Concepts of SQL Server 2014 Columnstore
- This blog has been re-published at https://techcommunity.microsoft.com/t5/Running-SAP-Applications-on-the/Concepts-of-SQL-Server-2014-Columnstore/ba-p/367878
- This blog post might be outdated by now. The latest documentation regarding SQL Server Columnstore on SAP is available in https://www.sap.com/documents/2019/04/023e5928-487d-0010-87a3-c30de2ffd8ff.html
SQL Server 2014 delivers two different in-memory features, which are both fully integrated into the SQL Server Engine:
- In-Memory Optimized Data Warehouse
This feature is optimized for OLAP workloads and is implemented by two index types: The read-only Nonclustered Columnstore Index (NCCI) and writeable Clustered Columnstore Index (CCI). SAP supports both index types for the fact tables in SAP BW cubes. The documentation of using columnstore indexes in SAP BW is available in the blog: https://blogs.msdn.com/b/saponsqlserver/archive/2015/03/23/sql-server-2014-columnstore-released-for-sap-bw.aspx - In-Memory OLTP (Hekaton)
Hekaton is optimized for OLTP workloads and is implemented by a new table type: Memory-optimized tables. Hekaton uses lock and latch free objects, new index structures (hash indexes) and natively compiled stored procedures. SAP currently does not support Hekaton for its ERP systems. Therefore we do not further discuss Hekaton here. See the following blog for further information: https://blogs.msdn.com/b/saponsqlserver/archive/2014/02/09/new-functionality-in-sql-server-2014-part5-in-memory-oltp.aspx
In-Memory Optimized Data Warehouse
The columnstore is transparent to a large extent for existing applications, since it is implemented as an index. You do not need to decide for the rowstore or columnstore when creating a table. Indeed, you can even have rowstore and columnstore side-by-side. SQL Server Query Optimizer can use both stores, when there is a clustered (rowstore) index and a nonclustered columnstore index.
A database administrator can use the same, familiar environment for the columnstore as for the rowstore: The columnstore is fully integrated in the SQL Server Management Studio and uses the same backup and restore procedure. The rich high availability features of SQL Server are also available for the columnstore: Always On, Database Mirroring and Database Clustering.
The principal characteristics of the columnstore are:
Columnar Format
Storing the data in columnar format is optimal for aggregations and Data Warehouse (OLAP) queries. A columnstore index typically contains all columns of a table. There is no order of the index columns in the columnstore, while the field order of a compound rowstore index has severe impact on its performance. Let's have a closer look on the SQL Server columnstore index:
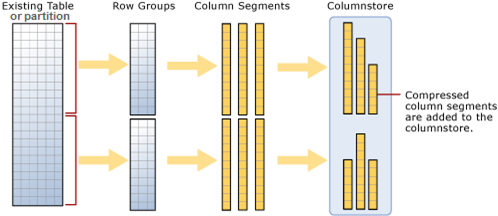
Each table (and database partition) is divided into rowgroups of up-to one million data records (exactly: 1,048,576 data records). Each column of a rowgroup is stored in its own segment. Each segment is compressed individually. This results in high compression rates, because the data within a segment is typically very similar and always has the same data type. Queries accessing only a few columns (in contrast to a SELECT * query) do not have to touch segments of other columns. Each segment contains metadata about the lowest and highest value of a segment. This further reduces the number of segments needed for a query by evaluating this metadata in a process called segment elimination.
In-Memory Optimized
A segment contains a fixed (maximum) number of data records, but the size of different segments varies heavily (caused by the compression). Furthermore, segments are quite large and typically do not fit on a traditional database page. Therefore, SQL Server uses a separate Columnstore Object Pool for caching columnstore indexes in RAM. This allows the usage of in-memory optimized data structures, which are not restricted by the 8 KB block size of the SQL Server Buffer Pool. In contrast to a competitive RDBMS system, SQL Server does not need keeping all columnstore tables in RAM. SQL Server has an In-Memory Optimized, not an In-Memory Resident columnstore. The segment is the transfer unit from Columnstore Object Pool to disk. It is stored in binary format on disk, similar to an IMAGE field. Another competitive RDBMS uses the columnstore as a memory-only index. The columnstore index has to be created from scratch when a table is accessed the first time. This is not the case for SQL Server: The data is already stored in columnar format on disk.
Intensive Usage of Parallelism
SQL Server uses intra-query parallelism, which can be configured by the configuration parameter "max degree of parallelism". Though it is also used for the rowstore, intra-query parallelism scales much better for the columnstore. In addition to this, SQL Server also uses intra-thread parallelism: In the Batch Mode, one thousand rows are processed at the same time rather than processing row by row. The batch mode was introduced in SQL Server 2012. It has been extended to further operators and filters in SQL Server 2014.

Columnstore indexes
A columnstore index in SQL Server 2014 can be either clustered or nonclustered:
Nonclustered Columnstore Index (NCCI)
The read-only NCCI is available since SQL Server 2012. It is created on top of a clustered index or heap. Therefore, a second copy of the data exists in the rowstore. You can choose the columns included in the NCCI. However, you typically include all columns of the table in the NCCI. Once you have created an NCCI, the whole table is read-only – not only the index.
Clustered Columnstore Index (CCI)
The writeable CCI was introduced in SQL Server 2014. Clustered index means, that the index contains the data. An additional copy of the data does not exist anymore. The CCI always includes all columns of the table. In SQL Server 2014 it is not possible to create an additional index on top of the CCI. This restriction also applies for the primary key constraint.
The CCI is still optimized for Data Warehouse queries. For supporting DDL operations, a Delta Store has been added. Changing a single row directly in the columnstore would require the re-compression of several segments within a rowgroup. By using the Delta Store you can delay the compression of the inserted and updated rows until a significant amount of data records has been modified.
Each rowgroup consists of the following elements: The Delta Store (in row format), the Compressed Segments (in columnar format) and the Deleted Bitmap. The data records are either stored in the Delta Store or in the Compressed Segments. The process of converting the data rows from the Delta Store to the Compressed Segments is called Rowgroup Compression. The Rowgroup Compression is always performed online. It is completely transparent for the application and any running query. Neither a committed nor an uncommitted SELECT is blocked by the Rowgroup Compression. A system thread called Tuple Mover automatically compresses full rowgroups (means rowgroups having their maximum size of 1,048,576 data records). However, you can also manually compress a rowgroup before it reaches its maximum size. After creating or rebuilding a CCI, all rowgroups are fully compressed.
DML operations on the CCI work as follows:
- INSERTs: New data records are always inserted into the Delta Store
- DELETEs: Data records in the Delta Store are deleted directly. If the data record had already been compressed, then its Columnstore Segment is not touched again. Instead the record is marked as invalid using the Deleted Bitmap. The record will be physically removed the next time you perform an index rebuild
- UPDATEs: An update is processed as a DELETE followed by an INSERT (within one transaction)
Rowgroup Compression
There are two ways of loading data into a table having a CCI: Bulk Copy and INSERTs. SAP BW is only using INSERTs. Therefore we are having a closer look at this scenario. The loaded data records are inserted into the Delta Store of the open rowgroup. Once the rowgroup is full (having 1,048,576 data records) it will be closed and a new open rowgroup is created. All additional data records are inserted into the Delta Store of the new rowgroup. This results in exactly one open rowgroup and several closed rowgroups, independent of the number of data load processes and the number of rows inserted. The Tuple Mover thread runs every five minutes and compresses all closed rowgroups. Therefore all data records of the table are in columnar format, except the rows in the single, open rowgroup. The following picture shows the status of a table with a CCI, after four sequential data load processes and the online Tuple Mover had run. 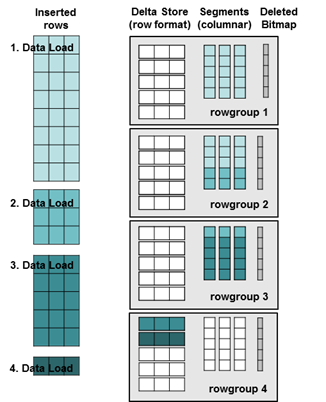
The query execution plan is exactly the same, whether the data records are already compressed or still in the Delta Store. As a matter of course, the query performance is better once all rowgroups are compressed. A typical data warehouse table has hundreds of million rows. In this scenario one million uncompressed rows do not have a big impact on the query performance.
However things look different when table partitioning is used. In SAP BW, each data load is creating its own partition. Therefore there is very likely one open rowgroup per partition (per data load). As you can see in the picture below, a significant part of the loaded data records are uncompressed, even after the Tuple Mover had run: 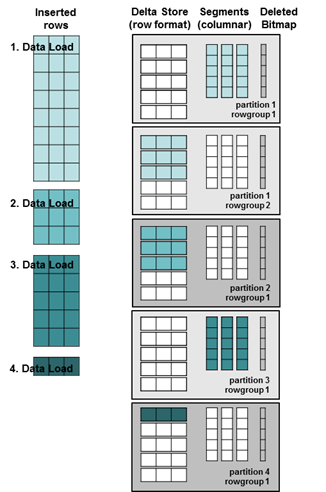
In this scenario you have to manually compress the open rowgroup by using the following SQL command:
- ALTER INDEX … ON … REORGANIZE
WITH (COMPRESS_ALL_ROW_GROUPS = ON)
Unfortunately, this command is single threaded in SQL Server 2014. Therefore you may decide using a full index rebuild (which can use several database threads), if there are lots of uncompressed rowgroups in a table. In this case, the runtime of ALTER INDEX REBUILD is shorter than the runtime of ALTER INDEX REORGANIZE. However, the REBUILD needs much more system resources.
In SAP BW, ALTER INDEX REORGANIZE is always executed when repairing the indexes of an SAP BW cube. Therefore all rowgroups are manually compressed after each data load, if you include the SAP BW process chain step "Create Index" in all data load process chains (BW process chains containing a Data Transfer Process into a cube).
Monitoring the columnstore
To get the size of the Columnstore Object Pool, execute the following SQL command:
- SELECT isnull(total_kb,0) as total_kb FROM sys.dm_os_memory_broker_clerks
WHERE clerk_name = 'Column store object pool'
After implementing the newest SAP Support Packages, you can see the size of the Columnstore Object Pool on the main screen of SAP transaction DBACOCKPIT: 
The compression state of the individual rowgroups can be retrieved with the following SQL command:
- SELECT * FROM sys.column_store_row_groups
WHERE object_id = …
In SAP you can see this information in DBACOCKPIT → Single Table Analysis → Columnstore Groups 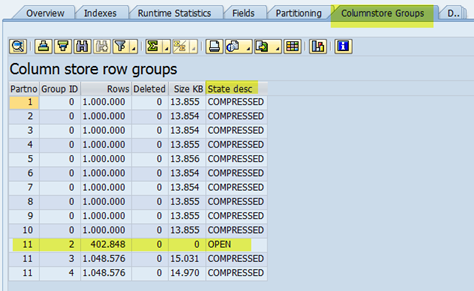
Further reading
Detailed technical description of SQL Server 2014 In-Memory technologies are published at