Раскраска графов с помощью простого поиска с возвратом. Часть 1
Постоянные читатели моего блога знают о том, что я интересуюсь изучением того, как изменить свой стиль программирования на языке C# таким образом, чтобы использовать больше концепции функционального программирования, такие как неизменяемые (immutable)структуры данных вместо изменяемых (mutable), использование декларативного потока управления, например, на основе запросов LINQ вместо императивного потока управления в форме циклов. Я попробую решить достаточно простую задачу, используя смесь неизменяемых и изменяемых структур данных, а также декларативного и императивного стилей, чтобы показать, когда применение каждого из них является полезным и подходящим.
Для примера я выбрал задачу раскрашивания карты таким образом, чтобы ни один из двух регионов с общей границей не были одного цвета. (Обратите внимание, что мы считаем, что два региона содержат общую границу, только если они встречаются по граничной линии; но они могут иметь одинаковый цвет, если у них общий угол.) Это известная задача. Возьмите плоскость или сферу и вы сможете найти карту, которая потребует как минимум четырех цветов. Давайте, например, посмотрим на карту Южной Америки; очевидно, что у Бразилии, Боливии, Парагвая и Аргентины есть общая граница друг с другом, поэтому потребуется как минимум четыре цвета. Но что совсем не так ясно, так это то, что если вы возьмете любую карту, то для ее раскраски потребуется не более четырех цветов; четыре цвета всегда достаточно для плоскости или сферы.
{kind=link}
Конечно, это совсем неинтересно настоящим картографам, у которых нет ограничений с количеством цветов, но обычно есть другие ограничения. Например, если раскрашивать политическую карту мира только четырьмя цветами, тогда или Боливия или Парагвай будут такого же цвета, что и океан. Кроме того, с реальными картами иногда возникают ситуации, когда вы хотите использовать один цвет для двух разных целей; например, Аляска и другие 48 Штатов Америки должны быть одного цвета, что может налагать дополнительные ограничения.
И даже несмотря на то, что теоретические проблемы раскраски карт могут не соответствовать практическим проблемам в реальных областях, эта проблема все еще интересна как с теоретической, так и с практической точек зрения. Чтобы решить ее, мы можем обобщить задачу и свести задачу «смежных» регионов карты на плоскости к узлам графа. Создадим по одному узлу для каждого региона. Каждые два региона, которые должны быть закрашены разными цветами, имеют общее ребро. Если мы найдем алгоритм, который определит цвета каждого узла графа, тогда получим решение для раскраски соответствующей карты. Например, для раскрашивания карты Южной Америки, нам просто нужно раскрасить следующий граф:
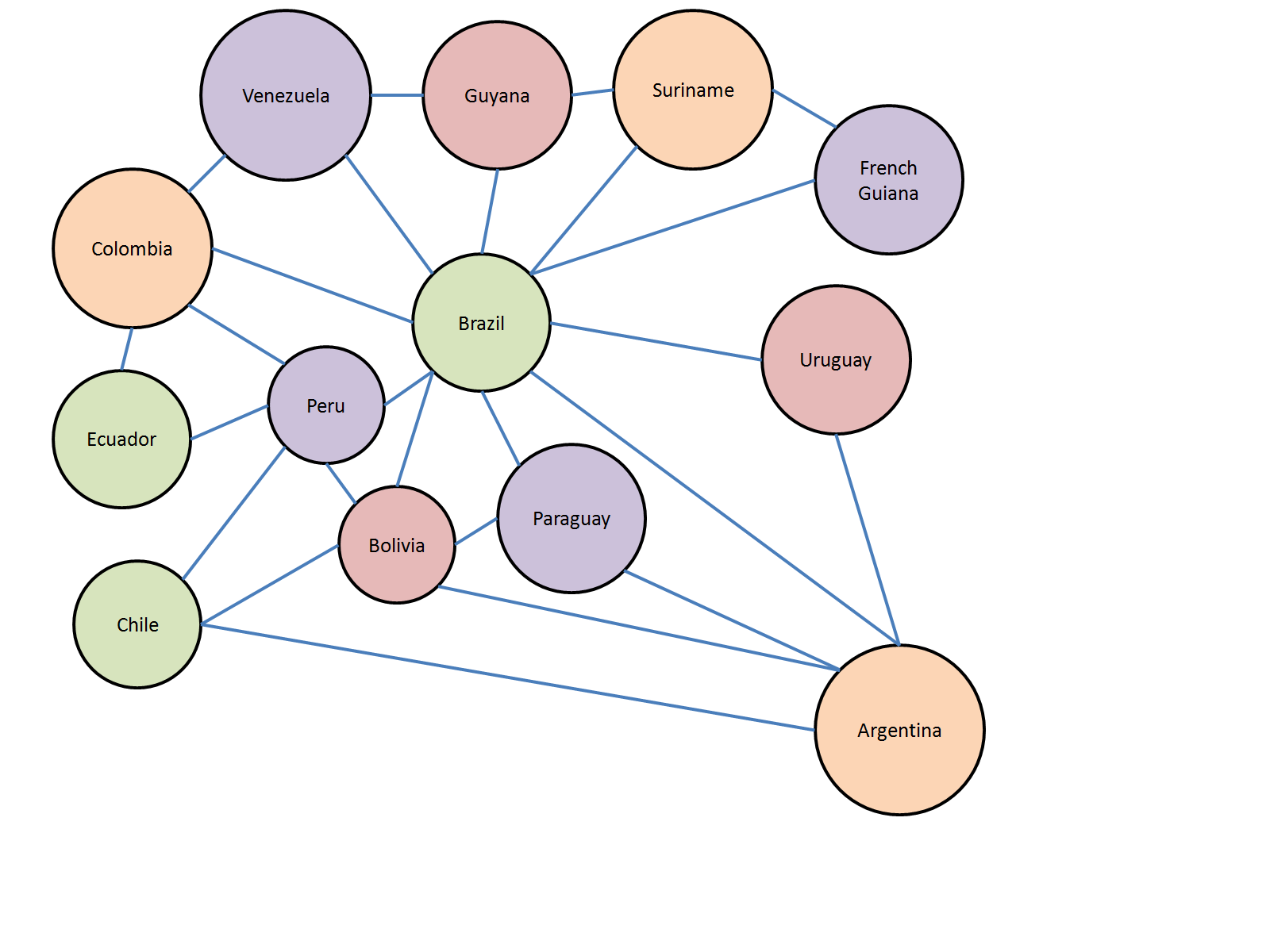
Я показал граф с одной из возможных цветовых схем, но существуют и другие варианты.
Давайте начнем с проектирования простой структуры данных для представления произвольного графа. Любой процесс проектирования представляет собой результат компромиссных решений разных противоречащих друг другу целей, так что я думаю, будет полезно перечислить эти противоречивые цели и вытекающие из них компромиссы.
Существует два стандартных способа представления произвольного графа, состоящего из n узлов и e ребер: вы можете создать массив размера n на n типов bool, значение которого будет говорить о том, существует ли ребро между двумя узлами; либо вы можете создать список, размера e, представляющего все ребра в произвольном порядке.
Преимущество первого подхода состоит в том, что в этом случае чрезвычайно просто получить список всех ребер, выходящих из определенного узла; недостатком же является использование большого объема памяти при больших значениях n и малых значениях e. Преимущество второго способа заключается в том, что он эффективно использует память для разреженного графа, но он является неэффективным при попытке получить всех соседей конкретного узла. (Компромисс: память vs время выполнения). В обоих случаях, примитивная реализация использует около 50% памяти впустую для двунаправленных графов, поскольку ребро от А к B, также является ребром от B к A.
Однако, для наших целей мы будем использовать графы относительно небольшого размера, так что в любом случае я не очень беспокоюсь о том, какой подход выбрать или о том, что будут впустую потрачены несколько байт. Давайте воспользуемся первым подходом и будем представлять граф в виде матрицы смежности размера n на n.
Должен ли граф быть направленным или ненаправленным? В некоторых случаях граф явно является направленным. Так, например, генеалогическое дерево явно является направленным графом: если Алиса – мама Боба, то Боб не является мамой Алисы! Рассматриваемая же нами концепция «смежных регионов» по определению является ненаправленной. Если Бразилия является соседом Перу, то Перу также является соседом Бразилии.
Мы можем создать направленный граф и на его основе создать ненаправленный граф, добавляя всегда ребра парами; или мы можем создать ненаправленный граф с самого начала; или мы можем использовать направленный граф в качестве базового класса для ненаправленного графа; или мы можем создать ненаправленный граф и создать на его основе направленный граф путем добавления, в случае необходимости, информации о направлении для каждого ребра. Существует множество вариантов решения.
Давайте предположим, что мы остановились на первом варианте: просто создадим направленный граф и будем требовать от пользователя добавлять по два ребра, если ему нужен ненаправленный граф. Это сделает нашу структуру данных более гибкой (поскольку позволит представлять как направленные, так и ненаправленные графы), но увеличит вероятность ошибок (поскольку пользователю придется сохранять инвариант самостоятельно в случае, если он захочет использовать ненаправленный граф; каждый раз, когда вы добавляете избыточность в структуру данных, вы добавляете возможность для потенциальных ошибок. )
А подвержен ли этот вариант ошибкам сильнее в нашем случае? Хотя граф смежности логически является ненаправленным, для наших целей вполне можно использовать направленный граф. Совершенно неважно, являются ли эти ребра направленными или нет! Если мы каким-либо способ скажем, что Бразилия граничит с Перу, и случайно скажем, что Перу не граничит с Бразилией, мы все равно определим, что обе эти страны не могут быть зелеными. Для решения нашей задачи достаточно знать хотя бы одно направление.
Одним словом, мы можем создать класс ненаправленного графа, который будет заботиться о том, что ребра всегда содержат пары значений, но на данный момент это нам не требуется. (Компромисс: гибкость vs простота; сложность (использование множества классов для представления графов) vs перекладывание ответственности на пользователя. )
// Неизменяемый направленный граф
internal sealed class Graph
{
// Если существует ребро между A и B, тогда neighbours[A,B] равняется true.
readonly private bool[,] neighbours;
readonly private int nodes;
public Graph(int nodes, IEnumerable<Tuple<int, int>> edges)
{
this.nodes = nodes;
this.neighbours = new bool[nodes, nodes];
foreach (var edge in edges)
this.neighbours[edge.Item1, edge.Item2] = true;
}
public IEnumerable<int> Neighbours(int node)
{
return
from i in Enumerable.Range(0, Size)
where this.neighbours[node, i]
select i;
}
public int Size { get { return this.nodes; } }
}
Давайте рассмотрим этот код сверху вниз.
Я сделал класс закрытым (sealed). Это значит, я не думал над тем, какие детали реализации должны быть открытыми, чтобы произвольный класс мог эффективно расширять этот код. Я не вижу никаких сценариев, при которых этот код потребовал бы расширения. Согласно принципу YAGNI (You Ain't Gonna Need It – «Тебе это не понадобится»), я собираюсь проектировать код, не предназначенный для расширения. Безопасное и эффективное проектирование, предназначенное для повторного использования через наследования является сложной задачей и я не собираюсь идти на эти затраты без необходимости. И я не хочу давать необоснованные обещания; незакрытый класс обычно говорит пользователю: «давай, расширяй мою функциональность, я обещаю, что я не когда не нарушу твою работу». Я не хочу давать неявных обещаний, которые могут привести к проблеме хрупких базовых классов. (Компромисс: потенциальное повторное использование кода vs увеличение стоимости проектирования и сопровождения. ) Кроме того, «запечатывание» класса является критическим изменением (breaking change), а «распечатывание» – нет. Если я сейчас сделаю класс закрытым, я всегда смогу изменить это позднее. Если же я оставлю его открытым, я не смогу сделать его закрытым не нарушив работу некоторых производных классов.
Класс является внутренним (internal), а не открытым. Я хочу, чтобы этот класс являлся деталью реализации моего приложения, а не частью некоторой библиотеки общего назначения. Как мы увидим позднее, это решение оказывает влияние и на другие решения. (Компромисс: опять, потенциальное повторное использование кода против увеличения стоимости проектирования и сопровождения)
Класс называется Graph, а не, скажем, DirectedGraph. Если я когда-либо захочу создать класс UnidirectedGraph, мне придется изменять имя этого класса. Но поскольку в моем приложении это будет единственных класс, представляющий граф, я могу воспользоваться более простым именем. Обратите внимание, что я совершенно не хочу, чтобы имя класса отражало детали реализации, вот почему он не называется AdjacencyMatrixGraph. Я хочу, чтобы имя отражало то, чем этот класс является логически, а не то, как он реализован.
Этот класс не является обобщенным (generic). Каждый узел представляет собой целое число от 0 до size-1. Мы можем сделать его более сложным, позволив хранить произвольные данные в узле графа, изначально создав обобщенный «граф элементов типа T». Но в случае чего, мы всегда можем воспользоваться внешним ассоциативным массивом между целым числом в узле графа и другими данными. (Компромисс: опять, гибкость vs простота. А также, Принцип единой ответственности (SRP – Single ResponsibilityPrinciple ): класс представляет графы; пусть он решает одну задачу хорошо, вместо того чтобы хранить в нем еще и соответствие узлов и данных. )
Внутри граф использует массив для матрицы смежности. Мы хотим использовать простые и эффективные структуры данных. Создание структур данных, которые могут изменяться либо путем модификации, либо путем создания новой структуры данных, повторно использующей части старой структуры, добавляет гибкости и возможностей, но действует вопреки простоте и эффективности. (Компромисс: гибкость vs простота и эффективность) Для наших целей мы собираемся получить всю необходимую информацию для создания графа. Нам не нужны возможности добавления или удаления узлов из графа или возможность создания нового графа из текущего. (YAGNI) Поэтому я считаю оправданным использование изменяемой структуры данных – массива – для реализации полностью неизменяемой структуры данных с точки зрения пользователя. Если бы у нас был сценарий, как будут редактироваться графы, тогда, скорее всего, я бы выбрал другой подход для реализации неизменяемых графов.
Подход с массивом не эффективен, поскольку мы используем впустую большой объем памяти. Мы можем использовать массив BitArray. Однако, это добавит сложности в реализацию и существенно уменьшит скорость доступа к конкретным битам; гораздо быстрее просто получить булево значение из двумерного массива, по сравнению с битовыми операциями с объектом BitArray. До тех пока профайлер не покажет, что расход памяти в этом сценарии является слишком высоким, я буду использовать простую реализацию на основе массива bool вместо сложного решения на основе битового вектора. (Компромисс: простота кода vs эффективность vs эффективное использование памяти)
Кроме того, нам требуется выделить один большой двумерный массив, который должен быть одним непрерывным блоком памяти. При увеличении количества узлов, у менеджера памяти могут возникнуть проблемы с поиском такого большого фрагмента. Мы можем пожертвовать дополнительной памятью и воспользоваться решением на основе BitArray или массивом массивов (ragged array), что позволит выделять n блоков размера n, вместо одного блока, размером n * n. В этом случае менеджеру памяти будет проще удовлетворить запросы на выделение памяти, однако память для логически «близких» участков памяти будет разбросана по всему пространству памяти, что уменьшит локальность кэша (cache locality). (Компромисс: опять, простота кода vs эффективность выполнения vs эффективное использование памяти).
Сохранение размера является избыточным, поскольку мы можем вычислить размер путем получения размерностей массива. Если мы будем создавать миллионы графов и будем работать в условиях с ограниченным объемом памяти, тогда вполне разумно сэкономить эти четыре байта. Но мы этого не делаем. (Компромисс: поддержка избыточности vs простота кода vs эффективное использование памяти).
Все поля являются полями только для чтения, тем самым подчеркивая тот факт, что тип неизменяемый.
Информация передаваемая в конструктор содержит некоторую избыточность. Вместо передачи этого параметра в конструктор, мы можем вычислить количество узлов путем получения максимального целочисленного значения, найденного в списке edges. Вот наши варианты:
(1) Пройти последовательность edges дважды: один раз для поиска максимального элемента и второй раз для построения запроса. Это может быть неэффективно с точки зрения производительности; мы предпочитаем создавать системы, которые проходят определенную последовательность только один раз, поскольку это может повлечь за собой существенные накладные расходы при выполнении запроса к базе данных. Даже если накладные расходы выполнения запроса оказываются незначительными, для прохода последовательности дважды требуется время.
(2) Скопировать последовательность в список в памяти. Найти максимальные элемент в этой копии и затем создать граф из этой копии. Этот способ потенциально удваивает расход памяти и время выполнения.
(3) Потребовать от пользователя передать что-то еще вместе с произвольной последовательностью. Это перемещает проблему на пользователя и означает, что вся последовательность должна быть получена заранее (eagerly) в памяти, даже когда она может вычисляться отложено (lazily).
Итак, мы знаем, что мы собираемся затратить память, объема n на n и линейно растущее время обработки, так что, возможно, вопросы памяти и производительности не так уж важны. Но кажется разумным предполагать, что пользователь знает количество узлов графа заранее, поскольку он предоставляет список с ребрами и, таким образом, кажется разумным потребовать от него передачи этой избыточной информации. (Компромисс: эффективность vs избыточность)
Для представления edge мы используем тип Tuple вместо самодельного типа. Разумно представлять ребро в виде пары целых чисел; не существует никакой дополнительной семантики, присущей бизнес-области, помимо того, что ребро представляет собой пару узлов. Поэтому мы воспользуемся структурой данных общего назначения вместо бесполезного изобретения новой структуры, которая не добавит нам ничего нового. (Компромисс: простое повторное использование существующего кода vs четкое выражение семантики системой типов).
Обратите внимания, что мы не производим валидацию данных в конструкторе. Если пользователь укажет отрицательный или слишком большой размер, или передаст ребро, выходящее за пределы диапазона, то будут неприятности вроде исключения с сообщением о выходе за границы массива. Мы можем улучшить поведение системы при ее неправильном использовании путем генерации более точного типа исключения. Или мы можем предположить, что пользователь знает, что делает и сможет самостоятельно диагностировать проблему после получения неожиданного малопонятного исключения. Если бы я проектировал этот код для библиотеки базовых классов (BCL), то я бы обязательно воспользовался бы всеми средствами диагностики ошибок и уведомления о них, поскольку это является неотъемлемой частью любой профессионально разработанной библиотеки. Но, с другой стороны, в данном случае, когда этот код является деталью реализации некоторого аналитического инструмента, деталью, которая никогда не попадет в открытый доступ, то я просто оставлю ее именно в таком виде и буду знать, что за корректное использование этого кода будет отвечать человек, сопровождающий эту систему. (Компромисс: сложность кода vs «хорошее» уведомление о конкретных ошибках выхода за границы массива).
Функцию Neighbours (соседи) я написал в Канадском/Британском стиле. (Компромисс: корректность vs знание этой особенности американцами).
Обратите внимание, что конструктор использует цикл foreach, в то время как метод Neighbours возвращает объект запроса (query object). Это весьма спорное решение; использованием цикла я хотел подчеркнуть, что цикл – это механизм, обладающий побочным эффектом. Оператор цикла показывает это очень хорошо. С другой стороны, получение соседей конкретного узла скорее похоже на вопрос; здесь важна семантика и то, что этот код не содержит побочных эффектов. Синтаксис запросов подчеркивает это.
Самое интересное здесь то, что этот код очень прост; он практически ничего не делает, а мы уже приняли десяток решений, касающихся дизайна, включая тонкие компромиссные решения, которые окажут влияние на то, будет ли конкретный сценарий разумным образом обрабатываться этим классом.
В следующий раз: хранение набора возможных цветов.