Case Study: Much ado about Browser's HTTP connection
Here I will be going in-depth on how a browser maintains HTTP connections with the Server. Something which a Web Developer should be aware of. My main aim is to show some of the tidbits of how a connection is made, how it is reset (from client or server) and some of the connection limitations.
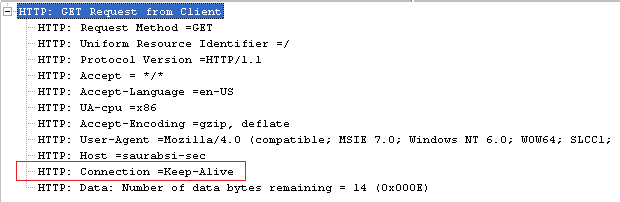
Let's say you have a web application set to run with restricted access. Now assuming that you do not want client browser to renegotiate user's credentials every time it accesses a web resource like .css, .js, .aspx etc, you would like to have a seamless one-time authentication challenge when the user visits the page the first time. This is achieved by IE appending the HTTP header 'Connection: Keep-alive' along with the HTTP request to the server. Note that at times a single page may include tens (sometimes hundreds) of images, each initiating a separate request to the server. If the server is set to honor HTTP Keep-Alive's, a client can maintain an open connection with the server, rather than re-opening the client connection every time with each new request. This will boost up the overall performance of the Web application.
So when a client, say IE requests a web page for the first time, it opens a new connection from some random client port to the HTTP port (By default it is port 80) on the IIS (or any) web server. Now a days most modern browsers like IE/Firefox ask the server to keep the connection open across multiple requests. This is what is HTTP Keep-Alive is all about. If we do not have it in the request header, a browser will make multiple connections for various resources. Let's say you have a Web page that has some graphics and you also need to download some JavaScript/CSS files etc. All these are independent components which have to be downloaded from the web server and depending upon the Keep-Alive header, may have to be downloaded to the client on multiple connections which will need re-authentication every time.
Remember, whenever IE opens a new connection to request a web resource it will be challenged by the server (if it is for a restricted access) and it has to be re-authenticated. This is costly and redundant if all the resources are coming from the same host.
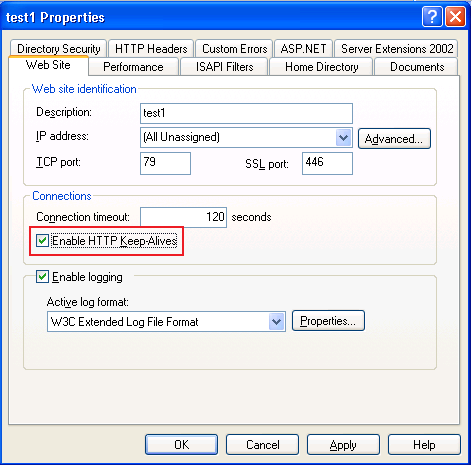
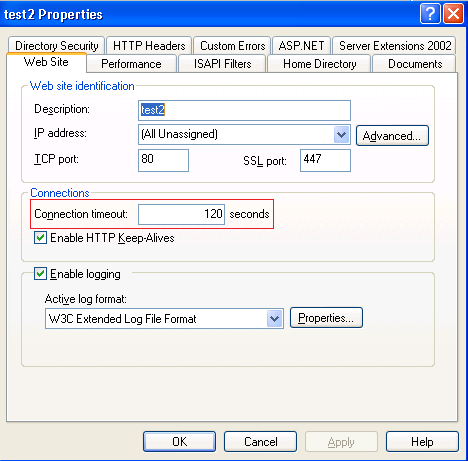
In IIS web server you can enable/disable this option as shown below:
Let's look at the network traffic and see how it looks.
Here's how Client sends a web request. Note the HTTP Keep-alive in the request header.
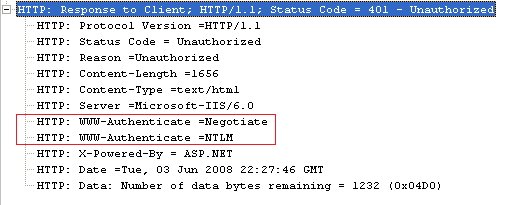
Depending upon whether your web site is designed to provide anonymous access or restricted access, here's how the server responds back. Since in our case IIS Web site is set to restricted access it will send back the response as 401 the first time, with the list of supported Authentication methods.
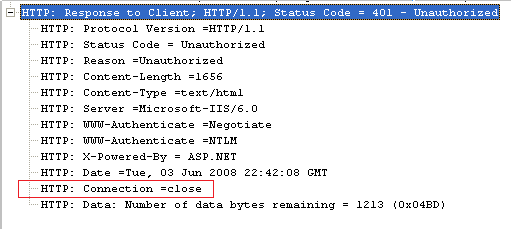
The client sends back the requested credentials/tokens (depending upon the authentication method), on the same connection this time. Note, had the Keep-Alive not been supported by the IIS web site, it would have sent back a response header ('Connection =close') and would have closed the connection with the client as shown below.
If IIS has Keep-Alives enabled it will not send the 'Connection: close' header in its response leading to the same connection being used for subsequent requests (until there are other factors coming in which I will talk about shortly). Also notice that since the same connection is being used for subsequent requests by the client, the source and destination ports will remain the same.
Client's HTTP Web request:

Server's HTTP Web response:

Here I am not going to delve deeper into how IE request is authenticated by IIS. You can refer to this KB for more information on this topic.
Now any related requests corresponding to the same web page (like embedded Image, css files) etc are made on the same connection by the browser. Notice the ports and the Connection header for further requests on the same connection.
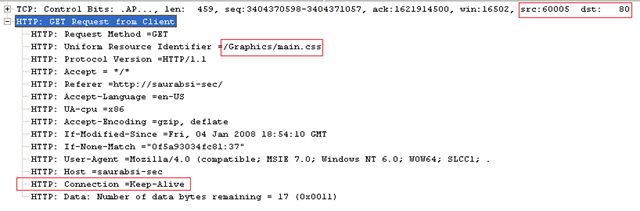
Let's see another trace wherein HTTP Keep-Alive is disabled in the IIS web site.
Client sends a request (as usual with 'Connection =Keep-Alive' in the request header):
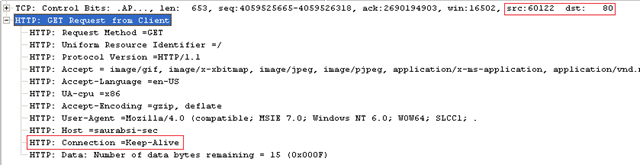
Server responds back with a 401 the first time since it's a restricted access. Forget the status code for now.
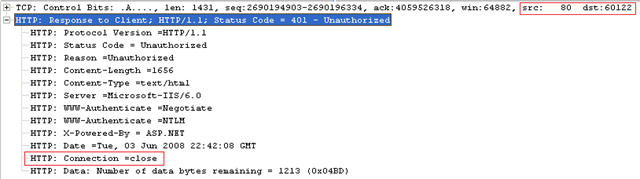
Notice that this time IIS responds back with a 'Connection: Close' header in its response. So this means that for further requests IE has to initiate a new connection, which means a new source port will be used this time.
Here it is. Notice the source port has changed from 60122 to 60123.
Client sends another request:
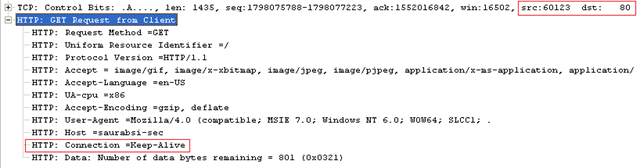
Server responds back with 200 status code this time. Notice the 'Connection =close' again this time in the server's response.
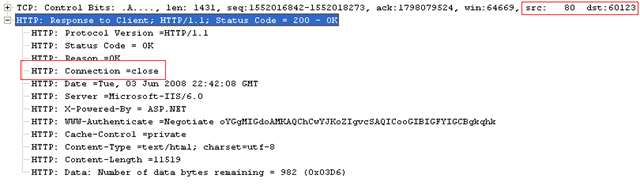
So next request for any resource by the browser will again be on a new connection.
Remember an IE browser can open a maximum of two concurrent connections (by default) to a single host. Hence if you have lot of images etc that have to be downloaded as part of the web page, you will see them coming slowly two at a time. What I mean is that an IE client will open two simultaneous connections to the same host, let's say www.abc.com and request for resources associated with the page. This is as per the HTTP specifications. IE will wait until the two connections are released or if they are reset for any reason for any further requests. Check this out.
Firefox by default also opens two simultaneous connections to the same host. You can increase the concurrent connection limit for IE as per this KB. Also check this for tweaking Firefox.
It's the same reason why you may not be able to make multiple AJAX calls from the same client. You can have as many objects open and waiting as you wish, but the browser will only work on two at a time while the others wait for one of the two active requests to finish.
**In IE8, considering the strong increase in popularity of AJAX applications the number of connections per host has been increased to 6 from 2 for HTTP 1.1 server for broadband connections. Check this specification.
What will happen if we have let's say IFRAMES in a Web page. Let's thinks of such a scenario:
Let's say I have an HTML page which uses IFRAME's and each IFRAME makes a call to some host for a resource. And each of these web requests are long-running. It may be a long executing task at the server end or downloading of large image files etc. Now since we now know that IE has a default limitation of 2 concurrent connections to a host (web site) by default, let's see how will the response be.
You will notice that responses from the IFRAMES come two at a time if they are made to the same host. Every individual IFRAME request takes up one connection of the browser. Basically once two connections are already made to the same host, IE has reached its concurrent connection limit for that host, and hence other IFRAME requests will have to wait if they are being made to the same host as the other two connections.
If on the other hand you have multiple IFRAMES and not more than two are requesting resources from the same host, all of them will open new connections simultaneously to their hosts and get the response accordingly depending on other factors like request execution time/network congestion etc.
*Another thing that one needs to keep in mind is that IE6 will reset an existing connection if it received a 404 as a response from the server. IE7 (going forward IE8..) will not show the above behavior.
What I meant can be better understood by analyzing the HTTP traces below:
An IE Client sends a request:
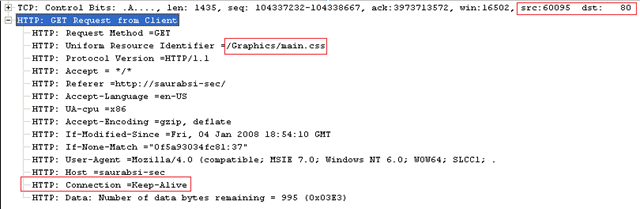
Server responds back with a 404, assuming request is authenticated this time but resource '/Graphics/main.css' is not found.
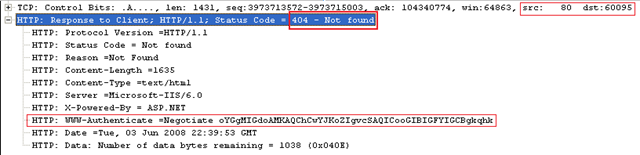
Now what should happen? Should the same connection be used for further requests? No
IE initiates a fresh connection to the server for the next request (here '/StyleSheet.css') after server has returned 404. This happens even though HTTP 1.1 is being used. Notice the source port is changed this time. New port means a new connection.
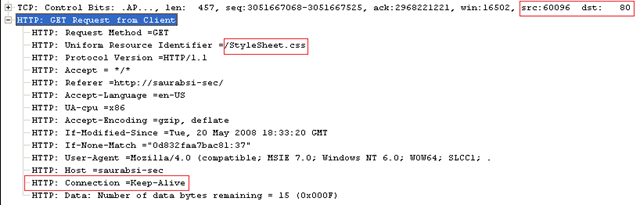
What happens is that initially IE6's WinInet socket connection attempts to download the missing file. Server returns a 404 as a response. But due to the nature of WinInet design it will not immediately return the socket back to the keep-alive pool for about 2 minutes. Hence this will spur a new connection attempt on a new socket/port.
WinInet does not reuse the port by default after a 404 if the socket is in a TIME_WAIT state. TIME_WAIT means the port is still half-open. One side hasn't completely terminated the connection. WinInet in IE6 returning used sockets back to the keepalive pool is less than optimal, and it can take up to 2 minutes for a released socket to go back to the pool (and this can cause 401s, client hangs due to max connections reached, etc). WinInet in IE7 went through a rewrite, and this section of the code was cleaned up quite a bit, causing the behavior difference between IE6 and IE7.
So far we had been seeing how the client behaves when it comes to initiating/persisting a connection. what about the server?
When a browser establishes a connection with the server, the connection is open as long as the transaction is going on between them. Once the client has received what it needed, it can close the connection or leave it open for further requests. Most browsers ask the server to keep the connections open using their 'Keep-alive' feature. Now since we know that a connection is a costly affair, it doesn't make sense to keep it idle for a long time. Here in, a Server can pitch in and reset the connection from its end if the connection has remained idle for a long time. This is set at the server side by using the property called "Connection timeout" of the Web site.
Here is how the network trace will look like:


After ~120 seconds idle time (as in the pic above), server will send a TCP RESET to close the inactive connection.
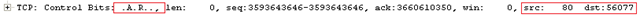
So you see not all reset from the Server side is bad, it helps ensure the server does not get into any DoS attack situation. There is always someone to clean up the litters ;-)
L8Rz,
>SS