SP2010 Search *Explained: Crawling
Update:
I've started a new series for explaining crawls in the context of SharePoint 2013. For the actual crawl component itself, much of the process is the same as described here and follows a very similar flow up to and down the branch for "For FAST Search for SP2010" described below. Being said, the new series is going to be a deeper dive (to avoid a copy and paste of this) and leverages key ULS messages to provide a step-by-step walk through the entire process.
---------------------
In broad terms, SharePoint Search is comprised of three main functional process components:
- Crawling (Gathering) : Collecting content to be processed
- Indexing: Organizing the processed content into a structured/searchable index
- Query Processing: Retrieving a relevant result set relative to a given user query
In a previous post, I discussed SharePoint Search Concepts and Terminology and now plan to continue by further exploring aspects of the Crawling process (Note: although this content is most applicable to SP2010 and FS4SP2010, the concepts of crawling are largely the same for SharePoint 2013)
In a nutshell, a server running a SharePoint Search Crawl Component (e.g. a “Crawl Server”) performs the act of crawling by making web requests such as HTTP GET to the applicable web front ends (WFEs) hosting the hosting the content. More simplistically, the Crawler makes requests for content and the WFE responds with the requested documents/pages/data. After the content has been gathered by the Crawler, it then gets filtered and processed into the final end product as an index. Regardless of SharePoint Search or FAST Search for SharePoint 2010, the component responsible for crawling (aka “gathering”) content-to-be-indexed is the SharePoint Crawl Component.
Although I have not seen this specifically documented, the following TechNet article refers to this behavior:
Manage crawl load (SP Server 2010) https://technet.microsoft.com/en-us/library/dd335962.aspx By default, the SharePoint Server 2010 crawler crawls all available Web front-end computers in a SharePoint farm through the network load balancer in that farm. Therefore, when a crawl is occurring, the crawler can cause increased network traffic, increased usage of hard disk and processor resources on Web front-end computers, and increased usage of resources on database servers [used by the WFE] . Putting this additional load on all Web front-end computers at the same time can decrease performance across the SharePoint farm. This decrease in performance occurs only on the SharePoint farm that is serving user requests, and not on the SharePoint search farm. This decreased performance can cause delayed response times on the Web front-end computers and delayed response times for the overall farm. |
Enumerating Content from the WFE
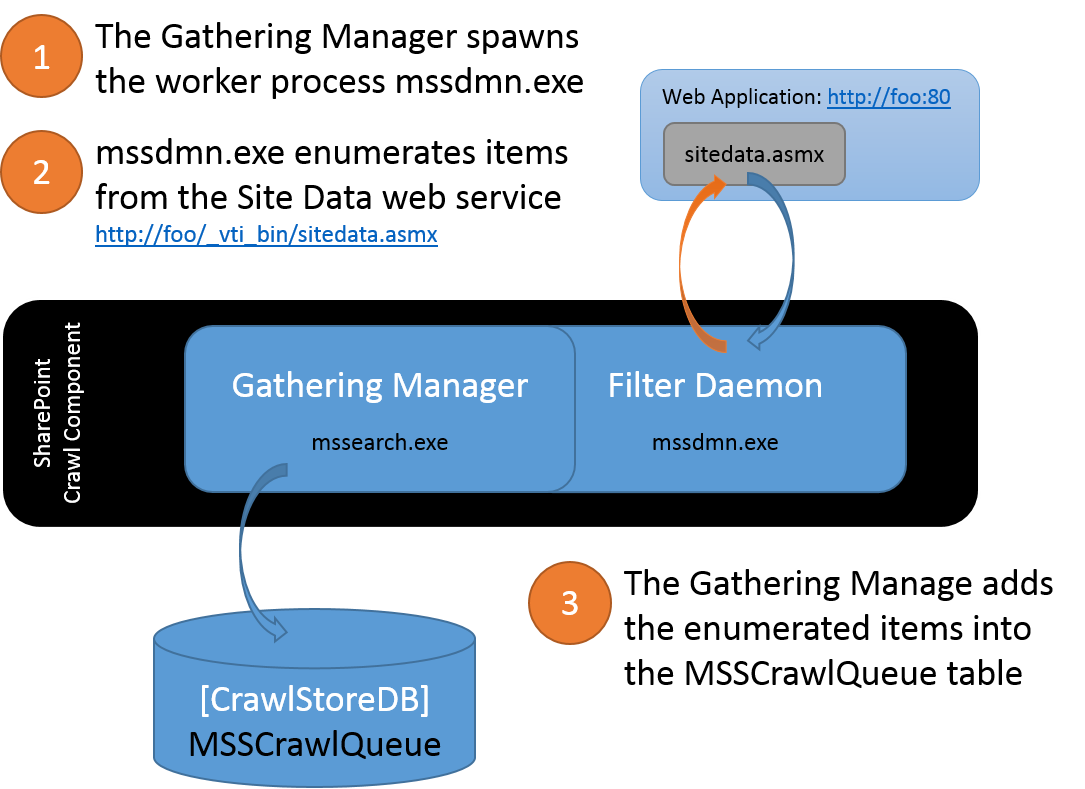
Assuming https://foo:80 as the URL of a Web Application in a SharePoint Farm and a Search Content Source specifies that specifies this start address https://foo, the Crawl Component would gather items from this content source by essentially browsing each item from the web server hosting this content. When starting the crawl of SharePoint content, the Crawler would first look for https://foo/robots.txt to determine if any items are being disallowed. It then browses the default page for the URL and from the response, looks for the response header ‘MicrosoftSharePointTeamServices’. If this response header does not exist, the crawler will proceed as if this were generic web content and perform a “spider crawl”. If the response header does exist, then the SharePoint crawler begins enumerating all of the items in this site by targeting the Site Data web service for this URL - in this case, https://foo/_vti_bin/sitedata.asmx. Simplistically, the Crawler leverages the Site Data web service to ask the WFE, “Hey, WFE… what content do you have for this URL?” The Crawler stores the enumerated items into a queue and then begins retrieving each of the items from the WFE.
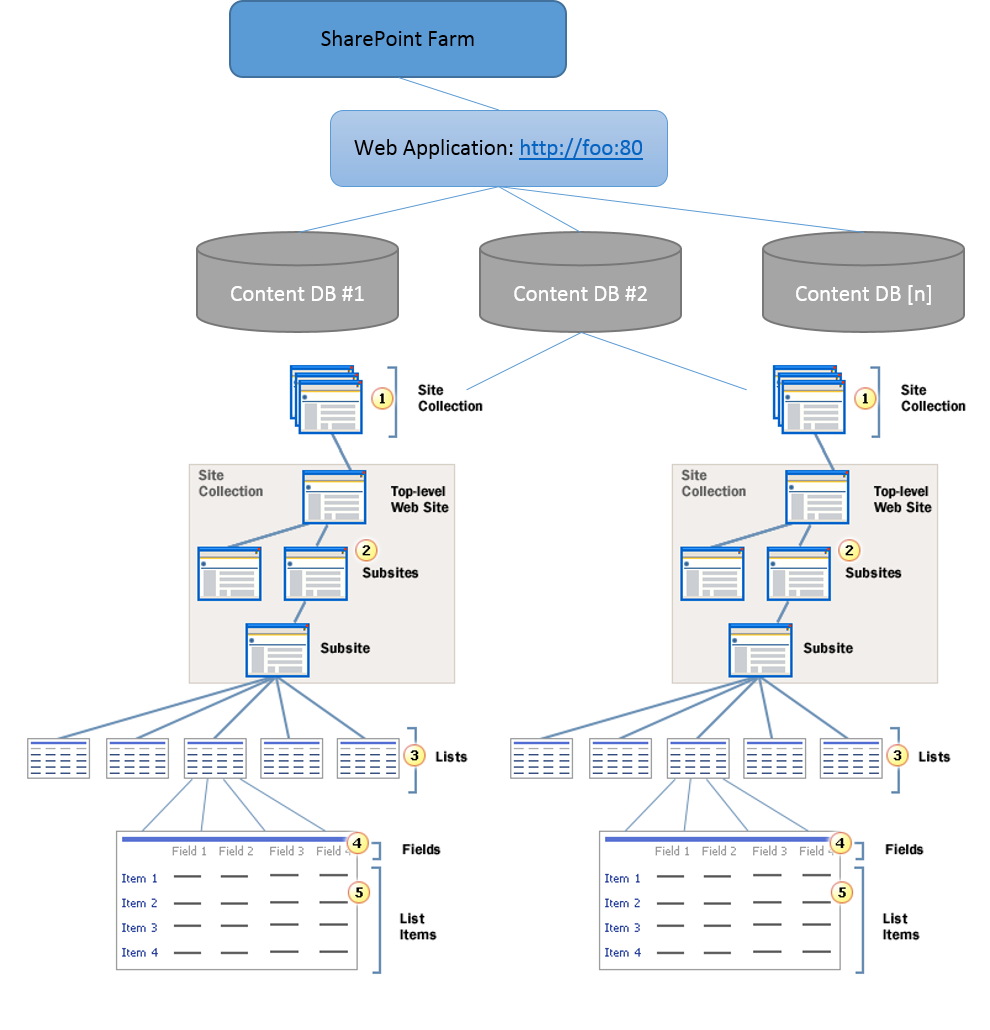
More specifically, the Crawler enumerates the content through a series of iterative SOAP calls through the Site Data web service. It first asks the WFE, “For this URL [Virtual Server], what Content Databases do you have?” Through a SOAP response, the WFE enumerates the applicable Content DB[s] along with the identifying GUID for each content DB. The Crawler then asks the WFE, “For the Content DB with the GUID [XYZ], what Site Collections do you have?” Again, the WFE responds with another SOAP response containing each of the Site Collection[s] along with other metadata applicable to each Site Collection. The Crawler and WFE continue this conversation to drill down on each of the Webs (e.g. the Top level site and all sub-sites) in the Site Collection, each of the lists/libraries in a Web, and items from lists/libraries have been enumerated for the URL.
It’s worth noting that for a Full Crawl, all of the items within this Web Application will be enumerated and queued by the Crawler for processing. However, with an Incremental Crawl, the Crawler will also pass along a Change Log Cookie (that it received from the WFE on the previous crawl) to the WFE. A Change Log Cookie would resemble the following 1;0;5e4720e3-3d6b-4217-8247-540aa1e3b90a;634872101987500000;10120 and contains both the identifying GUID for the applicable Content DB (in this case, 5e4720e3-3d6b-4217-8247-540aa1e3b90a) as well the row ID from the EventCache table (e.g. row 10120) in the specified Content DB. With this, the WFE can identify all events that have occurred for this Content DB since this point and thus, identify any content that has changed since the last crawl.
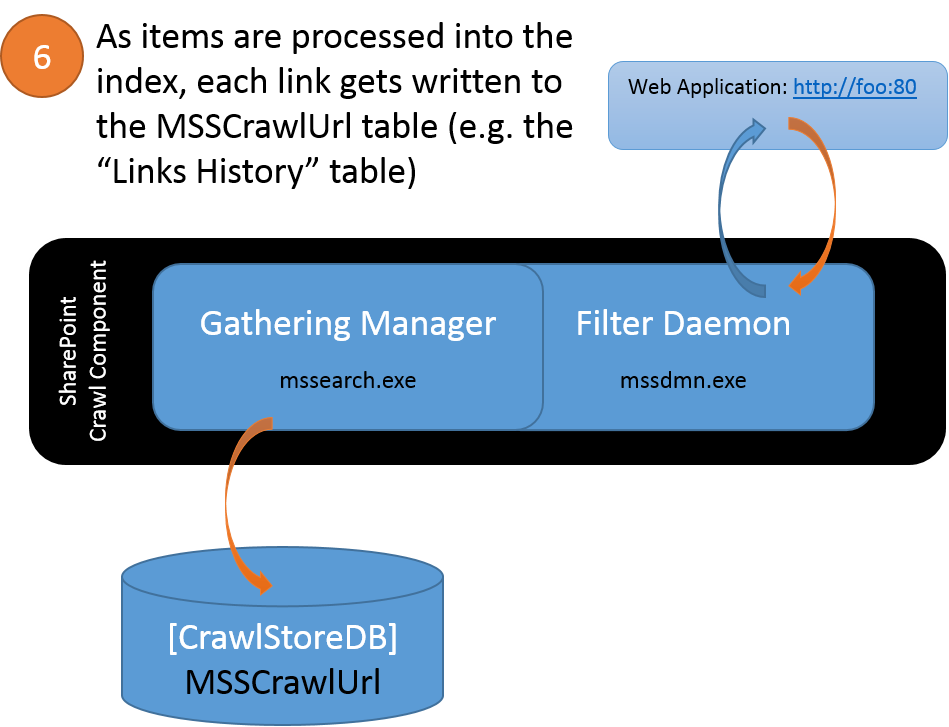
Gathering Content
As it enumerates items-to-be-crawled from the WFE, the Crawler temporarily stores each link in the MSSTranTempTable0 table (in the Crawl Store DB). After some processing, these are links are then flushed into the MSSCrawlQueue table (in the Crawl Store DB). The caveat is that the Crawler will access content using an internal SharePoint URL structure for browsing the items rather than the URL structure we see in the browser to display content. For example, the MSSCrawlUrl table (commonly called the "Links History" table) contains a row for each link that has been crawled. In this table, you will find the following noteworthy columns:
- DocId: The ID assigned within Search for each crawled URL (this is different than the ItemId used within the Content DB for a given item)
- AccessUrl: The URL that SharePoint constructs to access content from the WFE
- DisplayUrl: The URL utilized by users from a browser
- CrawlId: The last crawl that added this link into the MSSCrawlQueue
- CommitCrawlId: The last crawl that successfully processed this link. The CommitCrawlId may differ from the CrawlId column:
- During a crawl (e.g. this item has been queued, but not yet crawled during the current crawl)
- If an error occurred retrieving this link (e.g. this link was queued, but it was not successfully crawled)
Using the stored procedure proc_MSS_GetNextCrawlBatch (in the Crawl Store DB), each Crawl Component involved with the crawl will then pull a sub-set of links from the MSSCrawlQueue and attempt to retrieve each link from the WFE.
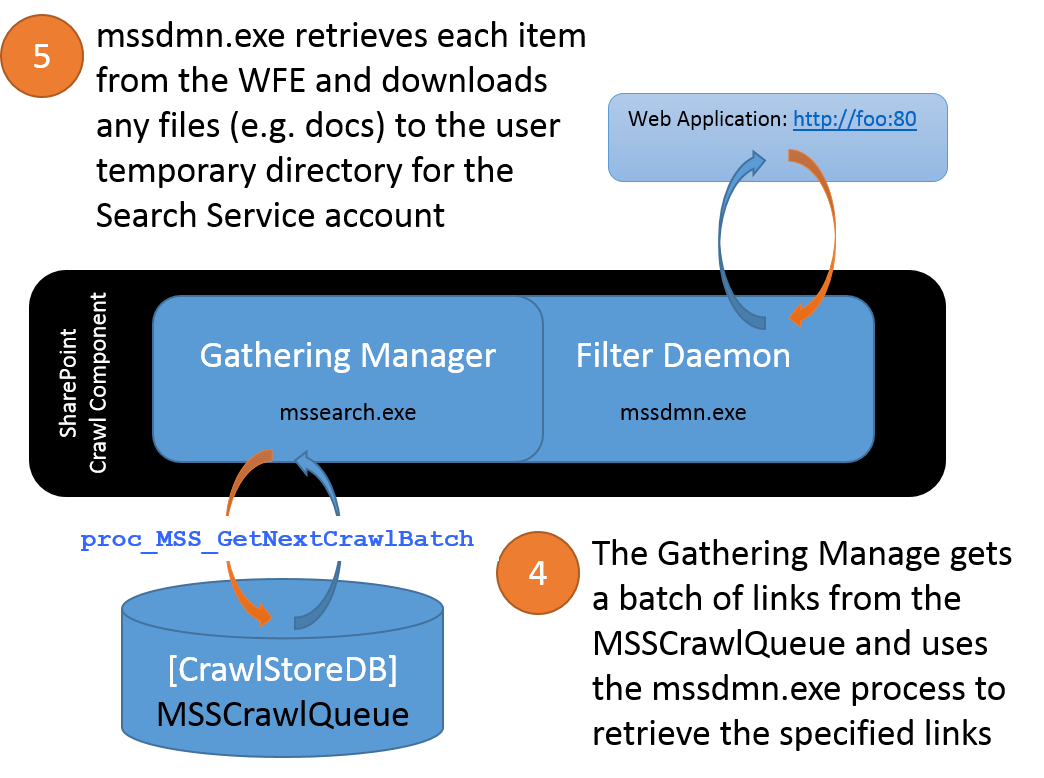
At this point, SharePoint Search and FAST Search for SharePoint 2010 deviate on how each processes the gathered items into an index.
- For SharePoint Search, the items are filtered by iFilters within the mssdmn.exe process, which then passes filtered chunks back to the Gathering Manager. The Gathering Manager then leverages additional plug-ins to capture item ACLs, populate the Property Store, create the Full Text Index files, and prorogate the Full Text Index changes to the Query Components where they will be merged into the existing index
- For FAST Search for SP2010, the FAST Content Plug-in, which runs in the Gathering Manager, creates batches from the gathered items. This plug-in then “feeds” the batches to the FAST Search pipeline via the FAST Content Distributor where the items are filtered and processed into the final end product as an index
- The term “batch” here refers to the collection (created by the FAST Content Plug-in) of items that were retrieved by the gathering process
- The Performance Monitor counters such as Batches Ready, Batches Open, and so on refer to these batches
- By default, the FAST Content Plug-in will create batches of 100 items/documents or 10MB (whichever threshold is reached first)
- It’s also worth noting that batches submitted to FAST Search are different than the batches of items pulled from the MSSCrawlQueue. In other words, these two uses of “batch” are completely unrelated and an unfortunate use of the same word in different contexts
- The term “batch” here refers to the collection (created by the FAST Content Plug-in) of items that were retrieved by the gathering process
In either case, as the gathered items are processed and indexed, the Gathering Manager updates the MSSCrawlUrl table with the links that were crawled.