SQL Server to Azure SQL Database data movement options and considerations with changing schemas and triggered refreshes
In this post we will look at the problem where we need to move the data at irregular intervals from an on-premise SQL instance with a constantly changing schema to an Azure SQL database. While there many different options in terms of performance and complexity we will look at some of the more common options and the performance characteristics of each of these.
(Azure Data Factory has been excluded from the comparison principle as currently it does not allow triggers to initiate a pipeline and although the SDK does allows schema changes, without a trigger this will produce problems in timing schema changes with the regular schedule. For completeness information on Data Factory performance can be found here /en-us/azure/data-factory/data-factory-copy-activity-performance)
The four methods that will be discussed in this post are
- Linked server
- SSIS
- BCP
- Azure SQL Data Sync 2.0
First the results then we will explain the strengths and weaknesses of each as well as the environment we used.
Below we see the speeds of all the methods. For the performance testing process we took processing times for a data move of 10.000, 100,000 and 1,000,000 records. Data was moved into empty heaps on the Azure SQL Database side. The data showed generally linear performance within an SKU so can be used as a rough reference for different workloads.
Note: The performance stats for linked servers are not shown in these results as running an import of just 10,000 records took around 780 seconds so was considered too slow a mechanism compared to the other methods.
Here we can see the speed of all the data transfer methods from on-premise to Azure SQL Database. The SKUs used were S0 = DTU10 and S3 = DTU100. On the S0 the DTUs were at 100% for all of the larger moves while the S3 was never maxed out suggesting we may have been able to have pushed more data in in parallel for even greater performance.
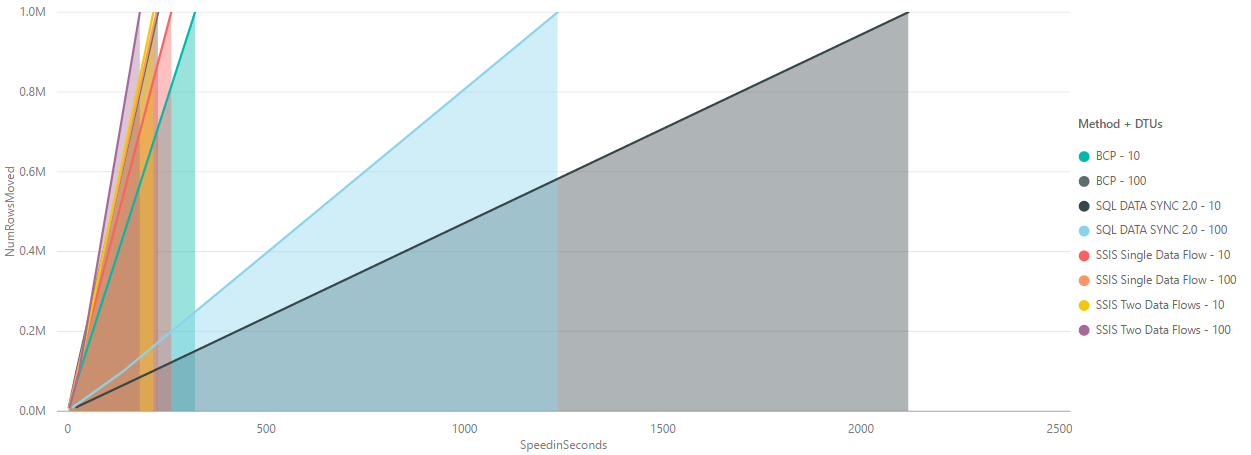
In the following we have stripped down the results to just show BCP and SSIS
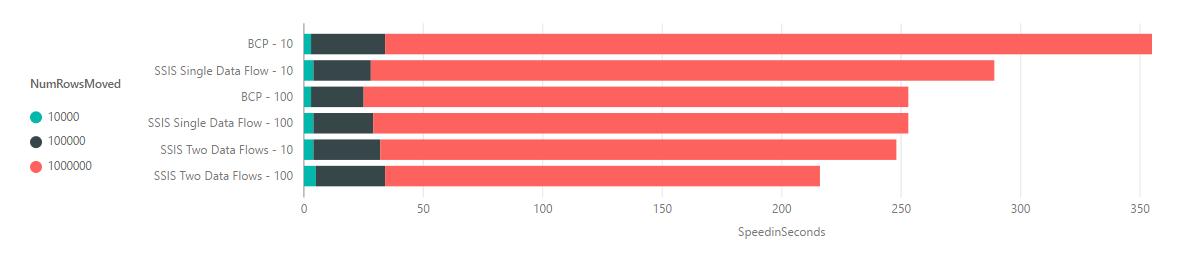
Now we have the results we will go through the strengths and weakness of each approach and how they can be set up.
Linked server
To set up a linked server an ODBC connection to the Azure SQL Database was created on the on-premise server. Then within the on-premise SQL Server a linked server referencing the ODBC connection as the remote server name needs to be created. Once created it is possible to talk to the Azure SQL Database from the on-premise SQL database via the four part naming convention or OPENQUERY.
Data may be uploaded as follows
INSERT INTO [SQLAzureODBC64].SQLTest.[dbo].Table1
SELECT * FROM Table1
Or
INSERT INTO OPENQUERY (SQLAzureODBC64, 'SELECT * FROM [dbo].Table1')
SELECT TOP 1 * FROM Table1
While comparatively a very slow way of moving data up to Azure SQL Database the linked server method does not consume much in the way of DTUs so will allow concurrent workloads during a load. Another advantage is that after creating the ODBC connection a solution can be developed just in TSQL without any need for access to the file system or the installations of any agents. Data movement may be triggered by ad hoc SQL or a stored procedure so any scheduling or trigger can be used to initiate a data movement.
BCP
BCP will run on any version of SQL including SQL Express. It is a command line tool so may be called via a .bat file from either Task Scheduler, SQL Agent or anything that has execute permissions on the file system. As it requires access to the source data file system it needs a lower level of security than using a linked server.
Schema changes are not possible with BCP. BCP expects a destination to exist so to script a schema change and a data move will require a combination of technologies. One way of doing this from the on-premise SQL side is to use a linked server via an ODBC connection to Azure SQL Database. Once the linked server is in place then OPENQUERY can be used to create or alter the destination schemas via a create statement. For example:
SELECT * FROM
OPENQUERY (SQLAzureODBC64, 'BEGIN TRY; CREATE TABLE tab1234 (ID INT); END TRY BEGIN CATCH; SELECT ERROR_MESSAGE(); END CATCH;')
So to make a schema change a stored procedure or application or PowerShell script would need to run an OPENQUERY statement first that will update or create a table. Then programmatically create a BCP batch file based on the new structure and then finally execute it.
The following example batch file will take the contents of a table and load into an Azure SQL database while recording start and end times to a log file.
@echo off
set logfile=E:\PoliceBCP\time.log
echo starting run at %date% %time% >> %logfile%
bcp PoliceSD.dbo.PoliceRecords out "E:\PoliceBCP\Policetxt.txt" -c -T
bcp SQLTest.dbo.PoliceBCP in "E:\PoliceBCP\Policetxt.txt" -c -U rob@sqlservername -S sqlservername .database.windows.net -P MyPassword
echo finishing run at %date% %time% >> %logfile%
BCP is a standard component of a SQL install and can be run on SQL Express.
As seen above in the sample script BCP is a two part process. The data is exported from SQL to a file and then pushed into Azure SQL Database from the file. Disk speed should not be too much of a concern as usually network or DTU level will be the bottleneck in a BCP.
Security may be a consideration as the BCP command will need the connection details of the Azure SQL Database every time it is run.
SSIS
SSIS requires at least a SQL Standard license to use so not a consideration where SQL Express is the only Edition. SSIS allows for better manageability and maintainability of data movement tasks and can be initiated either on a schedule or ad hoc.
With changing schemas SSIS packages may be programmatically generated. Tools such as BIML may be used for this https://www.varigence.com/biml
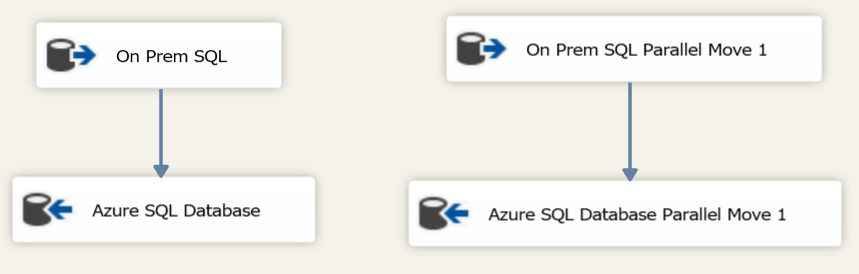
SSIS is generally more performant when running in parallel (as long as there are no bottlenecks such as limited server memory) so two tests were undertaken. One with a single process flow and one with two parallel process flows. In the latter process a final step of a table partition move would be required to bring all the data back together into a single table.
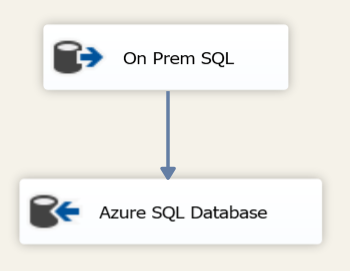
Single process flow
Dual process flow
Azure SQL Data Sync 2.0
Azure SQL Data Sync 2.0 recently released into public preview allows synchronization between Azure SQL Database and either another Azure SQL Database or an on-premise SQL database. It functions in either one way data movement from hub to member or member to hub; or bi directional data movement with conflict resolution. While this service allows data replication it can be used for initial batch data movement without the need to define the schema on the destination database.
It can be scheduled or can be triggered through the Azure SDK and PowerShell with the following command
Start-AzureRmSqlSyncGroupSync -ResourceGroupName $ResourceGroupName `
-ServerName $ServerName `
-DatabaseName $DatabaseName `
-SyncGroupName $SyncGroupName
Examples may be found here https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/sql-database/scripts/sql-database-sync-data-between-azure-onprem.md
Azure SQL Data Sync requires an agent to be installed on-premise but after this any data movement may be done via the Azure portal, SDK or PowerShell.
The agent running on an on-premise server facilitating data movement from a SQL Server database:
Results and Conclusions
Using a linked server is slow to move data into Azure SQL Database. It does however provide a mechanism to initiate schema changes from the on-premise side that can be used in combination with BCP. (Linked server to create/alter a table and the BCP to do the data flow heavy lifting.)
SSIS came out on top of performance and showed improvements when running in parallel so more scope here for tuning with additional parallel data flows to get ever better performance.
Azure SQL Data Sync 2.0 was not quite as fast for a bulk load of data but its real power comes in the ability to discern which records to move with the bonus of a conflict resolution engine. Great for scenarios where records within a table are being updated.
SSIS is the fasted method but cannot be run on just a SQL Express license. Also for changing schemas some development work is needed to create a package factory.
BCP is also extremely fast and works well when used with the linked server techniques, requires less work to create a custom solution based on changing schemas, however it is less elegant than an SSIS solution.
Finally here is all the collected data in a Power BI interactive report