Architecting a Big Data Project in Azure
The aim of this post is to give a very brief overview of the technologies in Azure that can comprise a Big Data architecture and to help the reader understand the options out there.
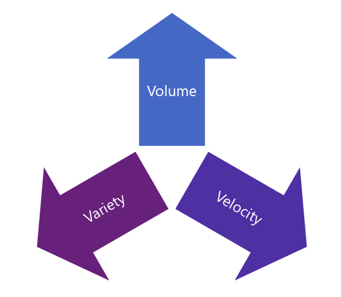
With the new data explosion over the last few years new methods and technologies have been developed to deal with data that is either to large; or has too much variety; or is coming in too quick to be dealt with in a traditional architecture. These three concerns are commonly called the three Vs. (Velocity, Volume and Variety). Any one of these can be a reason to consider Big Data. Big Data does not just have to be about petabytes of data.
Big Data warehouse projects differ from traditional data warehouse projects in so far as there are many more decision points. With traditional projects the technologies and how they plug into each other are tried and tested and, when an architecture has been decided on, it can easily be evaluated against previous projects.
Big Data projects are different. When looking at Big Data offerings there is a plethora of options due to the open source nature of the landscape. New projects are constantly being developed while older projects are being abandoned in favour of new ways of doing things. As new technologies develop with new ways of doing things some parts of functionality can overlap, converge or duplicate with each other’s feature sets.
With this in mind it can be a difficult to choose a good solution. Questions arise such as. Why pick one over the other? Will a solution suddenly become obsolete? Is the project going to run into a dead end or stay current throughout its lifetime?
The range of Big Data technologies in Azure takes a lot of the pain points away. While it is possible to spin up any technology with a VM in Azure, as far as PaaS services are concerned the decisions are between only stable, industry recognized Big Data technologies with a long life span and the extensibility needed to stay flexible in the modern data climate.
While a lot of the pain has been taken away there are still decision points to be made as some technologies have similar features.
The following diagram shows the main technologies that can be involved in a Big Data architecture in Azure: 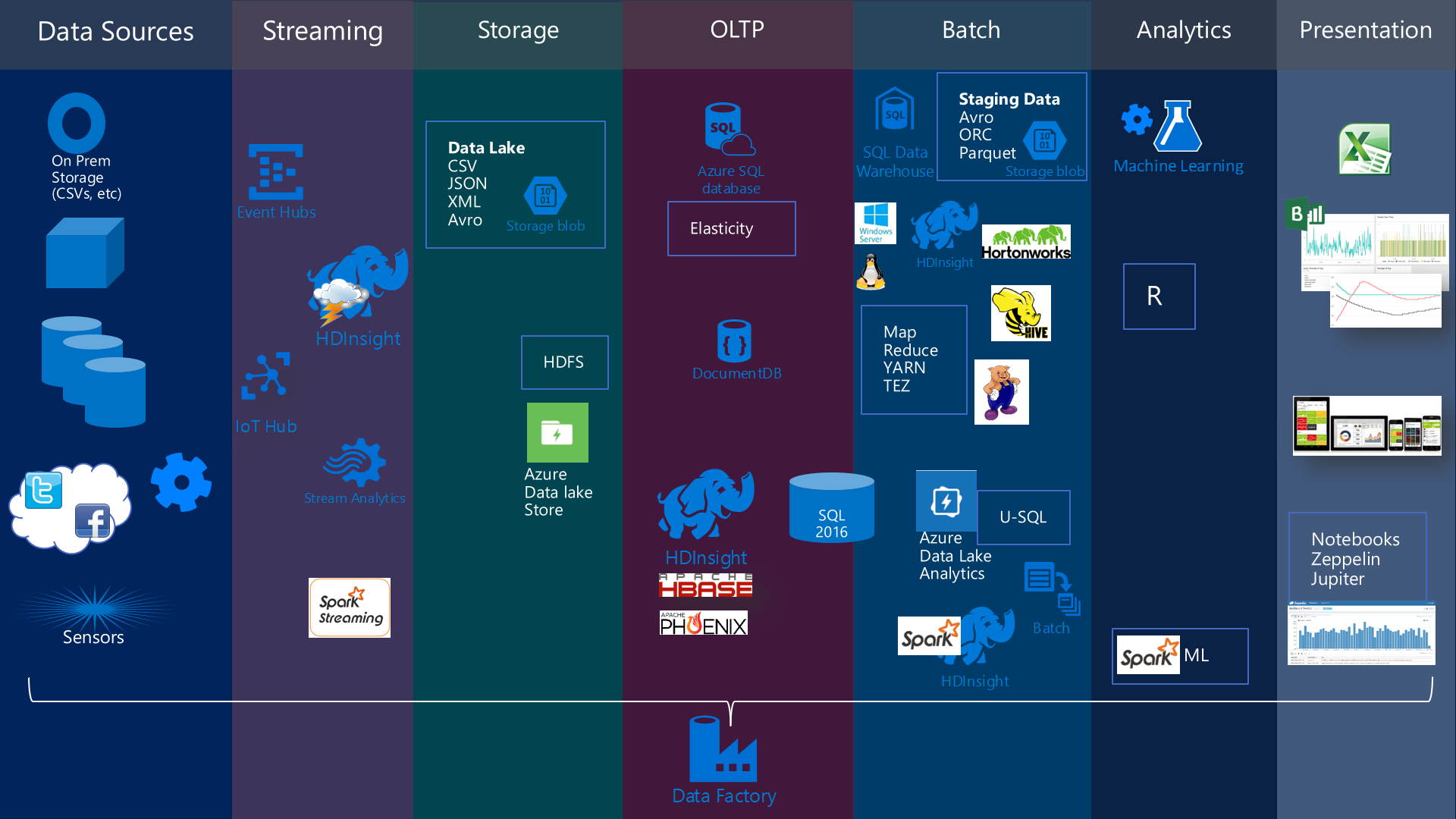
These technologies have been split into sections to better understand their main feature sets and how they relate to each other.
Data sources
Data can come from anywhere, streaming from sensors, applications, or public services such as twitter; or from more traditional database services; or anywhere in-between. There is no need to dwell on all the differences but suffice to say if it can spit out data it can be consumed in Azure.
Streaming technologies
As the name suggests streaming technologies deal with fast moving stream data. These range from event queues such as Event Hub or the IoT suite, to technologies that can manipulate the data such as Storm, Stream Analytics or Spark Streaming. Similar in nature these all have their own strengths and weaknesses.
Azure Stream Analytics allows simple data transformation in stream with SQL style language with the ability to add machine learning in a scalable environment. Not as extensible as other streaming technologies but very easy to get started with and very approachable for anyone with a data development background.
Storm and Spark are open source technologies that manipulate the data though languages such as .Net, Java and Scala. Storm and Spark are more extensible than Stream Analytics but take much more time to develop.
Storage
There are two main storage technologies available in Azure, blob storage and Azure Data Lake Storage. Blob Storage can be used to create conceptual data lakes and staging data repositories. Blob storage has some limitations on throughput at massive scale due to contention and size of data (the maximum file size is 1TB and there is a maximum of 50PB per subscription). Azure Data Lake Storage removes these limitations. Azure Data Lake Storage is HDFS so can easily integrate into other Big Data services and technologies.
OLTP
SQL in IaaS and SQL in PaaS (Azure SQL Database) are both relational database systems. Industry proven and extremely fast, especially with the inclusion of inMemory OLTP technologies. SQL can scale up and SQL in PaaS can scale both up and out. The main downside is that data needs to have a string schema.
DocumentDB is a NOSQL database that can be used for JSON storage with the ability to reduce or increase the ACID properties. It offers an easy way for JSON developers to persist JSON without manipulating it into a relational database or other such system.
HBase is available as a service as part of HDInsight. HBase is a massively scalable database that consists of tables in key value pairs. As a table simply holds a key and a chararray any style of data may be placed into the tables, without too much consideration on schema or data types. Tables automatically scale across nodes and provide very fast OLTP. They do not have the rich feature set of SQL Server but if storing data that does not fit into a strong schema design then this is a good choice. HBase is used by Facebook to provide a fast and robust scalable solution.
Batch
There are several options for batch processing in Azure
HDInsight is a PaaS offering consisting of multiple VMs running the Hortonworks version of Hadoop. A cluster size can be defined then spun up for a period of time to perform some computational activates with languages such as Hive or Pig. As with many Azure technologies compute is separated from storage so a cluster can be destroyed without damaging the source data or an transformations to that data that have been made. This allows different scales to be used at different times and a more cost effective way of processing data. 
HDInsight provides technologies for batch such as Spark, that can be developed in Scala; or Hadoop that can be developed with Hive and Pig. Hive being a SQL style language and Pig being mainly used for transformation work.
Azure Data Lake Analytics provides a service that allows large scale and schema free data to be queried. It uses a new language called U-SQL that combines C# and SQL. Other languages will be added in the future. It is always available to receive job submissions and scale can be decided on submission. This gives it an advantage over HDInsight which needs to be spun up prior to usage.
Azure batch can also be used to scale out an application to run on a number of IaaS machines. A VM can be started up, a processing application uploaded, some data pushed up and results received. This can then be scaled out to thousands of VMs. While it is very extensible as custom applications can be used, development time will generally be longer than using the other technologies for data processing.
Azure SQL Data Warehouse provides a hybrid of strong schema with the ability to interact with loose schema though a language called Polybase.
Analytics
Options available out of the box are R server. R is a statistical programming language which has strengths in creating machine learning models and visualize results.
Spark has a machine learning model that can be leveraged to compliment the Sparks other streaming and batch functionality.
Microsoft Azure Machine Learning is a service that makes designing and running machine learning models very approachable with a low learning curve. It also has the advantage that models can be turned into training or production web services with a few simple clicks.
Presentation
In the Microsoft stack more traditional systems for analysing data can be used such as Excel.
PowerBI offers an approachable interface to investigate and present data. It also provides custom visualizations and streaming dashboards in a visually rich environment. It is extensible and can be embedded in line of business applications.
Datazen is available currently as part of SQL Enterprise edition but will be combining with SQL 2016 SSRS. It provides a mobile first experience for dashboarding with rich visualizations.
Spark and Microsoft Azure Machine Learning also provides notebooks for data scientist to play with and understand the data graphically.
Data Orchestration
Azure Data Factory is a technology that orchestrates data movement and initiates certain actions between the different technologies in Azure. It is similar in concept to SSIS but without actually touching the data itself. For example, it can orchestrate the movement of data from an on premise SQL server, to blob storage, spin up an HD insight cluster, run some Hive jobs in that cluster, perform some machine learning and then push the final results out into an Azure SQL Database.