Crushing the 1-million-item-limit myth with .NET Search Connector [BDC]
Ever heard the one about not being able to crawl more than a million or two rows from a single source using SharePoint Business Connectivity Services (BCS)? In this post, I plan to dispel this myth and instead show that large crawls tend to fall over because of overly large enumerations. I then provide a strategy to overcome this and use a proof-of-concept to demonstrate that no specific limitation exists within the BCS/Connector framework that leads to some million item threshold.
In a nutshell, to surpass this perceived limit and crawl tens-of-millions of items (and feasibly more), you have to first change the way your custom Connector enumerates the content – effectively, by creating logical sub-folders (which is different than paging). Understandably, without digging into the details yet, this sounds a LOT like paging… but read on, and I explain why this approach is very different..
As a brief point of clarification… For BCS, the Software boundaries and limits for SharePoint 2013 notes "The default maximum number of items per request the database connector can return is 2,000, and the absolute maximum is 1,000,000". Out of context, this becomes misleading and sometimes referenced as the proof that you can't crawl more than a million items. However, the missing piece is found in the Maximum value column, which states "1,000,000 per request" ...meaning no single request can exceed 1 million rows. |
Before jumping into the details (this section was added after the original publish date)
I want to clarify that this post relates specifically to a custom Connector, which is different than a .NET Assembly Connector. In other words, think of the BCS connectors as a continuum from out-of-the-box (which are relatively easy to configure and use) to fully custom (which are much more complex, but provide flexibility and scale), such as:
- SQL Database Connector
- .NET Assembly Connector
- This is what most people envision when talking about a "custom" connector, but that is technically inaccurate (a .NET Assembly Connector is different than a Custom Connector)
- Custom Connector
- This is a completely custom solution where you must implement the classes for the ILobUri and INamingContainer interfaces (in the .NET Assembly Connector, these are implemented for you)
- The MSDN class documentation for the LobUri Class denotes:
"When using custom search connectors, you must provide implementations of the ILobUri and the INamingContainer interfaces if you make the custom search connector available as a custom content source in SharePoint Server search... The ILobUri interface applies to the URL passed from the search system to the external system object (it defines how to map the content item URL passed from the search system to the external system object), while the INamingContainer interface applies to the URL passed from the external system object to the search system (it defines how to map the external item to the URL used by the search system)"
Although, the key focus of this post is to describe the overall logic behind this approach (rather than any specific code level implementations), I should have been more clear by reiterating that the proof-of-concept discussed in this blog was a Custom Connector and the lynch-pin of the solution involves:
- Defining both a "Group" entity (e.g. to create a "folder" like object; this entity is not defined in the .NET Assembly Connector) as well as a "Document" entity for each item (e.g. each row)
- Implementing classes for the ILobUri and INamingContainer interfaces (this enables the connector to understand the difference between a custom URL for an item versus one to a "folder")
Why Paging won't get you over the hump...
Often, I hear paging (also called batching) as the recommended solution for achieving higher counts. Although paging can help (on the SQL side) to a small degree, it won't get you beyond a ~couple million rows because it makes no difference to the Search Connector that's implementing the finder() method. In other words, paging allows SQL to retrieve the rows a batch at a time to fulfill the finder() method's request to enumerate this container object, but the Connector does not emit enumerated links in per-page sized sets. Instead, the Connector returns the enumerated links back to the mssearch.exe process only after enumeration of the entire "container" has completed (think of the start address and folders as a root "container"). This means enumerated items will not land in the MSSCrawlQueue until enumeration completes for the item - in this case, the entire start address, even when paging is implemented.
A quick side bar… The crawler logically works the *same regardless of the type of content it's crawling - web, file shares, SP (there are a few slight *nuances for SP content), etc. The crawler just processes links (aka, "documents"), and it is up to the Connector to understand *how to talk to the content or know *what to do with that link (e.g. enumerate it using the finder() method or retrieve it using the specificFinder() ). Thinking of everything - both containers and items - generically as a "document" and realizing the details to handle this "document" get implemented in the Connector was actually an aha! moment that helped me generalize this problem and better helped get my mind wrapped around it. |
For a table of 10 million items and paging [batching] 5,000 items at a time, SQL would return the batches as expected to the Connector in batches of 5,000 items, but the Connector won't emit these as links back to the crawl queue until all 10 million items get enumerated. This behavior is why we see the memory of the mssdmn.exe significantly bloat during large enumerations as it is holding links to all [n] million children of the container.
Once enumeration of this start address completes (e.g. the call to the finder() for the start address returns), the Connector returns the start address container "document" back to mssearch (specifically, the "Gatherer Manager", which is responsible for inserting the links into the MSSCrawlQueue in the crawl store) – however, this one container "document" happens to contain the entire set of ~[n] million links.
For example, in the screen shot below, we can see several batches of 5,000 items being returned by the Connector, but these items are not being emitted back to the MSSCrawlQueue in the Crawl Store Database. Instead, the Crawl Queue only contains the start address document during the entire enumeration:
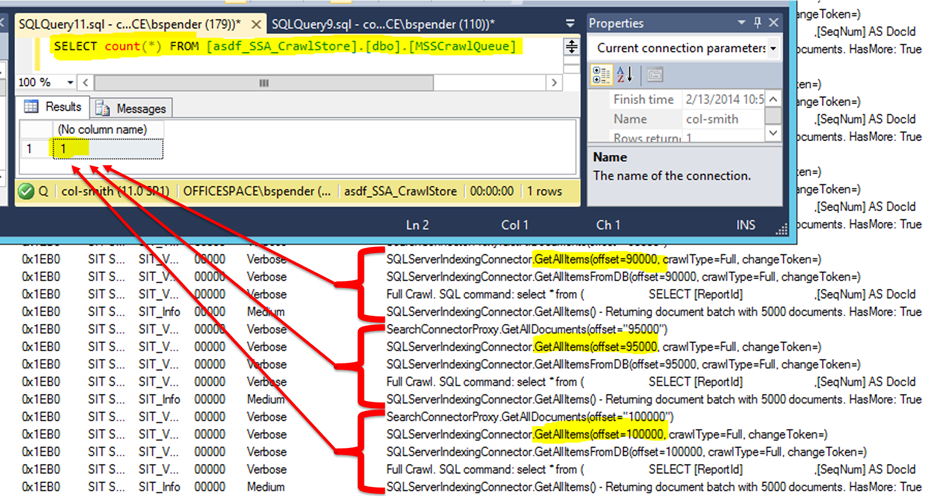
Only much later, when thefinder() eventually returned for the start address document, do we then begin to see ULS messages such below that indicate when the enumerated/emitted URLs are getting pushed into the Crawl Store by the mssearch process (Note: links get bulk uploaded to a TempTable just before getting moved into the Crawl Queue):
mssearch.exe SharePoint Server Search Crawler:Gatherer Plugin dw3a VerboseEx
CGatherAddLink::InsertLink: InsertRow on TempTable succeeded, URL sitsearchconnector://sit/?c=C:/garage/SIT/deploy/adventureworks-cs-config.xml&docid=1,
CrawlID 2655, SourceDocID 3035516
And so on for each emitted URL:
CGatherAddLink::InsertLink: InsertRow on TempTable succeeded,
URL sitsearchconnector://sit/?c=C:/garage/SIT/deploy/adventureworks-cs-config.xml&docid=2,
CrawlID 2655, SourceDocID 3035516
CGatherAddLink::InsertLink: InsertRow on TempTable succeeded,
URL sitsearchconnector://sit/?c=C:/garage/SIT/deploy/adventureworks-cs-config.xml&docid=3,
CrawlID 2655, SourceDocID 3035516
…etc…
CGatherAddLink::InsertLink: InsertRow on TempTable succeeded,
URL sitsearchconnector://sit/?c=C:/garage/SIT/deploy/adventureworks-cs-config.xml&docid=10000000,
CrawlID 2655, SourceDocID 3035516
For what it's worth:
- Ultimately, the memory required to hold ~[n] million links is the typical reason the mssdmn process exceeds memory limits during the enumeration stage (causing it to be terminated by mssearch)
- Similarly, even when memory thresholds are increased for the mssdmn to accommodate ~[n] million links, long running enumerations may also be killed off (and continually, yet unsuccessfully retried) with messages such as "location: search\libs\utill\hangrecoverer.cxx(189) condition: !"Crawl hangs" StackTrace: at Microsoft.Office.Server.Native.dll"
Logically "folder-ize" Content to Break Up Enumeration
Instead of paging (demonstrated above), the key is breaking enumeration into smaller logical buckets (e.g. logical subsets).
Knowing the crawler logically works the same for all types of content, generalize this problem by thinking of a folder (with no sub-folders) containing 20 million files as an analogy for the large table (again, to the crawler, it is logically the same ...the only difference is to which Connector the crawler is talking). Attempting to crawl this giant folder would likely timeout/fail in the same because the enumeration of all 20 million files from one call is too large.
However, if you created 2,000 sub-folders where each sub-folder held on average 10,000 items, then enumeration would first emit the 2,000 links for each of the sub-folders in the root and then separately enumerate each folder. At first glance, this may appear as only a nuanced difference, but the real distinction is that each sub-folder has a distinct URL.
In the first example using paging, the finder() method gets called just once (for the start address). However, in this example with folder/sub-folders, the finder() method gets called 2,001 times - once for the start address (e.g. the root folder) plus another occurrence for each of the sub-folders. This breaks down the overall enumeration into smaller buckets allowing enumeration and the crawl to scale well beyond a couple of million items in the folder.
With an external source like a DB, the solution is the same, but it's not as obvious how to create the sub-folders. For this, you need to identify a non-nullable and non-unique property to "group by" and emit a container link for each of these "group by" values (this is analogous to emitting the links for each of the sub-folders in the previous example). Then, each of these sub-containers can be enumerated separately allowing the crawl to scale for tens-of-millions of rows in a single table (and feasibly, hundreds of millions... but I hesitate to make that blanket statement without seeing the particular case).
From MSDN "Enhancing the BDC model file for Search in SharePoint 2013"… The section Enumeration optimization when crawling external systems For BCS describes the same recommendation with the note: "Do not enumerate more than 100,000 items per call to the external system. Long-running enumerations can cause intermittent interruptions and prevent a crawl from completing. We recommend that your BDC model structures the data into logical folders that can be enumerated individually" |
Implementing the Proof-of-Concept
Below shows my sample table and sample data. In this, my SegmentID column was used as my GroupID where most groups had 25,000 items each (*there are a few groups with less than this) for a total of about 21.5 million rows.

With the out-of-the-box Connector, enumeration was defined to identify ALL rows in this table and then emit a URL for each row back to the MSSCrawlQueue. This was leading to VERY long enumerations taking >60 minutes to complete and causing timeouts/failures (hangrecoverer.cxx(189) condition: !"Crawl hangs"). Even with batching implemented, all of the items were tied to a single item (e.g. the start address URL) and made no impact on how the links were emitted back to the Search Gatherer (e.g. stored in the MSSCrawlQueue) as demonstrated in the first example.
In the proof-of-concept Connector, ~860 links – one for each Group – got emitted back to the MSSCrawlQueue within 30 seconds as seen below:
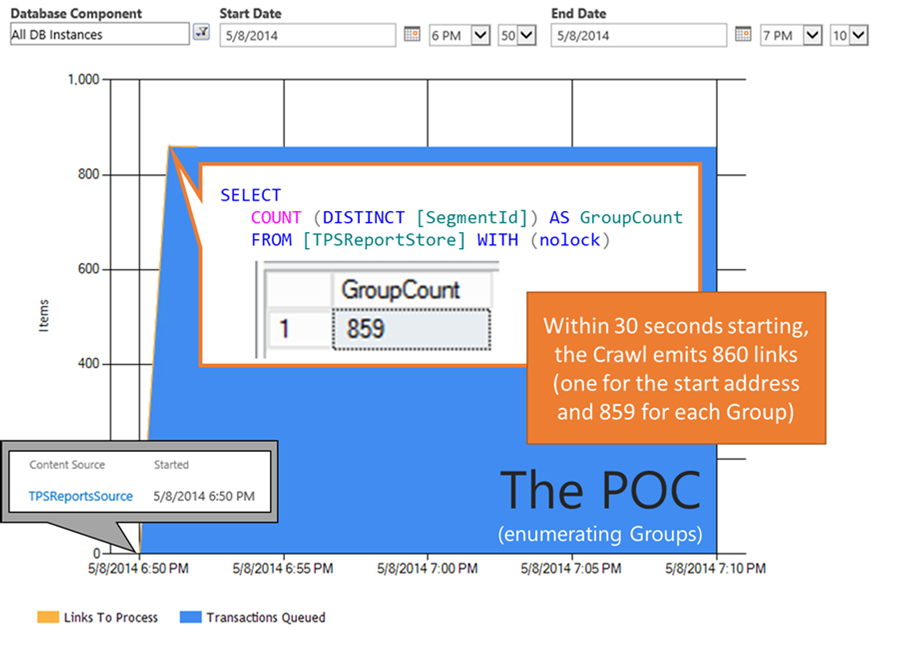
These links to each Group (*folder) items are built using the Segment IDs returned from the following query:
SELECT Distinct [SegmentId] FROM [bpBCSdemo].[dbo].[TPSReportStore]
Assuming the root URL (e.g. the start address for the content source) has a value of "1" for DocID as below, you could use the following SQL to see the Group URLs:
SELECT DocID, ParentDocId, AccessURL
FROM [SSA_CrawlStore].[dbo].[MSSCrawlURL]
WHERE DocId = 1 OR ParentDocID = 1
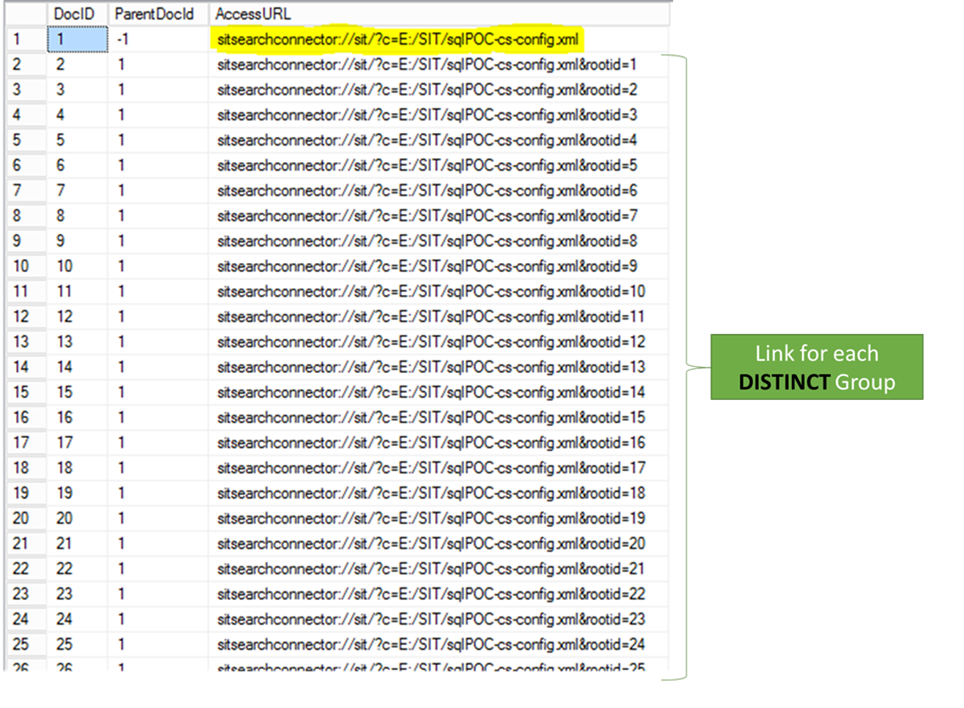
- Note: In most environments, the DocId for the start address in MSSCrawlUrl will likely be something other than "1" unless using a completely new SSA with no other crawled content
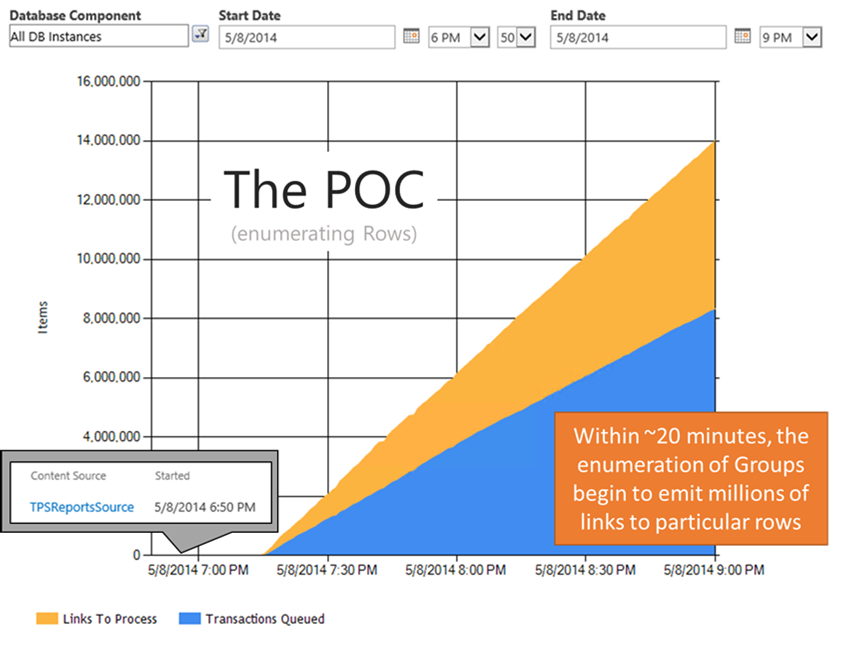
As seen in the graph above, the items in the MSSCrawlQueue plateaus from just after the crawl start until about 7:10p. This occurs because we're waiting for some of the Groups to enumerate (e.g. to identify the items with a particular GroupID). Like before, if these Groups are too large, then we'll once again encounter the same problem we started with (e.g. giant enumerations that eventually timeout). Being said, you still need to be careful picking group identifiers that will keep the groups a reasonable size
- Alternatively, you could also implement an arbitrary grouping based off of a unique numeric key for a row and modulo math such that no group was larger than your divisor.
In my example, where each group had ~25,000 related items, I used the following SQL to enumerate each Group and built an individual item URL for each returned DocID:
SELECT * FROM [bpBCSdemo].[dbo].[TPSReportStore] WHERE SegmentId = 4
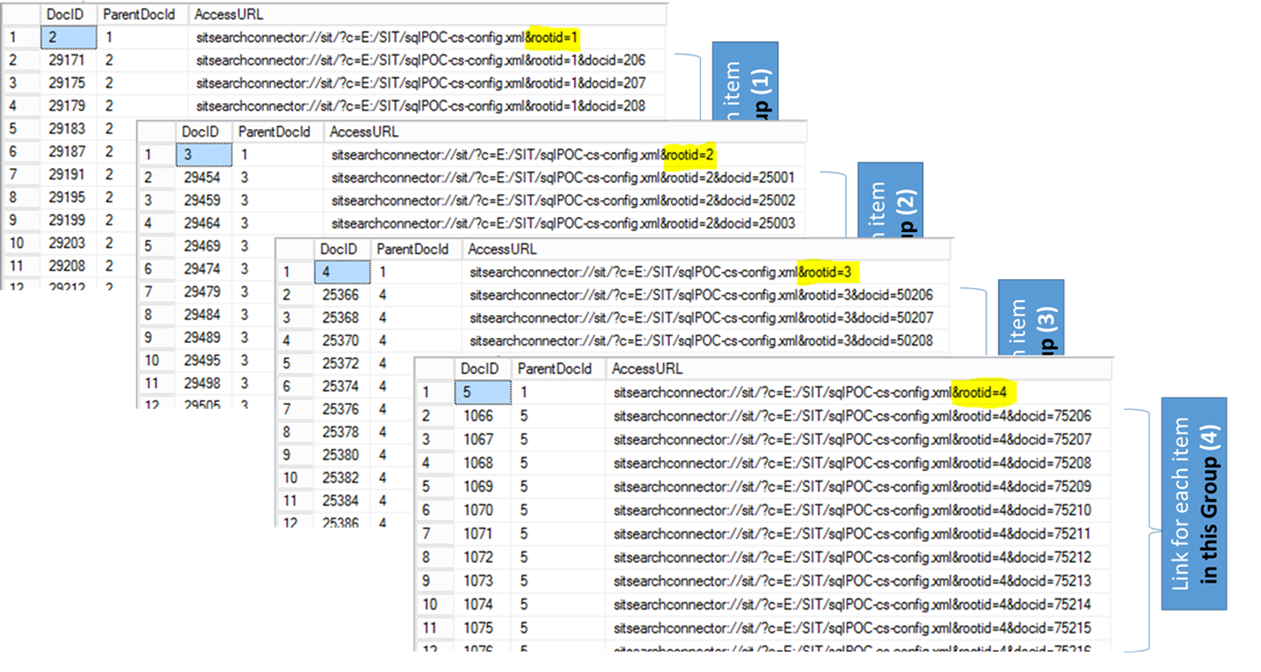
Heads up… It's worth noting that the DocID column in the [SSA_CrawlStore].[dbo].[MSSCrawlURL] table is different than the highlighted "docid" for URLs in the AccessURL column. The DocId in the MSSCrawlURL references an item in Search whereas the "docid" in the URL comes from the underlying content repository and references a particular item in that content repository (e.g. the row id). |
After about 20 minutes into the crawl (*keep in mind my SQL disk architecture isn't ideal with multiple databases and transaction logs all residing on the same disk… being said, not the most ideal response times for these queries), some of the Group enumerations began emitting links into the MSSCrawlQueue as seen below – within 2 hours, there were already more than 14 million items queued up:
And finally, each item is individually gathered with the following query in the specificFinder() :
SELECT [ReportId], [SeqNum], [ReportName], [MemoText], [SegmentId], [SectionId], [ProjectCost] FROM [bpBCSdemo].[dbo].[TPSReportStore] WHERE SeqNum = 128579
------------------------------
At this point with groups being properly enumerated and the MSSCrawlQueue sufficiently being populated, this really becomes the more vanilla issue of scale. For example, can the content source handle the number of requests from the Crawlers? Do we have enough Crawlers (or available gathering threads in the crawler) to sufficiently saturate the requests to the content source (e.g. could we be making more requests to the content source without negatively impacting that content source)? Do we have enough Content Processing Components (or CPU on these components) to process the items that have been gathered (e.g. is there a bottleneck in processing)? Or are we backlogged writing the processed items into the Search Index?
I hope this helps squash the myth and show you really can crawl tens-of-millions of items in a table...