Ask Learn
Preview
Ask Learn is an AI assistant that can answer questions, clarify concepts, and define terms using trusted Microsoft documentation.
Please sign in to use Ask Learn.
Sign inThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Deadlocks reported in the Search databases, particularly the Crawl Store database (which manages the state of each crawled item and by is very I/O intensive), are not abnormal and can occur based on the concurrent and asynchronous nature of the Crawl processing (For additional information on the crawling process, see my previous post here). Below, I provide additional context for Search related deadlocks and considerations for both SharePoint 2013 and 2010... and hopefully explain why you probably don't need to worry about them.
Life of a Crawled Item
Over time, each URL that has been discovered gets tracked in the MSSCrawlUrl table (commonly called the "Links History" table) in the Crawl Store database where each row contains a unique URL, gets identified by the DocID column (in the Crawl Log UI, the ID is labeled as the "Item ID"), and the most recent crawl status for this URL. As the Crawler enumerates the items-to-be-crawled from the content source (e.g. WFE), a row is created for each URL to-be-crawled in the MSSCrawlQueue table (in the same Crawl Store), which uses the corresponding DocID to identify the row in this Crawl Queue (In other words, a URL in the MSSCrawlQueue will have the same DocID as the corresponding URL in the MSSCrawlUrl table).
In SharePoint 2010, URLs were first temporarily placed in the MSSTranTempTable0 table (in the Crawl Store DB) and after some light processing, each URL was then flushed into the MSSCrawlQueue table. However, the MSSTranTempTable0 no longer exists in SharePoint 2013. |
During a crawl, each Crawl Component involved with the crawl will continually pull a sub-set of URLs from the MSSCrawlQueue (e.g. a "batch") using the stored procedure proc_MSS_GetNextCrawlBatch (in the Crawl Store DB) and then fetch each item in this current batch from the WFE (It's worth noting these batches pulled from the MSSCrawlQueue are a different concept than the feeding batches used by the FAST Content Plug-in. In other words, these two uses of "batch" are completely unrelated and an unfortunate use of the same word in different contexts) and attempt to retrieve each item in this set from the WFE (e.g. the gathering process).
As each batch gets pulled, the BatchID column for the related items in the MSSCrawlQueue table will be updated with a new value – if the batch fails (e.g. someone recycled the mssearch.exe process for the crawl component before the batch completes), then all items in this batch will remain in the MSSCrawlQueue where they can be picked up again by a subsequent batch.
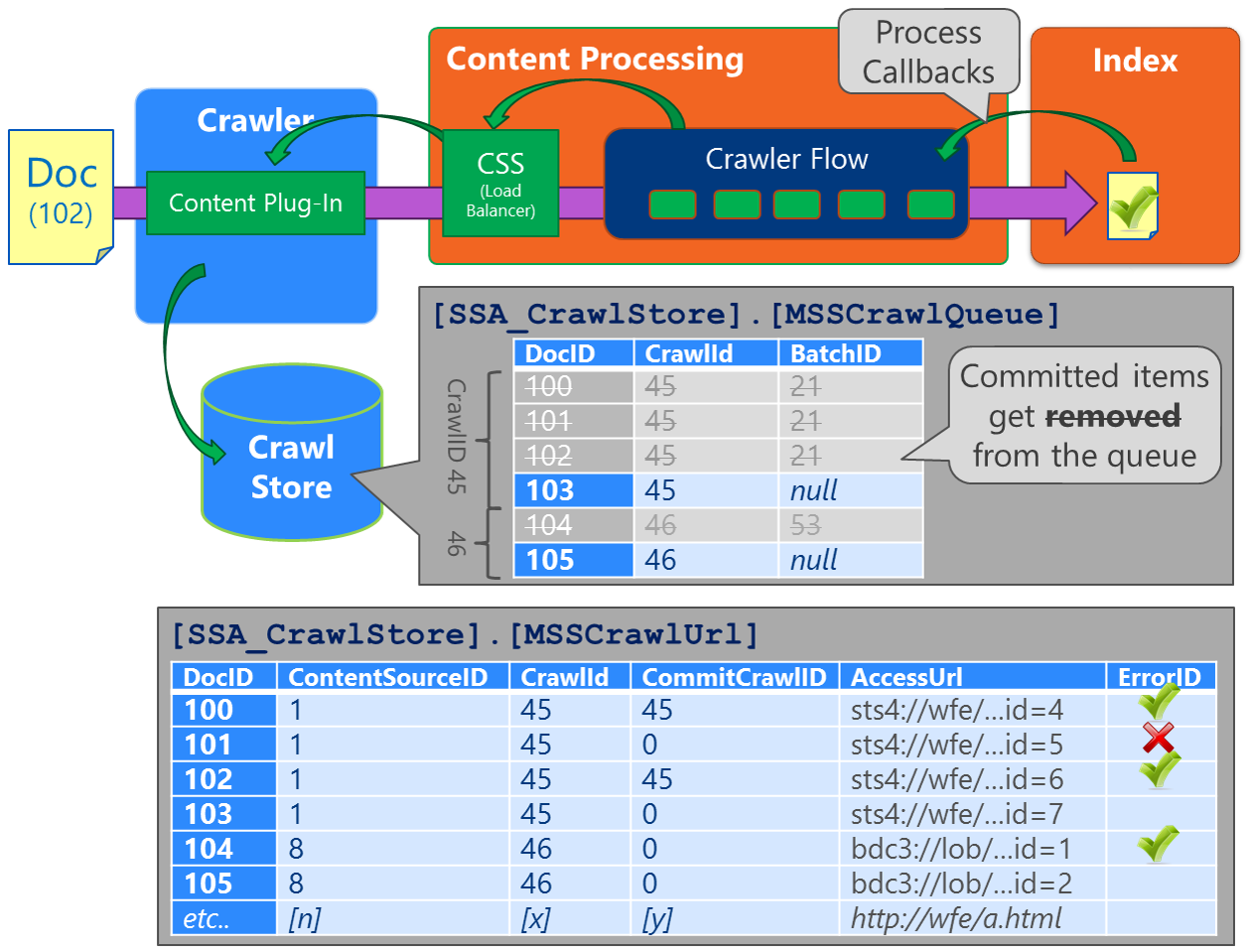
As each URL is retrieved from the WFE, sent to the Content Processing component for processing, and then written to the index, the Content Plug-in (in the Crawl Component) receives a callback that indicates the processing status for each URL. As each callback returns, each URL is updated (in Search-speak: "committed") in the MSSCrawlUrl by the proc_MSS_CommitTransactions stored procedure and because this URL has now been crawled/processed, the applicable row for this URL in the MSSCrawlQueue can now be removed.
When deadlocks occur within Search databases…
Typically, these occur when updating the crawl state for an item in the MSSCrawlUrl table while concurrently deleting the corresponding item from MSSCrawlQueue. However, Search is resilient to deadlocks (particularly in the Crawl Store) and handles scenarios where processes are chosen as the deadlock victim – the item will just remain in the MSSCrawlQueue and be picked up again by a subsequent batch. Being said, if you experience tens-of-thousands deadlocks per day, this is probably worth investigating – if you only experience ten per day, then these can likely be ignored.
If the deadlocks occur in a non-Search databases (e.g. one or more of the Content DBs), then the deadlock is not directly related to Search because Search does not "reach-in" to other databases. In other words, Search does not directly access the Content databases – Search enumerates Content databases by interfacing with the Site Data Web service on the applicable WFE or by browsing the content (e.g. documents) using HTTP GET. Meaning, Search cannot directly lock any objects in a non-Search database. If Content databases happen to incur a higher level of deadlocking during a crawl, then this is most likely related to the additional load related to the gathering process (e.g. browsing) and would therefore tend to expect this to occur under a heavy user load as well. |
Specifically, the most common occurrences that I have encountered with deadlocks and Search databases involve some combination of the following:
In SQL Server, the deadlock may look something like the following:
Spid 123 is waiting for an Exclusive keylock on index IX_MSSCrawlQueue_ComponentID. Spid 111 holds a conflicting Update lock.
Spid 111 is waiting for an Update keylock on index IX_MSSCrawlQueue_ComponentID. Spid 123 is holding a conflicting Exclusive lock.
Other observations and considerations should deadlocks occur
Anonymous
February 13, 2014
Great Article! Thanks for sharing :)
Anonymous
April 12, 2014
Is it possible that these deadlocks might be causing some items not be crawled?
Anonymous
October 16, 2014
No, it would not prevent items from being crawled...
Search is resilient to deadlocks (particularly in the Crawl Store) and handles scenarios where processes are chosen as the deadlock victim – the item will just remain in the MSSCrawlQueue and be picked up again by a subsequent batch.
Anonymous
July 01, 2015
Question, I'm using SP 2010 Ent and we had an issue where my crawl results for my subsite were crawling external URLs like mobil.twitter.com , plug.google.com, and facebook. Apparently when incremental crawls were being done to my subsite, SP was hitting these and a ton of others. I'm not sure how or why the external URLS showed up but it was slowing the performance of the network and SP.
I was able to just delete the subsite crawl source and the server and the network returned to normal. Should I do an Index reset to remove those external URLS from coming back?
Thanks,
Anonymous
July 08, 2015
Check out your crawl rules to see if you allow the crawl to leave the host being crawled and if you allow the crawler to follow complex URLs...
Ask Learn is an AI assistant that can answer questions, clarify concepts, and define terms using trusted Microsoft documentation.
Please sign in to use Ask Learn.
Sign in