Index Maintenance - Fragmentation should not be your only concern
Index fragmentation is not the only consideration when constructing an index maintenance plan. This article will look at other considerations that should be taken into account such as:
- Page fullness
- FILLFACTOR and PAD_INDEX
- The impact of Snapshot Isolation
The less fragmented an index is, the more performant it will be. Inserting records inside an index will cause fragmentation as will updating a variable length cell with a greater amount of data. Setting an index fill factor will help offset the chance of fragmentation from a page split but this comes at the cost of a larger number of pages in the index.
Choosing which indexes to rebuild as part of a maintenance plan is commonly done by looking for indexes over a certain overall fragmentation level, however, when writing maintenance plans page fullness should also be considered as well as intermediate level page fragmentation.
Page fullness
An index may be defragmented but still may not offer the greatest amount of performance if it is wasteful in how it is utilizing its pages.
To demonstrate the following script will create a narrow table and populate it.
It should be noted that in the examples given the default fillfactor is 100%. The number of pages will vary depending on the fill factor set.
CREATE TABLE RowDemo (ID INT NOT NULL IDENTITY (1,1), ID2 INT, CONSTRAINT [PKRowDemo] PRIMARY KEY (ID,ID2))
GO
INSERT INTO RowDemo (ID2) VALUES (1)
GO 10000
This table has 2 integers in it. An integer takes up 4 bytes so 2 integers equate to 8 bytes per row.
SELECT datalength(ID) + datalength(ID2) FROM RowDemo
Looking at the avg_record_size_in_bytes from SYS.DM_DB_INDEX_PHYSICAL_STATS we can see a size of 15 bytes
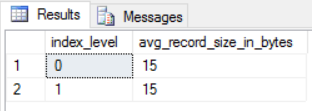
The true size of the row is 15 bytes as there is a 7 byte metadata overhead on each row. (4 bytes for the first integer column + 4 bytes for the second integer column + 7 bytes row metadata = 15 bytes per row.)
With 15 bytes per row we can fit on the leaf level of the clustered index around 454 records per page
SELECT index_level,
record_count /
page_count [Number of records per page]
FROM SYS.DM_DB_INDEX_PHYSICAL_STATS(DB_ID(),OBJECT_ID('RowDemo'),NULL,NULL,'DETAILED')
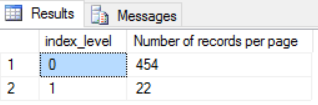
The number of rows in a page can be confirmed by looking at the first data page in detail
DECLARE @DBID INT = DB_ID()
DECLARE @ObjID INT = object_ID('RowDemo')
DECLARE @PageID INT
SELECT TOP 1 @PageID = allocated_page_page_id FROM sys.dm_db_database_page_allocations(@DBID, @ObjID, 1, 1, 'detailed')
WHERE page_type = 1 /*Data pages*/
DBCC TRACEON (3604)
DBCC PAGE (@DBID,1,@PageID, 2)
DBCC TRACEOFF (3604)
This shows the slot count (rows on a page) as 476
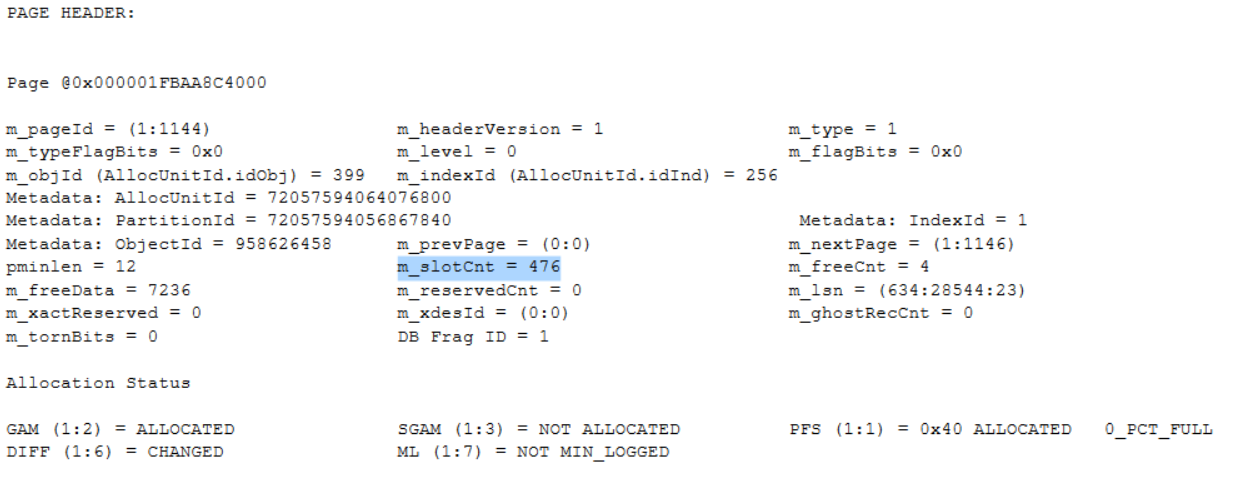
And the offset array confirms this

Looking at fragmentation it can be seen that the table is less than 5% fragmented
SELECT index_level,
page_count,
avg_fragmentation_in_percent,
avg_page_space_used_in_percent,
avg_record_size_in_bytes,
record_count
FROM SYS.DM_DB_INDEX_PHYSICAL_STATS(DB_ID(),OBJECT_ID('RowDemo'),NULL,NULL,'DETAILED')

Running conventional rebuild index scripts that look for a percentage of fragmentation over a reasonable threshold will not touch this index as there is no need to rebuild.
However, in a production environment data may be both added and removed from a table. The following example demonstrates the impact of deleting rows on the table and index by removing every other row from the table
DELETE FROM RowDemo WHERE ID % 2 = 1
The fragmentation is still less than 5 percent but the avg_page_space_used_in_percent has dropped to less than 50%.
SELECT index_level,
page_count,
avg_fragmentation_in_percent,
avg_page_space_used_in_percent,
avg_record_size_in_bytes,
record_count
FROM SYS.DM_DB_INDEX_PHYSICAL_STATS(DB_ID(),OBJECT_ID('RowDemo'),NULL,NULL,'DETAILED')

This index is now less performant than it could be as it is 22 pages in size but only using half the page space. A maintenance plan looking to rebuild indexes over a certain threshold of fragmentation would not pick this up as the fragmentation has not changed.
Rebuilding the index
ALTER INDEX [PKRowDemo] ON RowDemo REBUILD
The pages are now compacted again and the number of pages used is halved
SELECT index_level,
page_count,
avg_fragmentation_in_percent,
avg_page_space_used_in_percent,
avg_record_size_in_bytes,
record_count
FROM SYS.DM_DB_INDEX_PHYSICAL_STATS(DB_ID(),OBJECT_ID('RowDemo'),NULL,NULL,'DETAILED')

This then becomes an optimal index again as it is taking up less space on disk, and using less memory. Any scans needed will use fewer pages to attain the same result as before.
The following script identifies indexes that have a fragmentation greater than 20% and less than 90% space per page of available (after taking into account the fill factor):
SELECT OBJECT_NAME(I.object_id) Tablename,
I.name,
I.type_desc,
P.partition_number,
P.page_count,
P.avg_page_space_used_in_percent,
P.index_depth,
P.index_level,
P.avg_fragmentation_in_percent,
P.fragment_count,
P.avg_fragment_size_in_pages,
P.avg_record_size_in_bytes,
P.record_count
FROM SYS.DM_DB_INDEX_PHYSICAL_STATS(DB_ID(),NULL,NULL,NULL,'DETAILED') AS P
INNER JOIN sys.indexes AS I ON P.object_id = I.object_id AND P.index_id = I.index_id
WHERE P.index_level < P.index_depth -1 /*Ignore all root level pages*/
AND (P.avg_page_space_used_in_percent <(ISNULL(NULLIF(I.fill_factor, 0), 100) * 0.85)
/*Where space used is less 85% of total after fill factor*/
OR avg_fragmentation_in_percent > 20) /*Where fragmentation is greater than 20%*/
FILLFACTOR and PAD_INDEX
The FILLFACTOR of an index allows records to be inserted or enlarged inside a page without a page split occurring. There is a trade off in so far as the lower the fill factor the larger the number of pages so the more pages are accessed in a scan.
Unless PAD_INDEX has been set space is left for additional data only at the leaf level. Without PAD_INDEX an index fragmentation may be acceptable at the leaf level but still be fragmented in the intermediate levels.
The impact of Snapshot Isolation
Enabling a system to use Snapshot isolation or setting up a readable secondary can cause fragmentation issues and reduce the performance of some indexes, especially on narrow tables.
When a database is enabled to use snapshot isolation SQL Server will add more bytes at the end of each row to allow the row versioning. This consists of 6 bytes to store the transaction sequence and 8 bytes to store the row ID. This will add an additional 14 bytes to each row, which on a narrow table will increase the size considerably. With a table of 15 bytes (4 bytes for the first integer column + 4 bytes for the second integer column + 7 bytes row metadata) each row will become almost double at 29 bytes per row. When this happens the pages will not be able to fit as many rows so fragmentation will occur.
After the last delete and index rebuild from the previous example table the table had 11 pages. This code will enable snapshot isolation and as it is an existing table perform an update to see the effect on the pages.
ALTER DATABASE PageDemo SET ALLOW_SNAPSHOT_ISOLATION ON
UPDATE R
SET ID2 = ID2
FROM RowDemo AS R
SELECT page_count,
avg_page_space_used_in_percent,
index_depth,
index_level,
avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
avg_record_size_in_bytes,
record_count
FROM SYS.DM_DB_INDEX_PHYSICAL_STATS(DB_ID(),OBJECT_ID('RowDemo'),NULL,NULL,'DETAILED')

It can be seen here that the table has now gone from 11 pages to 21 and the table is now 95% fragmented. Of course the index can be rebuilt to remove the fragmentation, but our narrow table has now doubled in size potentially affecting performance of queries that need to scan it.
When a readable secondary is used in an Always On Availability Group the secondary will run all queries in snapshot isolation mode to avoid any locking issues. In an Availability Group the schemas must match. Hence the additional bytes at the end of each row must exist on both the primary and the secondary. When enabling a readable secondary make sure to take the fragmentation into consideration.