Monitoring the Monitoring solution
What if OpsMgr is in a state where it is running but not working properly? Maybe your RMS is gray or the notification and alerting systems are down. How do you detect this condition so someone can take action to resolve it? Monitoring the console all day isn't very efficient. This is where monitoring the monitoring solution is required.
Below is just one approach to detecting these types of failure conditions. First, we generate an alert on an interval which triggers a notification. The alert auto-resolves and the notification triggers a vbscript that updates a log file on a share. An OpsMgr agent (watcher node) is used to read the log file on the share periodically. If the log file is out of date then the agent triggers an external process which notifies the appropriate administrators that OpsMgr is down. Here is a diagram of this design:
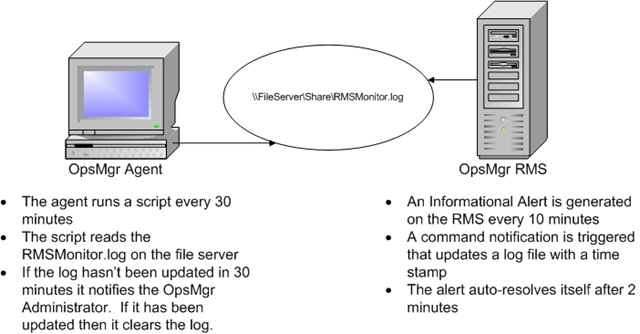
The way the agent notifies an administrator is configurable on the rule that runs the script on the agent. The script writes an event 9898 to the agent's Operations Manager event log. This event can be picked up by any other method that can be used to notify the appropriate administrator of a problem. Also, there is an optional parameter of a process that the script can run. This process could me something like sendmail, net send, createticket, etc... which would be used to notify the appropriate administrator of a problem. This is a good design for determining the health of a management group because it uses the alerting and notification systems and if both of these are working then chances are you're going to be alerted of any issues that occur.
I have created an example MP using this design and provided the steps below to use such an MP.
Step 1 - Create a share that the RMS and agent watcher can write to
Step 2 - Copy the RMSMonitor.vbs script to this share
Step 3 - If an alerting or notification program is to be used then copy this program to the share as well
Step 4 - Configure Command Notification passing the management group name as a parameter to the VBScript. The MG name is used so if you have multiple management groups you can use the same share
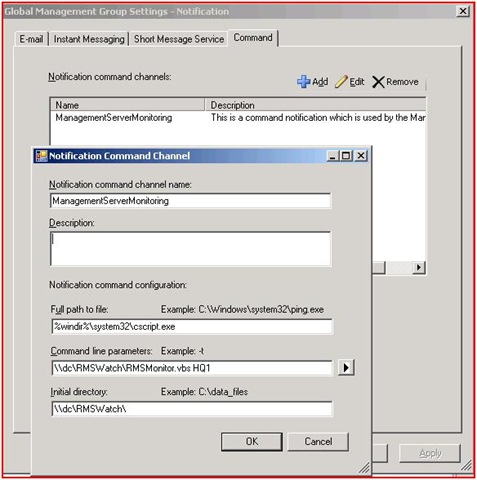
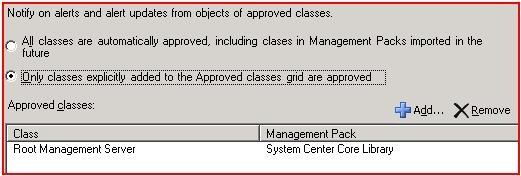
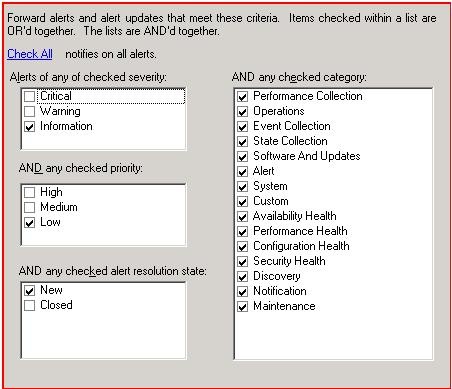
Step 5 - Import the MP (it contains one group, one monitor, and one rule with an override)
Step 6 - Add an agent (which will be the watcher node) to the RMSHealthAgent group
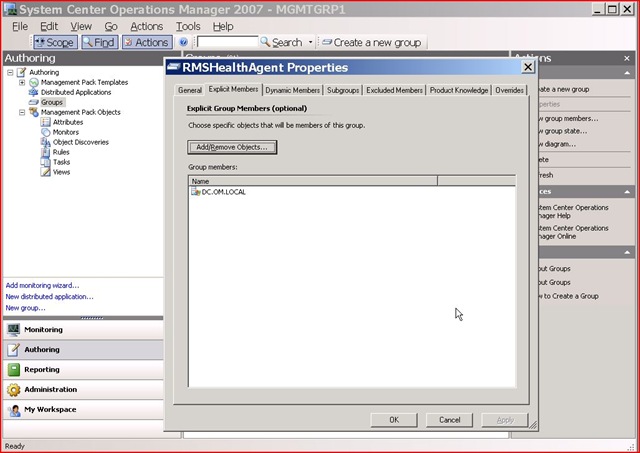
Step 7 - Ensure the "Alert Generator" monitor is working by checking for the <mgmtgroupname>RMSMonitor.log. It should contain a new line every 10 minutes.
Step 8 - Configure the "LogWatcher" Rule. Create an override for this rule so that it is enabled for the RMSHealthAgent group. Modify the script so that the proper parameters are passed (the share path, the mgmt group name-optional, and the application you would like to call to alert you - optional).
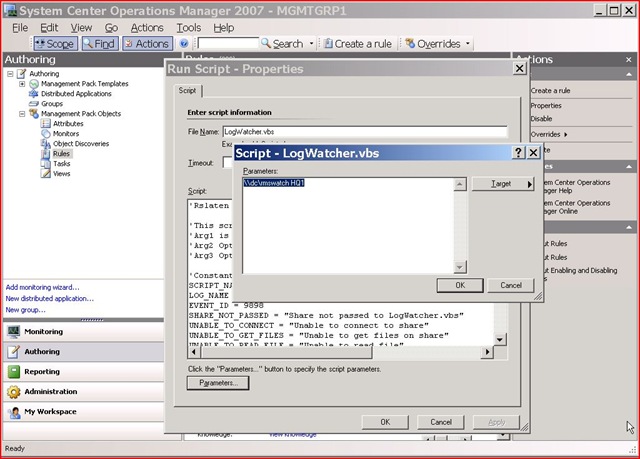
Step 9 - Confirm it is working properly. If the appropriate RMSMonitor.log is updated within 30 minutes this rule will simply clear the log to keep the size small. If it hasn't then it will update the log saying there is a problem, log an event 9898, and call the alerter program if one was configured. Make sure that the log is either empty or contains fewer than 3 or 4 lines. If it contains more then this rule isn't working properly.
Much of this example would probably need to be customized based on your environment. Things such as how often the alert is generated, how often the watcher node checks the log, how you get notified, changes in the script, etc...