SharePoint Performance Monitoring - Performance Counter für System und Netzwerk
SharePoint Adventskalender - 12. Türchen
Performance Tuning - Performance Monitoring - Best-Practices für SP-SQL-Konfigurationen - BLOB Management - Backup & Recovery
-------------------------------------------------------------
Am letzten Tag für die SharePoint Performance Counter schauen wir uns zwei System und vier Netzwerk Messgrößen an. Die System-Indikatoren sind dabei zusätzliche Checks für den den Prozesser und die Netzwerkmessgrößen können – wie der Name schon sagt – einen möglichen Engpass am Netzwerk identifizieren.
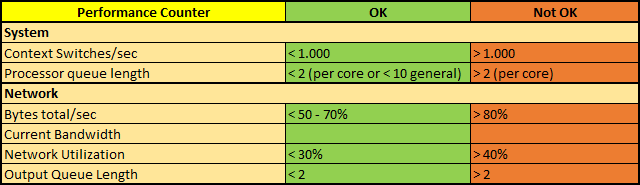
System:
Context Switches/sec
Kontextwechsel treten auf, wenn der Prozessor zwischen zwei Threads wechselt. Dies kann z.B. geschene, wenn ein Thread, der eine höhere Priorität hat als der aktuell zu verarbeitende Thread hat, bereit für die Bearbeitung durch den Prozessor ist. Eine hohe Rate ist ein Zeichen dafür, dass sich viele gleichrangige Threads um die Bearbeitung im prozessor „streiten“.
Eine Anwendung (Application), besteht aus einem oder mehreren Prozessen. Ein Prozess ist einfach betrachtet das auszuführende Programm für die Anwendung. Also im Prinzip der Worker-Prozess (w3wp.exe) für SharePoint. Ein oder mehrere Threads, welche die Basiseinheit des Betriebssystems darstellen, die dem Prozessor zugeweisen werden können, laufen dann im Kontext eines Prozesses und erledigen die eigentliche Arbeit. In diesem Zusammenhang wird also deutlich, dass viele Kontextwechsel die Performance des Servers negativ beeinflusst. Obwohl auch ein Problem mit der Netzwerkkarte oder eines Gerätetreibers die Ursache für hohe Kontestwechsel sein können (siehe auch 9. Türchen über Privilege und User Mode Anfragen), so zeigt dieser Indikator auch auch, dass SharePoint einfach extrem viele Aufgaben abzuarbeiten hat, die der Prozesser nicht mehr bedienen kann. Ein Messwert von mehr als 1.000 Wechsel ist nicht optimal und deutet so ein Szenario an. Ein besserer Prozessor mit auch mehreren Kernen kann das Problem lösen.
Processor queue length
Prozessor-Warteschlangen entstehen, wenn neue Anfragen bereit sind, bearbeitet zu werden, aber die CPU aktuell mit noch anderen Anfragen voll beschäftigt ist. Ähnlich wie bei der Warteschlange, auf die Festplatten schreiben zu können (siehe 10. Türchen, Avg Disk Queue Length), ist bereits ein Wert von mehr also 2 (pro Kern) schlecht. Zufällig eintreffende Anfragen mit hoher Priorität oder unerwartet lang andauernde Threads können temporäre Warteschlangen entstehen lassen. Sind die Werte aber dauerhaft über dem Grenzwert, dann kann der Prozessor einfach nicht mehr alle Anfragen zeitnah abarbeiten. Die einfachste Lösung ist ein zweiter Server, den man in einem Load-Balancer Verbund dazu schaltet. Andere Ursachen können auch ein bestimmter „hängender“ Prozesse sein, ein schlechter Gerätetreiber mit vielen Kernerl-Mode Anfragen. Analysieren Sie also genau, welche Ursachen bei Ihnen eine dauerhafte Prozessor-Warteschlangen haben entstehen lassen.
Netzwerk:
Bytes total/sec
Dieser Indikator gibt an, wie viele Daten die Netzwerkkarte(n) insgesamt pro Sekunde verarbeiten, also die Summe aus erhaltenen und gesendeten Bytes. Ein dauerhafter Wert von mehr als 80% der angegebenen Kapazität der Netzwerkkarte, deuten auf einen Engpass hin. Ganz schnell kann man so nämlich am absoluten Limit sein und so verhindert die NIC (Network Interface Card), dass de Server sein volles Potential ausschöpfen kann. Achten Sie aber auch im Detail darauf, ob die Einzelgrößen, also nur das Empfangen oder nur das Senden, auffällig sind. Ein ein weiterer kleiner Tipp: Die NIC Kapazitäten werden in Bit angegeben, dieser Indikator wird hingegen in Byte gemessen.
Current Bandwidth
Diese Messgröße gibt einfach die geschätzte maximale Bandbreite der Netzwerkkarte an. Dies sollte der Kapazitätenangabe für die NIC entsprechen. Also eine NIC mit 1 Gbps sollte auch bei diesem Indikator genau diese 1 Gbps anzeigen. Ist dies geringer, haben Sie nicht bekommen, wofür Sie bezahlt haben.
Network Utilization
Bei der Netzwerknutzung kommen die ersten beiden Indikatoren zusammen. Sie stellt also die insgesamt verarbeiteten Bytes ins Verhältnis zur möglichen Bandbreite. Mehr als 40% Ausnutzung kann bereits nicht mehr optimal sein. Eine hohe Nutzung deutet nämlich an, dass viele Daten und Informationen verarbeitet und gesendet werden müssen. Geschicht dies im selben (Teil-) Netzwerk, so kann es zu Kollisionen kommen, wenn gleichzeit zwei Stationen eines Netzwerksegments versuchen, zu senden. Diese Paketkollisionen führe zu einer Verzögerung der Sendung, da ein erneuter Sendeversuch gestartet werden muss.
Die Grenzwerte sind hier aber mit Vorsicht zu genießen. Sind besipielsweise Server und Netze mit Switches und/oder Netzwerkbrücken verbunden, die auf einer höheren OSI-Ebene arbeiten, können gleichzeitig gesendete Pakete weitgehend minimiert werden. Denn in diesem Falle ist der Server meist direkt mit dem nächsten Switch verbunden und nur ein gleichzeitiger Sendeversuch dieser beider Stationen kann zu einer Kollision führen. Bei gleich hohen Sende- und Empgangswerten kann dies dennoch häufiger der Fall sein und dies ist schon mehrheitlich bei mehr als 40% Auslastung der Fall. Dedizierte Netzwerke, z.B. für Backup-Vorgänge, prinzipiell höhere Netzwerkkapazitäten aber auch Netzwerkkonfigurationen lösen dieses Problem.
Output Queue Length
Die Länge der Warteschlange für Datenpakete, die gesendet werden sollen, ist äquivalent zu den Warteschlangen bei Prozessor und Festplatte. Kommt es zu so einer Warteschlange, hat die Netzwerkkarte einfach nicht genug Leistung, um die zu sendenen Anfragen zeitnah abzuarbeiten. Auch hier ist ein dauerhafter Wert von über 2 nicht optimal.
Viel Spaß beim „SharePointen“!
-------------------------------------------------------------
Weitere Türchen:
- 1. Türchen: SharePoint Performance Tuning - Cluster Größe der SQL Festplatten
- 2. Türchen: SharePoint Performance Tuning - SQL Speicherzuweisung
- 3. Türchen: SharePoint Performance Tuning - SQL MAXDOP
- 4. Türchen: SharePoint Performance Tuning - SQL AutoGrowth-Einstellungen
- 5. Türchen: SharePoint Performance Tuning - SQL Datenbanken vor konfigurieren
- 6. Türchen: SharePoint Performance Tuning - SQL TempDB Einstellungen
- 7. Türchen: SharePoint Performance Tuning - Der Papierkorb
- 8. Türchen: SharePoint Performance Tuning - Warm Up Skripte
- 9. Türchen: SharePoint Performance Monitoring - Performance Counter für den Prozessor
- 10. Türchen: SharePoint Performance Monitoring - Performance Counter für Speicherlaufwerke
- 11. Türchen: SharePoint Performance Monitoring - Performance Counter für den Arbeitsspeicher
- 12. Türchen: SharePoint Performance Monitoring - Performance Counter für System und Netzwerk
- 13. Türchen: SharePoint Configuration Best Practices - SQL Alias
- 14. Türchen: SharePoint Configuration Best Practices - Benamte SQL Instanzen und dedizierte Ports
- 15. Türchen: SharePoint Configuration Best Practices - Super User und Super Reader
- 16. Türchen: SharePoint Configuration Best Practices - Distributed Cache Service
- 17. Türchen: SharePoint Configuration Best Practices - Request Management Service
- 18. Türchen: SharePoint BLOB Management - BLOB Cache
- 19. Türchen: SharePoint BLOB Management - BLOB Storage (EBS und RBS)
- 20. Türchen: SharePoint BLOB Management - Shredded Storage
- 21. Türchen: SharePoint BLOB Management - Shredded Storage und RBS “Better Together”
- 22. Türchen: SharePoint BLOB Management - Archivierung
- 23. Türchen: SharePoint Backup & Recovery - Von RTO, RPO und RLO zum fertigen Disaster Recovery Plan (1/2)
- 24. Türchen: SharePoint Backup & Recovery - Von RTO, RPO und RLO zum fertigen Desaster Recovery Plan (2/2)