SP2010: Search Query Load Balancing *Explained (part 1)
Seemingly “sporadic” query problems are often just straightforward failures being masked by the three levels of load balancing involved with a SharePoint 2010 Search Query. My goal here is to help unravel all the moving pieces by first illustrating a base case and then expanding out a component at a time to explain the various levels of load balancing.
In this post, I'll focus on the load balancing occurring among Query Components (e.g. within the SSA). In following posts, I'll expand the focus to load balancing multiple instances of the SQ&SS (e.g. at the farm level) and then use these as a foundation for sharing troubleshooting tactics with Queries failures (including the completely generic "Internal Server Error Exception Occurred"). This series of posts will focus on SharePoint 2010, but I'm already working on a similar post that will focus on SharePoint 2013.
The Base Case
When a query gets submitted to the search pages in SharePoint, the Search Results web part in the applicable page leverages the Search Query and Site Settings (SQ&SS) service to implement the query processing. Once the query is processed, the results are then returned back to the web part for rendering (Russ Maxwell has a great post here about SharePoint 2010 Search Query Architecture that deep dives on this round trip really well using applicable snippets from ULS and NetMon traces).
In SharePoint 2010, the SQ&SS acts as the Query Processor performing tasks including load balancing queries to the appropriate mirror for each Index Partition, issuing Property Store queries, merging/sorting results, security trimming, and removing [near] duplicates. Also, I often hear the misconceptions that the SQ&SS has to run on the WFE or it has to run on the Query Server. Actually, in SharePoint 2010, the SQ&SS can run on ANY server in the farm (and at a minimum, just needs to be started on at least one server in the farm using either PowerShell or the "Services on Server" page in Central Admin). Being said, I'm intentionally vague throughout this post as to which server the SQ&SS Service Instance(s) is running... for now, just think of it as a logical unit without focusing on which server it runs.
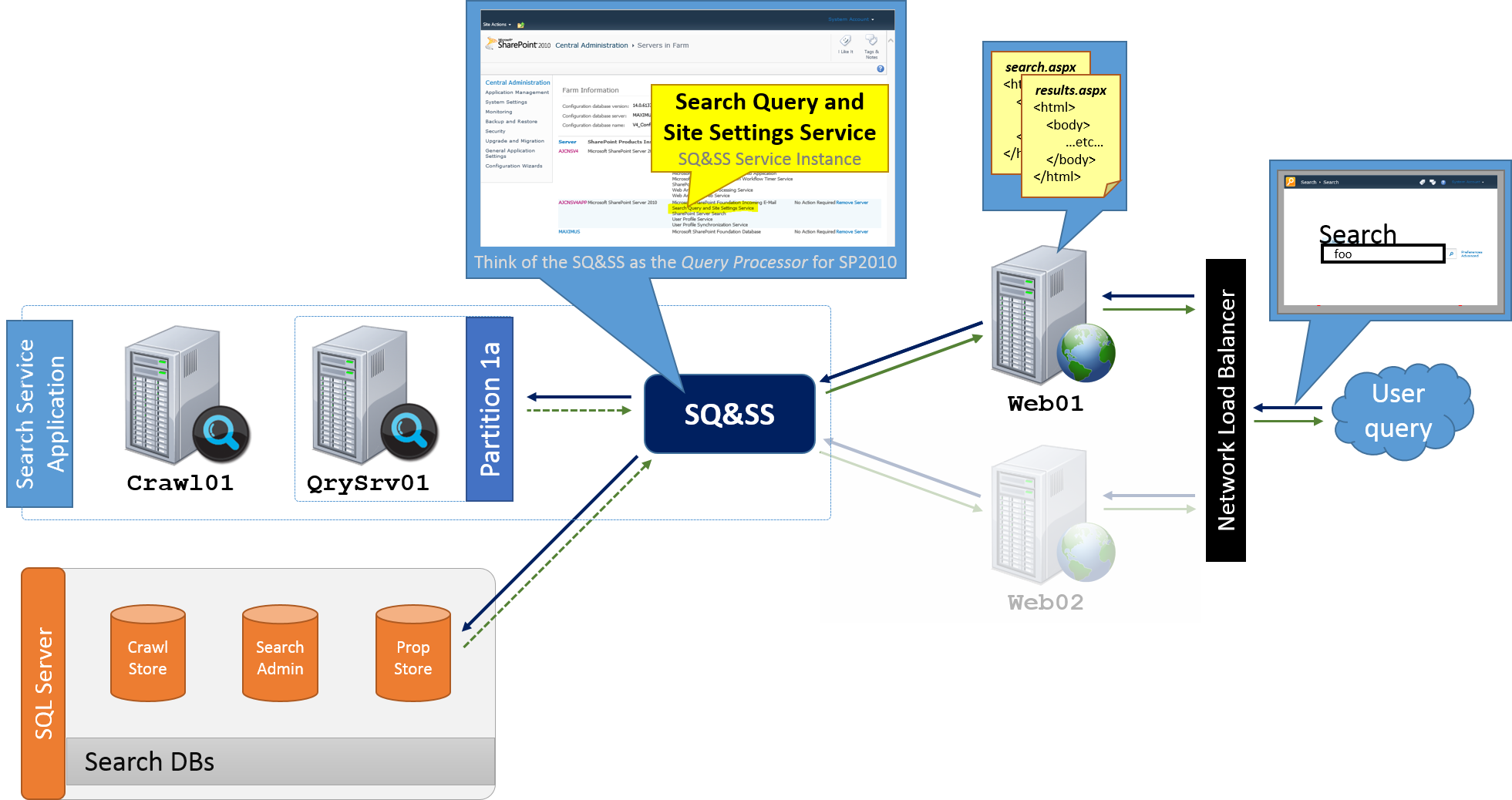
An important concept here is that the Search Web Parts (e.g. the Refinement Panel, the Core Results Web Part, Best Bets, and so on) are all constructs of the WFE. The data that populates these Web Parts, however, comes from Search (via the SQ&SS). In other words, the WFE (more specifically, the SP Web Application) has no idea how to process a Search query. Instead, when it receives a user query from a page request such as https://loadBalancedURL/results.aspx?k=foo), the Web App does know how to talk to an SSA's WCF Service EndPoint (implemented by the SQ&SS) defined in the [default] Service Connection (aka “Service App Proxy”). After the results are processed, the SQ&SS returns the result set as XML back to the Search Web Parts, where they are then rendered (ok, technically speaking, where they are converted by XSLT into HTML and then rendered by the user's browser).
Note: For all SharePoint Service Applications, a Web Application Service Connection is essentially a reference to the particular Service Application's WCF EndPoint(s). For example with Search, this WCF EndPoint has a structure such as https://[someServerName]:32843/-ssa-guid-/SearchService.svc (where someServerName is the server hosting this service EndPoint) and is provided by the SQ&SS, which may be running on multiple servers. In the next post, I'll dive into the case of multiple SQ&SS instances, but for now, we'll assume just one SQ&SS to keep this intentionally simplistic.
Load Balancing Full Text Index Lookups: One Index Partition
In the SharePoint 2010, the Index can be split into one or more Partitions (the physical segmentation of the Index created by hashing a crawled DocumentID to a specific Partition of the Index). If there is one Partition, then 100% of the Index exists in this lone partition (another way of stating this is that all DocIDs would map to this one and only Index Partition). With two Partitions, the Index is segmented into two "parts" where ~50% exists in each Partition (e.g. half the DocIDs map to one Partition and the other half map to the second Partition). With three Partitions, the Index is split into thirds ...and so on. When creating a new Partition, you must also provision at least one Query Component to represent/manage this Partition.
This leads to another common misunderstanding - Index Partitions and Query Components are not equivalent entities. Partitions define the segmentation of the overall Index whereas Query Component(s) manage the Index, with each Query Component managing only the portion of the Index defined by its Partition. For example, assume a single Partition with a single Query Component (e.g. Partition1 => QC1). This QC1 would managed the only copy of the Index (again, one Partition accounts for 100% of the Index). Let's now extend this scenario by adding a second Query Component for this one Partition (e.g. Partition1 => QC1,QC2). In this case, QC1 and QC2 are mirrors of each other (e.g. they contain copies of the same data) and would both manage a copy of 100% of the Index.
When a User issues a query, the Web Application reaches out as described before to a WCF EndPoint for the [default] Search Service Application defined in its Service Connection. The SQ&SS provides the WCF EndPoint(s) for the SSA - that is, on each server where the SQ&SS Service Instance is started (e.g. from Central Admin), the SSA will have a WCF EndPoint such as https://[someServerName]:32843/-ssa-guid-/SearchService.svc. But more succinctly, the Web Application reaches out to the SQ&SS to perform the query.
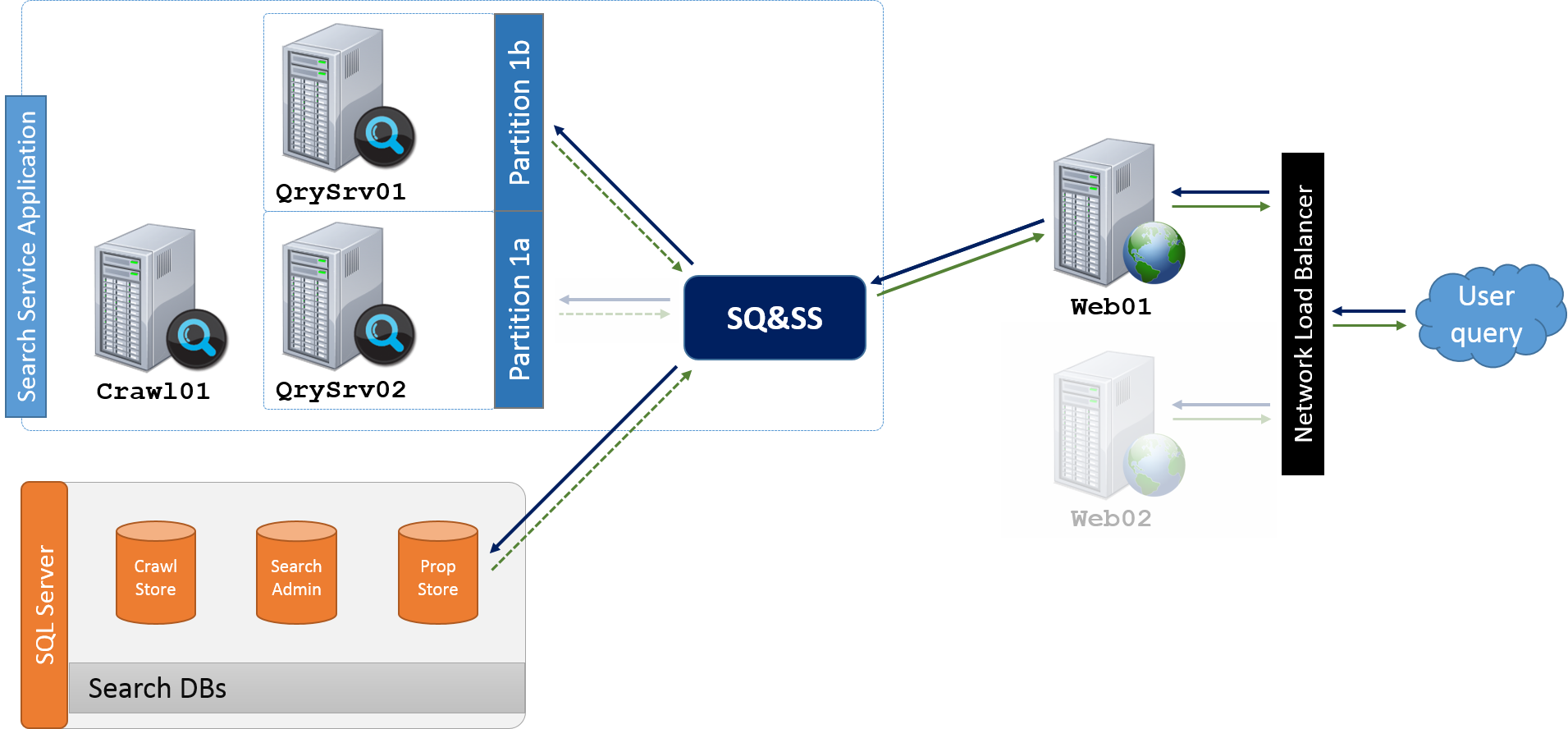
From this point, the SQ&SS performs a Full Text Index query across all Index Partitions. In this case, there is only one Partition and two mirrors.
Note: In this diagram above, the two mirrors for this one Partition are represented by the two blocks labeled "Partition1a" and "Partition1b". Alternatively, I could have labeled these blocks as "QC1" and "QC2". However, because each Query Component's number ties to the order in which the component got provisioned and has no correlation to the Partition to which it belongs, using the QC number could lead to unintended ambiguity. For example, had I used "QC1" and "QC2" instead of "Partition1a" and "Partition1b", it's easy to mistake this for two Index Partitions rather than the desired one Partition with two QCs that happen to be numbered 1 and 2. Also, this corresponds with the architectures on TechNet.
For each subsequent User query, the SQ&SS will round-robin its requests to one QC mirror from each Partition. In other words, in the first query, the SQ&SS reaches out to Partition1a (e.g. QC1). For the next query, the SQ&SS instead reaches out to Partition1b (QC2). On the third request, the SQ&SS cycles back to Partition1a (QC1).
Note: There is an exception here though because it is possible to define a Query Component as "failover only". For this, the QC still acts as a mirror for it's given Partition, but it just simply won't be included in the round robin rotation of queries from the SQ&SS unless all the other non-failover QCs have become unavailable,
Load Balancing Full Text Index Lookups: Two Index Partitions
So what happens when there are multiple Index Partitions? First, let's look at the case of two Partitions with each having a single Query Component (e.g. Partition1 => QC1; Partition2 => QC2). In this case, QC1 would manage 50% of the Index for Partition1 and QC2 would manage the other 50% of the Index for Partition2. Again, for User queries, the SQ&SS performs a Full Text Index query across all Index Partitions to get a full picture of the Index. When there was one Partition, each QC managed a copy of 100% of the Index. With two Partitions, each Partition only has 50% of the Index, so a query needs to reach out to a QC from each Partition to query the entire Index.
For this case (Partition1 => QC1; Partition2 => QC2), there is only one Query Component per Index Partition, so for each User query, the SQ&SS would always reach out to the same two QCs - one QC for the first Partition and a second QC for the second Partition. A more interesting and applicable example can be illustrated with multiple Index Partitions that each have multiple Query Components (Partition1 => QC1,QC2; Partition2 => QC3,QC4).
Note: For what it's worth, this example, which shows QC2 associated to Partition1, also intends to reiterate my previous note - the QC number is just a sequentially assigned identifier and has nothing to do with the Index Partition to which the QC is assigned. In other words, QC2 doesn't imply Partition2.
As before, with a User query, the Web Application reaches out to the SQ&SS to perform the query. The behavior in case (Partition1 => QC1,QC2; Partition2 => QC3,QC4) is essentially a combination of two scenarios already discussed. Similar to the case described for two Partitions each with a single QC, the SQ&SS needs to reach out to one QC from each Partition, and similar to the case of one Partition with two QCs, the SQ&SS will round-robin its requests to one QC mirror from each Partition.
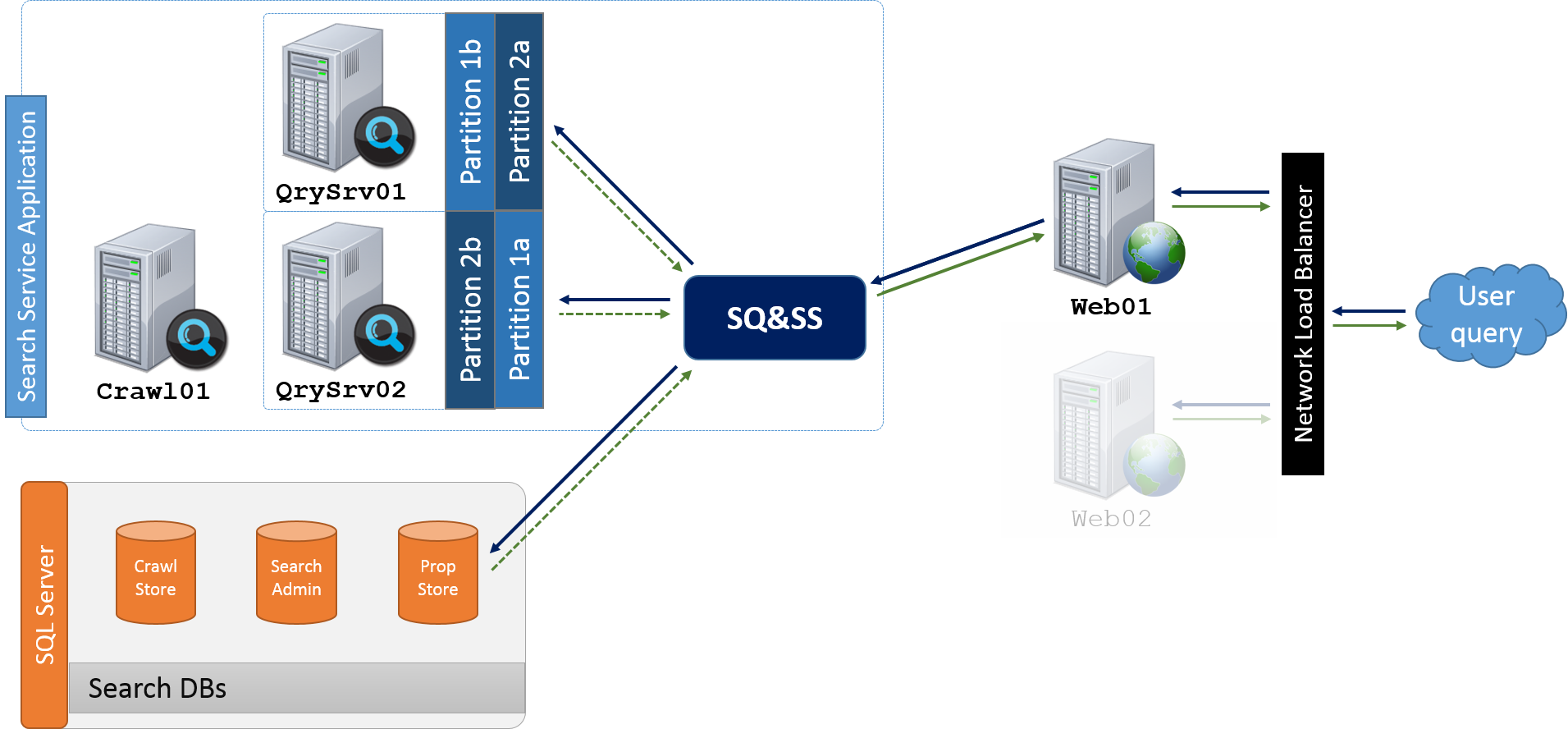
More specifically, in the first query, the SQ&SS may reach out to Partition1a (QC1) and Partition2b (QC4). In a second query, the SQ&SS cycles to Partion1b (QC2) and Partition2a (QC3). In the third query, the SQ&SS again returns to Partition1a (QC1) and Partition2b (QC4).
A key takeaway here is that the SQ&SS, as an EndPoint for the SSA, provides a level of abstraction. Even though the Query Topology has expanded, there is still only a single SQ&SS and thus, only one WCF EndPoint. In other words, consumers of Search (e.g. Web Apps) have no idea how Search is implemented on the backend (e.g. the Query Topology)... consumers only know how to interface with the WCF EndPoint. To further this point, the communication and logic flow up to the point of the SQ&SS is exactly the same for the scenario illustrated here with two Index Partitions as it was in the original scenario with one Partition.
Summary
The Search Query and Site Settings (SQ&SS) provides several key roles for the SSA. First, it implements the WCF EndPoint from which consumers such as Web Applications consume Search. Because of this, it provides a layer of abstraction to the inner workings of the SSA.
Second, it acts as the Query Processor for the SSA by load balancing queries to the appropriate mirror for each Index Partition, issuing Property Store queries, merging/sorting results, security trimming, and removing [near] duplicates. After the results are processed, the SQ&SS returns the result set as XML back to the Search Web Parts, where they are then rendered.
Throughout this post, I assumed a single SQ&SS to first focus on the load balancing among Query Components, however, in SharePoint 2010 the SQ&SS can run on any server in the farm. In the next post, I'll dig into more common scenarios with multiple SQ&SS instances and how the SharePoint farm load balances each of these.