Advanced Content Enrichment in SharePoint 2013 Search
Microsoft re-engineered the search experience in SharePoint 2013 to take advantage of the best capabilities from FAST plus many new capabilities built from the ground up. Although much has been said about the query side changes of search (result sources, query rules, content by search web part, display templates, etc), the feed side of search got similar love from Redmond. In this post I’ll discuss a concept carried over from FAST that allows crawled content to be manually massaged before getting added to the search index. Several basic examples of this capability exist, so I’ll throw some advanced solution challenges at it. The solution adds a sentiment analysis score to indexed social activity as is outlined in the video below.
[View:https://www.youtube.com/watch?v=8xJ86DYqYlE]
The content enrichment web service (CEWS) callout is a component of the content processing pipeline that enables organizations to augment content before it is added to the search index. CEWS can be any external SOAP-based web service that implements the IContentProcessingEnrichmentService interface. SharePoint can be configured to call CEWS with specific managed properties and (optionally) the raw binary file. CEWS can update existing managed property values and/or add completely new managed properties. The outputs of this enrichment service get merged into content before it is added to the search index. The CEWS callout can be used for numerous data cleansing, entity extraction, classification, and tagging scenarios such as:
- Perform sentiment analysis on social activity and augment activity with a sentiment score
- Translate a field or folder structure to a taxonomy term in the managed metadata service
- Derive an item property based on one or more other properties
- Perform lookups against line of business data and tag items with that data
- Parse the raw binary file for more advanced entity extraction
The content enrichment web service is a synchronous callout in the content processing pipeline. As such, complex operations in CEWS can have a big impact on crawl durations/performance. An additional challenge exists in the enrichment of content that hasn’t changed (and thus doesn’t get crawled). An item only goes through the content processing pipeline during full crawls or incremental/continuous crawls after the item is updated/marked dirty. When only the enriched properties need to change, a full crawl is the only out of the box approach to content enrichment.
The solution outlined in this post addresses both of these challenges. It will deliver an asynchronous CEWS callout and a process for marking an indexed item as dirty so it can be re-crawled without touching/updating the actual item. The entire solution has three primary components…a content enrichment web service, a custom SharePoint timer job for marking content in the crawl log for re-crawl, and a database to queue asynchronous results that other components can reference.
| High-level Architecture of Async CEWS Solution |
|---|
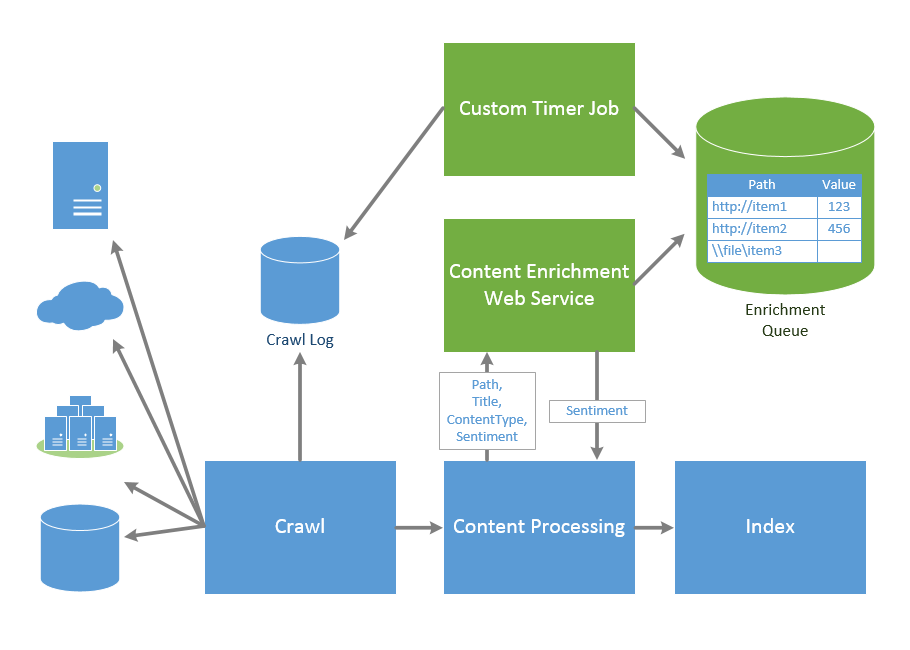 |
Enrichment Queue (SQL Database)
Because of the asynchronous nature of the solution, operations will be running on different threads, some of which could be long running. In order to persist information between threads, I leveraged a single-table SQL database to queue asynchronously processed items. Here is the schema and description of that database table.
| Id | integer identity column that serves as the unique id of the rows in the database |
| ItemPath | the absolute path to the item as provided by the crawler and crawl logs |
| ManagedProperty | the managed property that gets its value from an asynchronous operation |
| DataType | the data type of the managed property so we can cast value correctly |
| CrawlDate | the date the item was sent through CEWS that serves as a crawl timestamp |
| Value | the value derived from the asynchronous operation |
Content Enrichment Web Service
As mentioned at the beginning of the post, the content enrichment web service callout is implemented by creating a web service that references the IContentProcessingEnrichmentService interface. There are a number of great example of this online, including MSDN. Instead, this post will focus on calling asynchronous operations from this callout. The main objective of making the CEWS callout asynchronous is to prevent the negative impact a long running process could have on crawling content. The best way to do this in CEWS is to collect all the information we need in the callout, pass the information to a long running process queue, update any items that have values ready from the queue, and then release the callout thread (before the long running process completes).
| Process Diagram of Async CEWS |
|---|
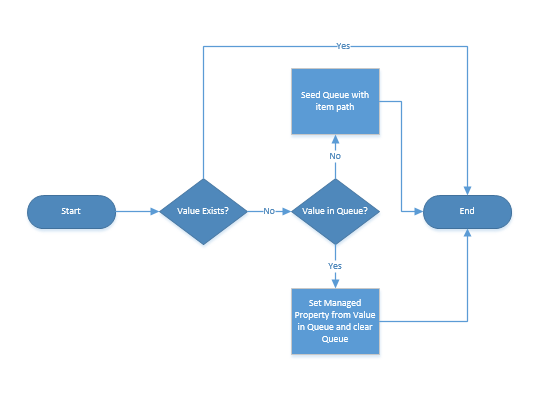 |
Below is the callout code in its entirety. Note that I leveraged the entity framework for connecting to my enrichment queue database (ContentEnrichmentEntities class below):
Content Enrichment Web Service
using Microsoft.Office.Server.Search.Administration;using Microsoft.Office.Server.Search.ContentProcessingEnrichment;using Microsoft.Office.Server.Search.ContentProcessingEnrichment.PropertyTypes;using Microsoft.SharePoint;using System;using System.Collections.Generic;using System.Configuration;using System.IO;using System.Linq;using System.Net;using System.Runtime.Serialization;using System.ServiceModel;using System.Text;using System.Threading; namespace ContentEnrichmentServices{ public class Service1 : IContentProcessingEnrichmentService { private const int UNEXPECTED_ERROR = 2; public ProcessedItem ProcessItem(Item item) { //initialize the processedItem processedItem.ErrorCode = 0; processedItem.ItemProperties.Clear(); try { //only process items where ContentType:Item var ct = item.ItemProperties.FirstOrDefault(i => i.Name.Equals("ContentType", StringComparison.Ordinal)); if (ct != null && ct.ObjectValue.ToString().Equals("Item", StringComparison.CurrentCultureIgnoreCase)) { //get path and use database to process async enrichment data var path = item.ItemProperties.FirstOrDefault(i => i.Name.Equals("Path", StringComparison.Ordinal)); var title = item.ItemProperties.FirstOrDefault(i => i.Name.Equals("Title", StringComparison.Ordinal)); var sentiment = item.ItemProperties.FirstOrDefault(i => i.Name.Equals("Sentiment", StringComparison.Ordinal)); if (path != null && title != null) { using (ContentEnrichmentEntities entities = new ContentEnrichmentEntities(ConfigurationManager.ConnectionStrings["ContentEnrichmentEntities"].ConnectionString)) { //try to get the item from the database string pathValue = path.ObjectValue.ToString(); var asyncItem = entities.EnrichmentAsyncData.FirstOrDefault(i => i.ItemPath.Equals(pathValue, StringComparison.CurrentCultureIgnoreCase)); if (asyncItem != null && !String.IsNullOrEmpty(asyncItem.Value)) { //add the property to processedItem Property<decimal> sentimentProperty = new Property<decimal>() { Name = asyncItem.ManagedProperty, Value = Convert.ToDecimal(asyncItem.Value) }; processedItem.ItemProperties.Add(sentimentProperty); //delete the async item from the database entities.EnrichmentAsyncData.DeleteObject(asyncItem); } else { if (sentiment != null && sentiment.ObjectValue != null) processedItem.ItemProperties.Add(sentiment); if (asyncItem == null) { //add to database EnrichmentAsyncData newAsyncItem = new EnrichmentAsyncData() { ManagedProperty = "Sentiment", DataType = "System.Decimal", ItemPath = path.ObjectValue.ToString(), CrawlDate = DateTime.Now.ToUniversalTime() }; entities.EnrichmentAsyncData.AddObject(newAsyncItem); //Start a new thread for this async operation Thread thread = new Thread(GetSentiment); thread.Name = "Async - " + path; var data = new AsyncData() { Path = path.ObjectValue.ToString(), Data = title.ObjectValue.ToString() }; thread.Start(data); } } //save the changes entities.SaveChanges(); } } } } catch (Exception) { processedItem.ErrorCode = UNEXPECTED_ERROR; } return processedItem; } /// <summary> /// Called on a separate thread to perform sentiment analysis on text /// </summary> /// <param name="data">object containing the crawl path and text to analyze</param> public static void GetSentiment(object data) { AsyncData asyncData = (AsyncData)data; HttpWebRequest myRequest = (HttpWebRequest)HttpWebRequest.Create("https://text-processing.com/api/sentiment/"); myRequest.Method = "POST"; string text = "text=" + asyncData.Data; byte[] bytes = Encoding.UTF8.GetBytes(text); myRequest.ContentLength = bytes.Length; using (Stream requestStream = myRequest.GetRequestStream()) { requestStream.Write(bytes, 0, bytes.Length); requestStream.Flush(); requestStream.Close(); using (WebResponse response = myRequest.GetResponse()) { using (StreamReader reader = new StreamReader(response.GetResponseStream())) { string result = reader.ReadToEnd(); using (ContentEnrichmentEntities entities = new ContentEnrichmentEntities(ConfigurationManager.ConnectionStrings["ContentEnrichmentEntities"].ConnectionString)) { //try to get the item from the database var asyncItem = entities.EnrichmentAsyncData.FirstOrDefault(i => i.ItemPath.Equals(asyncData.Path, StringComparison.CurrentCultureIgnoreCase)); if (asyncItem != null && String.IsNullOrEmpty(asyncItem.Value)) { //calculate sentiment from result string neg = result.Substring(result.IndexOf("\"neg\": ") + 7); neg = neg.Substring(0, neg.IndexOf(',')); string pos = result.Substring(result.IndexOf("\"pos\": ") + 7); pos = pos.Substring(0, pos.IndexOf('}')); decimal negD = Convert.ToDecimal(neg); decimal posD = Convert.ToDecimal(pos); decimal sentiment = 5 + (-5 * negD) + (5 * posD); asyncItem.Value = sentiment.ToString(); entities.SaveChanges(); } } } } } } private readonly ProcessedItem processedItem = new ProcessedItem() { ItemProperties = new List<AbstractProperty>() }; } public class AsyncData { public string Path { get; set; } public string Data { get; set; } }} |
The content enrichment web service is associated with a search service application using Windows PowerShell. The configuration of this service has a lot of flexibility around the managed properties going in and out of CEWS and the criteria for triggering the callout. In my example the trigger is empty, indicating all items going through CEWS:
PowerShell to Register CEWS
$ssa = Get-SPEnterpriseSearchServiceApplicationRemove-SPEnterpriseSearchContentEnrichmentConfiguration –SearchApplication $ssa$config = New-SPEnterpriseSearchContentEnrichmentConfiguration$config.Endpoint = "https://localhost:8888/Service1.svc"$config.DebugMode = $false$config.SendRawData = $false$config.InputProperties = "Path", "ContentType", "Title", "Sentiment"$config.OutputProperties = "Sentiment"Set-SPEnterpriseSearchContentEnrichmentConfiguration –SearchApplication $ssa –ContentEnrichmentConfiguration $config |
Timer Job (Force Re-Crawl)
The biggest challenge with an asynchronous enrichment approach is updating the index after the CEWS thread is released. No API exists to directly update items in the search index, so CEWS is the last opportunity to augment an item before it becomes available to users executing queries. The best we can do is kick-off an asynchronous thread that can queue enrichment data for the next crawl. Marking individual items for re-crawl is a critical component to the solution, because “the next crawl” will only crawl items if a full crawl occurs or if the search connector believes the source items have updated (which could be never). The crawl log in Central Administration provides a mechanism to mark individual indexed items for re-crawl
| CrawlLogURLExplorer.aspx option to recrawl |
|---|
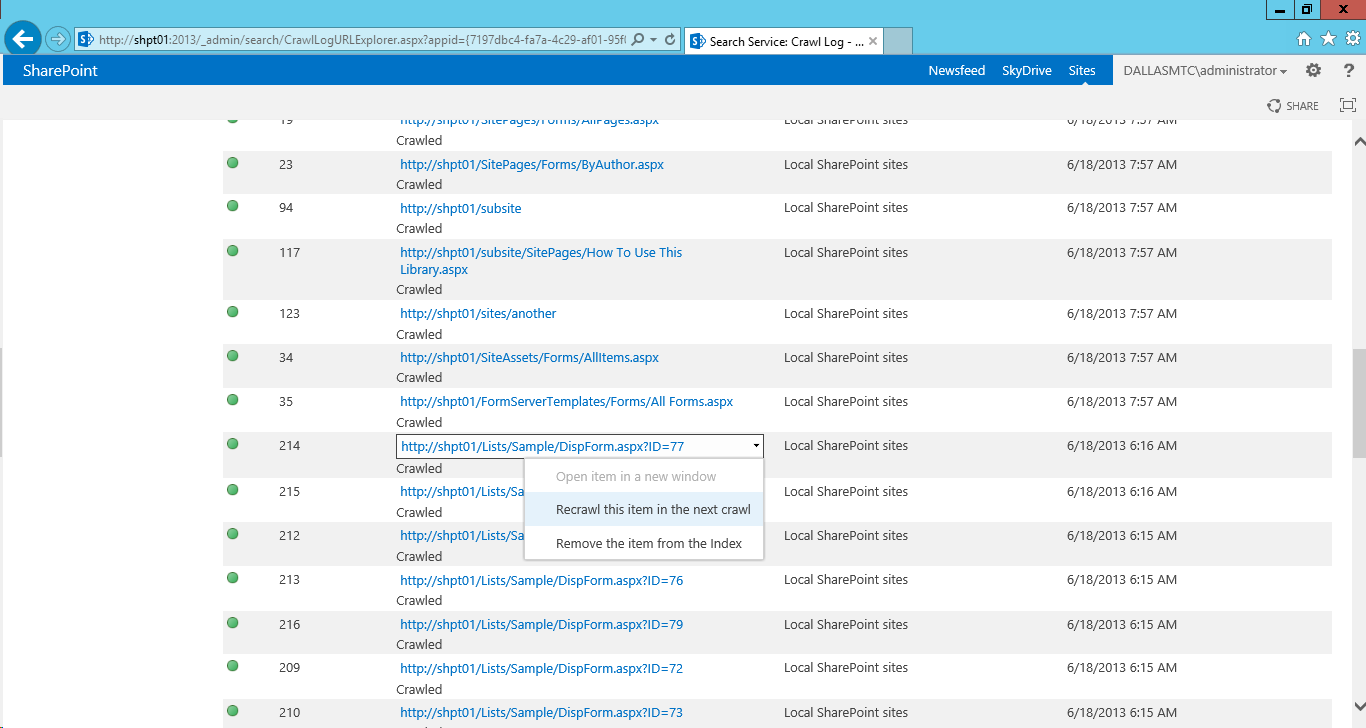 |
I decompiled the CrawlLogURLExplorer.aspx page and was pleased to find it leveraged a Microsoft.Office.Server.Search.Administration.CrawlLog class with a public RecrawlDocument method to re-crawl items by path. This API will basically update an item in the crawl log so it looks like an error to the crawler, and thus picked up in the next incremental/continuous crawl.
So why a custom SharePoint timer job? An item may not yet be represented in the crawl log when it completes our asynchronous thread (especially for new items). Calling RecrawlDocument on a path that does not exist in the crawl log would do nothing. The timer job allows us to mark items for re-crawl only if the most recent crawl is complete or has a start date after the crawl timestamp of the item. In short, it will take a minimum of two incremental crawls for a new item to get enrichment data with this asynchronous approach.
Custom Timer Job
using Microsoft.Office.Server.Search.Administration;using Microsoft.SharePoint;using Microsoft.SharePoint.Administration;using System;using System.Collections.Generic;using System.Data.EntityClient;using System.Linq;using System.Text;using System.Threading.Tasks; namespace ContentEnrichmentTimerJob{ public class ContentEnrichmentJob : SPJobDefinition { public ContentEnrichmentJob() : base() { } public ContentEnrichmentJob(string jobName, SPService service, SPServer server, SPJobLockType targetType) : base(jobName, service, server, targetType) { } public ContentEnrichmentJob(string jobName, SPWebApplication webApplication) : base(jobName, webApplication, null, SPJobLockType.ContentDatabase) { this.Title = "Content Enrichment Timer Job"; } public override void Execute(Guid targetInstanceId) { try { SearchServiceApplication application = SearchService.Service.SearchServiceApplications.FirstOrDefault(); CrawlLog crawlLog = new CrawlLog(application); using (ContentEnrichmentEntities entities = new ContentEnrichmentEntities(GetEntityConnection())) { //process all items in the database that where added before the current crawl DateTime start, stop; GetLatestCrawlTimes(WebApplication.Sites[0], out start, out stop); //use the first site collection for context foreach (var item in entities.EnrichmentAsyncData.Where(i => i.CrawlDate < start || stop != DateTime.MaxValue)) { crawlLog.RecrawlDocument(item.ItemPath.TrimEnd('/')); } } } catch (Exception) { //TODO: log error } } private EntityConnection GetEntityConnection() { //build an Entity Framework connection string in code...to lazy to update OWSTIMER config EntityConnectionStringBuilder connBuilder = new EntityConnectionStringBuilder(); connBuilder.Provider = "System.Data.SqlClient"; connBuilder.ProviderConnectionString = "data source=SHPT01;initial catalog=ContentEnrichment;integrated security=True;MultipleActiveResultSets=True;App=EntityFramework"; connBuilder.Metadata = "res://*/ContentEnrichmentModel.csdl|res://*/ContentEnrichmentModel.ssdl|res://*/ContentEnrichmentModel.msl"; //return the formatted connection string return new EntityConnection(connBuilder.ToString()); } private void GetLatestCrawlTimes(SPSite site, out DateTime start, out DateTime stop) { //mark item for recrawl SPServiceContext context = SPServiceContext.GetContext(site); SearchServiceApplication application = SearchService.Service.SearchServiceApplications.FirstOrDefault(); Content content = new Content(application); ContentSource cs = content.ContentSources["Local SharePoint sites"]; CrawlLog crawlLog = new CrawlLog(application); var history = crawlLog.GetCrawlHistory(1, cs.Id); start = Convert.ToDateTime(history.Rows[0]["CrawlStartTime"]); stop = Convert.ToDateTime(history.Rows[0]["CrawlEndTime"]); } }} |
With these three solution components in place, we get the following before/after experience in search
| Before | After |
|---|---|
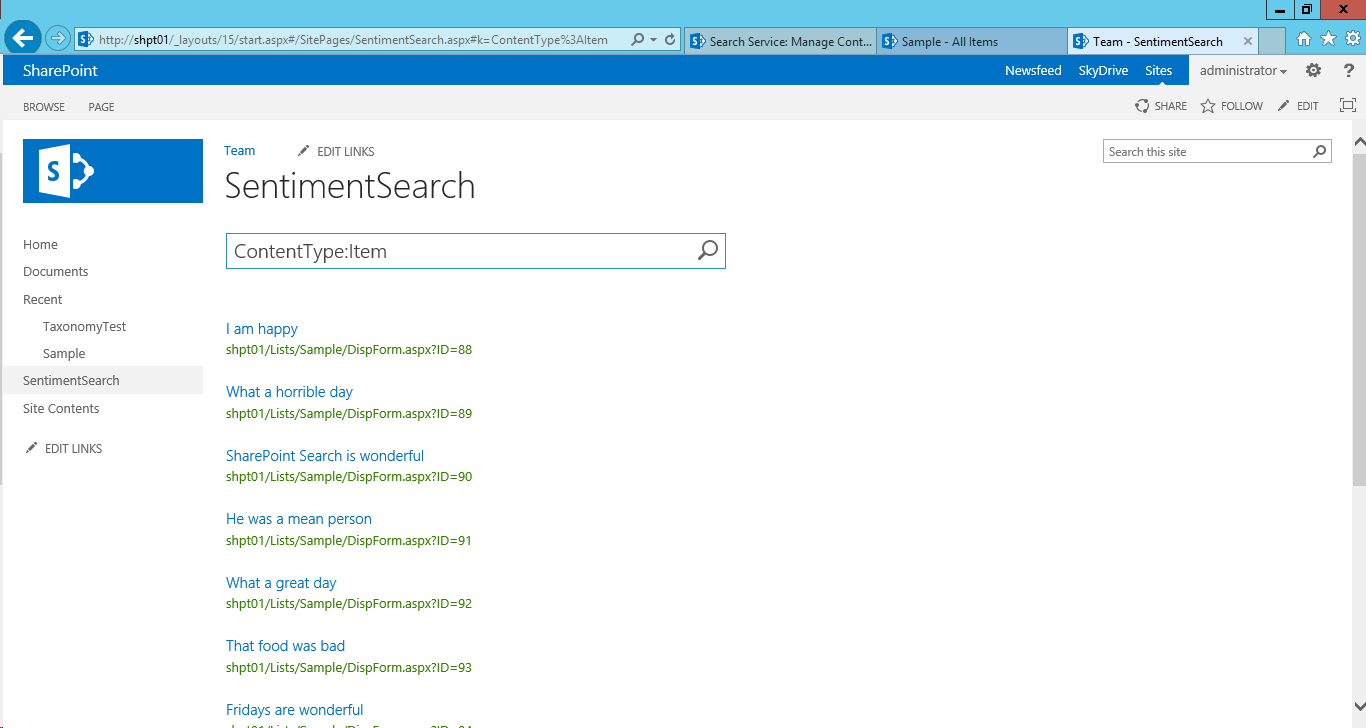 |
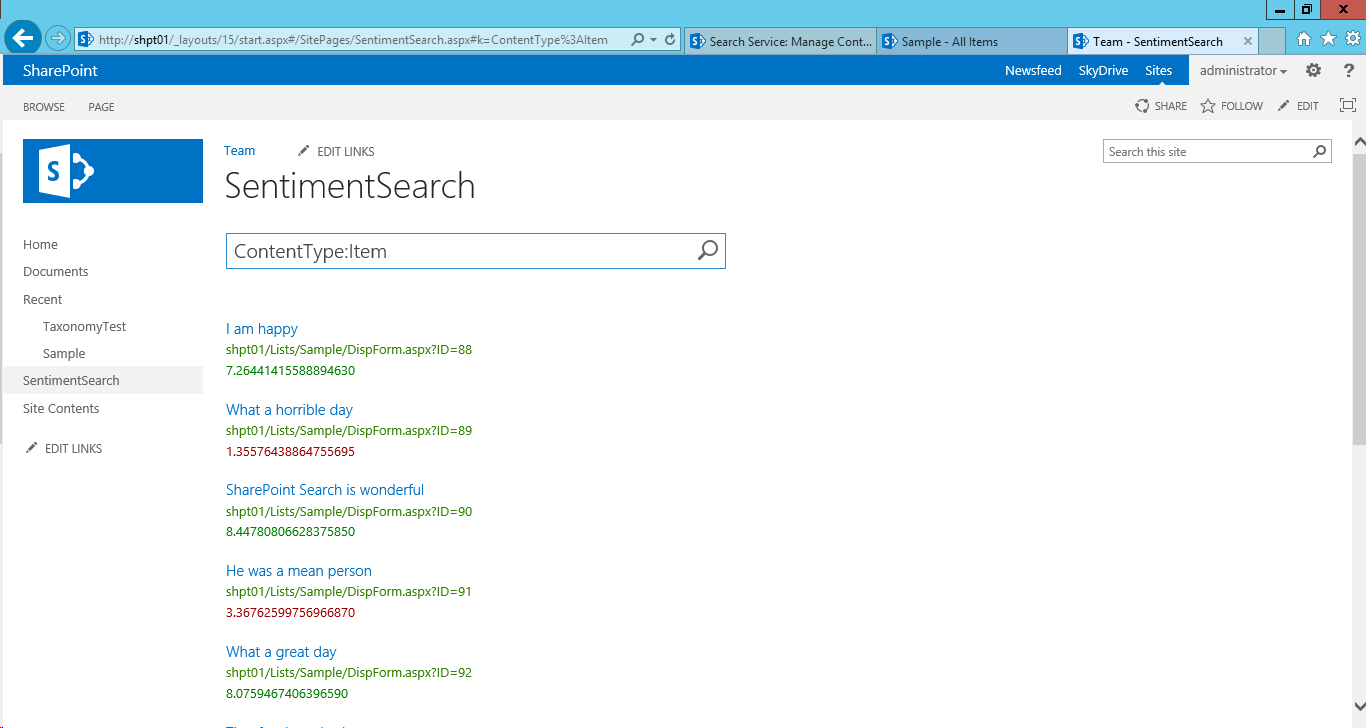 |
Final Thoughts
Content enrichment is a very mature but powerful search customization. I hope this post helped illustrate a creative use of content enrichment that can take your search experience to the next level.
Code for solution: ContentEnrichmentServices.zip