for processing. In other words, the Mars Document is the end product from processing
- Index Submission: The process of submitting the processed document (e.g. the Mars Document) to Index Components where it will be inserted into the index
- Just before submission, a collection of Mars Documents get batched into a "Content Group", which gets submitted to the Index as an atomic operation
- Callback Handling: Following Index Submission:
- A callback message gets returned back to Content Processing Component regarding the status of the Index Submission
- Then, another callback gets returned from the Content Processing Component back to the Crawl Component regarding the status of processing (which implicitly includes the status from Index Submission as well – In other words, processing cannot report success if Index Submission failed)
- Finally, the transaction for the item completes when its status is persisted to the MSSCrawlUrl table and the item gets cleared from the MSSCrawlQueue table
…to be continued