Windows Azure blob download - Adding code that'll run before, during, and after
A customer posed a question to me around adding custom code that could run before, during, and after the download of a blob from Azure storage.The constraint I was given was that all of this code needed to run opaquely on the server side of the download and could not be something that a client downloading the file would be required to run. So, I set out to find an existing method to solve this problem but found none that really provided all of the control and flexibility that my customer wanted. As such, I went and invented one. This post will talk about how I solved the problem, a little bit about how I validated the solution against more mainstream blob download approaches, and the problems that I'm still left with.
Goals
- Expose a URL that an end user can click on that'll initiate a file download of a file stored in Azure blob storage
- Ensure that any amount of security requirements can be enforced
- Enable running custom code before, during, and after the file download to include writing progress information to a data store like SQL Azure or table storage
- Support everything from tiny up to multi-gigabyte files
- Provide performance on par with standard blob downloads
Approach
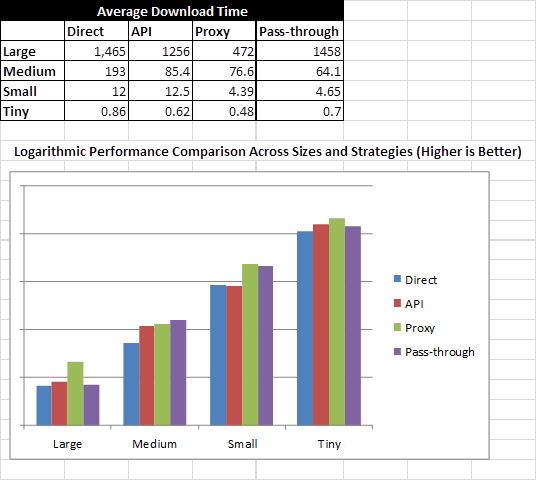
I’ve been examining four distinct download strategies and their performance characteristics across Tiny (> 1MB), Small (~10MB), Medium (~200MB), and Gigantic file (~2.5GB) file sizes, implying four file size magnitudes. Each download strategy represents a different way of downloading a file from Azure blob storage. The strategies are:
1. Direct Download – Uses the direct Azure storage service URL and an ultra-simple HTTP file download mechanism
a. Consider this a good baseline measure
b. Provides no ability to run code before, after, or during a file download
2. API Download – Uses the Azure storage APIs to download a file. This is fundamentally similar to a direct download call but is using owner-level permissions to access Azure storage
a. Similar to a direct download, there is no ability to run server-side code before, after or during a file download
3. Proxy Download – Leverages a web role that internally retrieves the blob stream from the blob storage service and proxies it through to the HTTP response stream.
a. This makes all access to the storage service opaque and encapsulated into a custom HTTP handler that controls the entire download process
b. Allows running code before, after, or during a file download
4. Pass-through Download – Takes advantage of the Azure Shared Access Signature technology and essentially redirects the requestor to a URL that includes authentication information to ensure all downloads are secured
a. Likely the best single solution to your storage problem. This solution minimizes overhead while retaining control over security
b. Allows running code before *only* a blob download. This is because the HTTP response is an HTTP 302 redirection wherein the server relinquishes control once the download URL is transmitted
c. This approach will tend to yield the greatest amount of consistency across file sizes
To test how each of these perform with respect to one another, I created Visual Studio unit tests along with a set of Visual Studio load tests to see how they perform over time. The good news is that the Proxy strategy out performs other download strategies in 75% or more cases, where the pass-through strategy came generally in second (good news). Here are my statistics on average download times:
Problem
There remains an issue that only occurs with supremely large files. That problem is that, since we are proxying the downloaded file through an Azure web role, there appears to be a timeout set somewhere (maybe on the load balancer???) that constrains downloads *of this strategy only* to about 30 minutes. As a result, files in excess of about 2GB will download in large part but have the potential to get aborted closer to the end of the download. This limitation, again, appears to be a network infrastructure issue and not specific to the download strategy. Can anyone verify the root cause of this for me? Are there any solutions in site? If you can solve this, you help me solve an important customer problem.
The Guts
The main chunk of code that I used to implement the Proxy approach is a very simple HTTP handler that asynchronously reads buffers from blob storage. The code appears below. At first, I tried just using
blob.DownloadToStream(context.Response.OutputStream);, but this would end out failing with anything other than small files since no content was showing up on the response stream for a long period of time (until the entire download was complete). That approach also yielded problems with causing the file download dialog to pop up. This approach of chunking the download works well. I even made the buffer size configurable via the query string for the purposes of this SAMPLE code.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Text;
using System.Text.RegularExpressions;
using System.IO;
using System.Threading;
using Microsoft.WindowsAzure;
using Microsoft.WindowsAzure.StorageClient;
using Microsoft.WindowsAzure.ServiceRuntime;
using Yeast;
using Yeast.Collections.Generic;
using Yeast.IO;
namespace BlobProxy.Web
{
/// <summary>
/// Summary description for Download
/// </summary>
public class Download
: IHttpHandler
{
public void ProcessRequest(HttpContext context)
{
try
{
var accountName = context.Request["accountName"];
var path = context.Request["path"];
int bufferSize;
if (!Int32.TryParse(context.Request["bufferSize"], out bufferSize))
{
bufferSize = 100 * 1024;
}
if (accountName != Configuration.BlobProxySection.Instance.AccountName)
{
context.Response.ContentType = "text/plain";
context.Response.Write(String.Format("I don't understand how to work with account name '{0}'.", accountName));
}
else
{
var account = CloudStorageAccount.Parse(String.Format("DefaultEndpointsProtocol=https;AccountName={0};AccountKey={1}", accountName, Configuration.BlobProxySection.Instance.AccountKey));
var client = account.CreateCloudBlobClient();
var pathExpression = new Regex("/(?<containerName>[^/]+)/(?<blobPath>.+)", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.ExplicitCapture);
var pathMatch = pathExpression.Match(path);
var containerName = pathMatch.Groups["containerName"].Value;
var blobPath = pathMatch.Groups["blobPath"].Value;
var container = client.GetContainerReference(containerName);
var blob = container.GetBlobReference(blobPath);
Exception downloadException = null;
bool isDataComplete = false;
var dataQueue = new BlockingQueue<Tuple<int, byte[]>>();
var bufferQueue = new BlockingQueue<byte[]>();
ThreadPool.QueueUserWorkItem(new WaitCallback(o =>
{
try
{
var blobStream = blob.OpenRead();
int blockLength = 0;
do
{
byte[] blockBuffer = null;
if (bufferQueue.Count > 0)
{
blockBuffer = bufferQueue.Dequeue();
}
else
{
blockBuffer = new byte[bufferSize];
}
blockLength = blobStream.Read(blockBuffer, 0, blockBuffer.Length);
if (blockLength > 0)
{
dataQueue.Enqueue(new Tuple<int, byte[]>(blockLength, blockBuffer));
}
} while (blockLength > 0);
}
catch (Exception exception)
{
downloadException = exception;
}
finally
{
isDataComplete = true;
}
}));
blob.FetchAttributes();
context.Response.ContentType = "application/x-msdownload"; // blob.Properties.ContentType;
context.Response.Buffer = false;
context.Response.AddHeader("content-disposition", "attachment; filename=" + blobPath);
while (context.Response.IsClientConnected && (!isDataComplete || dataQueue.Count > 0))
{
if (downloadException != null)
{
throw new Exception("The internal blob download failed.", downloadException);
}
var data = dataQueue.Dequeue();
context.Response.OutputStream.Write(data.Item2, 0, data.Item1);
context.Response.Flush();
//Put the processed buffer back into the queue so as to minimize memory consumption
bufferQueue.Enqueue(data.Item2);
}
}
}
catch (Exception exception)
{
context.Response.Write(String.Format("Failed to download file due to the exception:{0}{1}", Environment.NewLine, exception));
}
}
public bool IsReusable
{
get
{
return true;
}
}
}
}