Handling High volume events with Azure Event hub
When we need to handle high volume events and telemetry per second, Azure Event hub service is an ideal candidate for this kind of workload. Azure Event Hub is a highly scalable data streaming platform and event ingestion service, capable of receiving and processing millions of events per second.
It is our first step for event pipeline, which we called event ingestor. It is a component between your event producer and event consumer. To handle millions of events per second, you can use multiple event hubs under a event hub namespace Also, in each event hub, we can have multiple partitions. At very high level, it will look as shown below
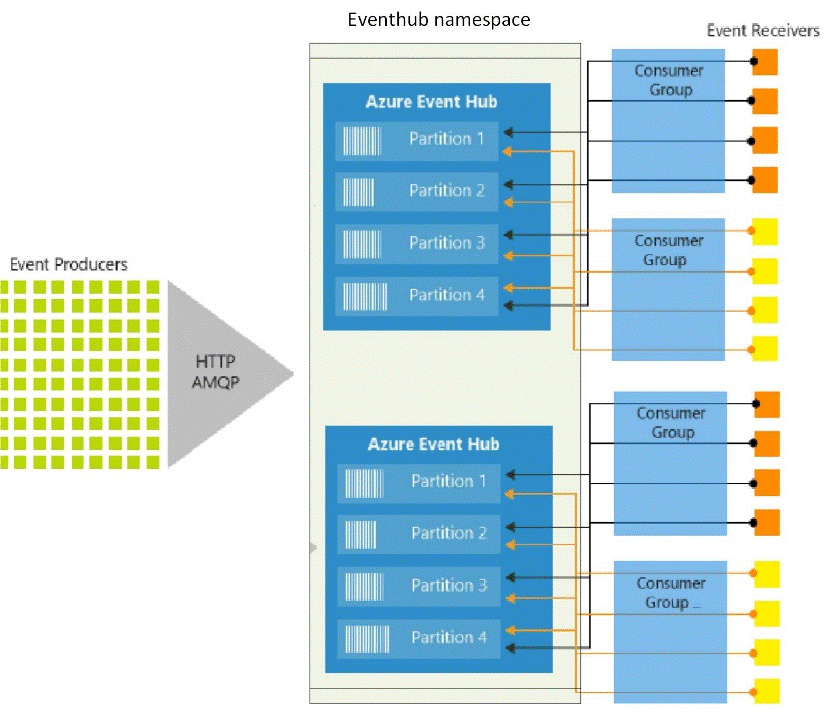
Let’s next explore how we can use Azure event hub to handle high volume. At high level, we have 3 steps:
- Configure Azure Event Hub service
- Write service to push data into different partitions of Azure event hubs
- Write service to Read data concurrently from different partitions of event hubs
Step 1 : Configure Azure Event Hub
To start with, we will create one event hub namespace with name “Eventhub-namespace-azure”. Create this name space with default throughput unit i.e. 2. Under this event hub name space create 2 event hubs with name “hub1” and “hub2”. By default, each event hub has 2 partitions. Change number of partitions to 4 in both event hubs i.e. “hub1” and “hub2”. This is feasible only while creating the event hub. In Azure portal, it will look as shown below
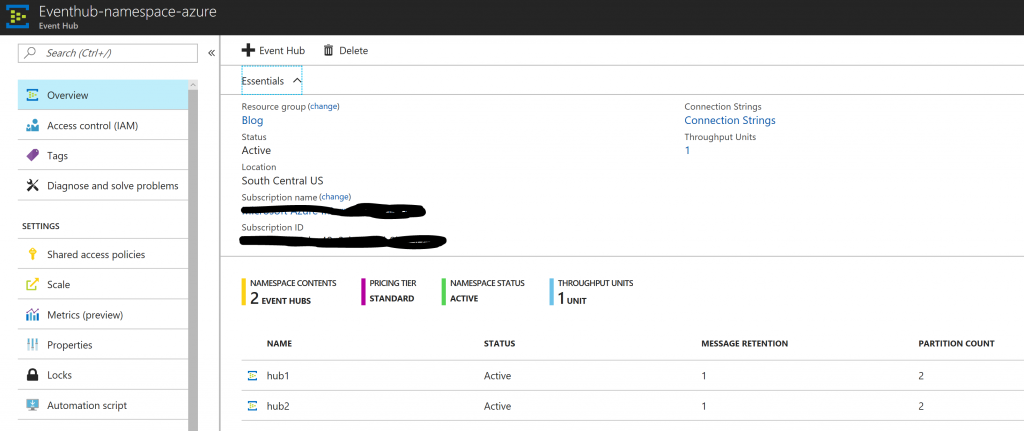
Once you have created event hub you can’t modify number of partitions. For how to create event hub, refer below link
/en-us/azure/event-hubs/event-hubs-create
Now we are ready to push data into event hub. Let’s move to step 2.
Step 2 : Write service to push data into different partitions of event hubs.
Java code for sending event into specific eventhub partition is in below git location
https://github.com/ReenuSaluja/Azure-eventhub-multi-partition-send
To clone the code on local run below command on command prompt
Git clone https://github.com/ReenuSaluja/Azure-eventhub-multi-partition-send
In code, go to client.java file which is located under com.ms.eventhub package. Replace values of ----ServiceBusNamespaceName----, ----EventHubName----, ----SharedAccessSignatureKeyName----, ----SharedAccessSignatureKey---- into below code s
namespaceName = "----ServiceBusNamespaceName-----";
eventHubName = "----EventHubName-----";
sasKeyName = "-----SharedAccessSignatureKeyName-----";
sasKey = "---SharedAccessSignatureKey----";
based on your eventhub configuration in azure. Based on step 1 configuration, value of namespaceName would be “Eventhub-namespace-azure”. If you want to send events into event hub “hub1” then value of eventHubName would be hub1 , otherwise hub2. To send event to eventhub sendSync function is called.
ehClient.sendSync(sendEvent,"partion1");
All Events with Same partitionKey will land on the Same Partition. So all the events with partition key “partion1” will be in same partition. In next line there is another statement ehClient.sendSync(sendEvent,"partion2");
Here the partition key is specified as "partion2". So this event will land into second partition. Point to be noted here is, although both events will be going into different partitions, but part of same event hub.
After running the sample code, goto Azure portal. Select your eventhub namespace->hub1 and click on Metrics.
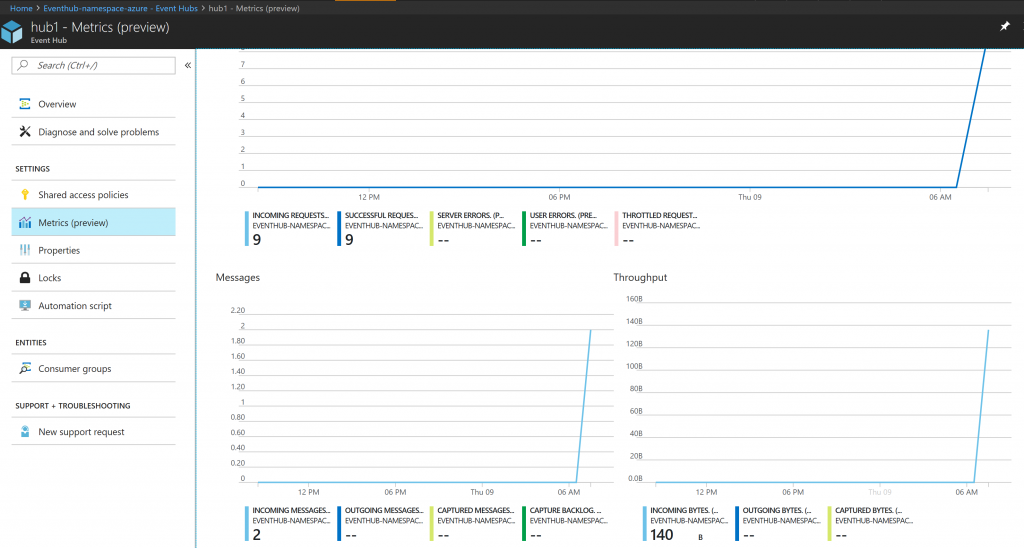
Based on sample code 2 messages were sent one in each partition.
Step 3 : Write service to Read data concurrently from different partitions of event hubs.
To get sample code to read data from event hub, either you can git clone it from below location
https://github.com/ReenuSaluja/Azure-event-hub-reader-multithreading
or you can git clone from
https://github.com/Azure/azure-event-hubs/tree/master/samples/Java/src/main/java/com/microsoft/azure/eventhubs/samples/Basic and customize it for multithreading. For both ways you need to follow steps to create storage account for event hub as given in
If you open EventProcessorSample from https://github.com/ReenuSaluja/Azure-event-hub-reader-multithreading , you will find a variable with name ExecutorService. This variable is initlize with a constructor Executors.newWorkStealingPool(2). Number 2 is there number of concurrent thread. You can increase it as per your requirement. newWorkStealingPool is part of java 1.8. if you are using older version, you can simply use newFixedThreadPool constructor for multithreading. Now there will be 2 concurrent threads running on same eventhub.
Few points to be noted.
- In this code we are using default consumer group. You can enable multiple consuming applications to each have a separate view of the event stream, and to read the stream independently at their own pace and with their own offsets. In your code you just need to replace "$Default" value of consumerGroupName with your consumer group name.
- You can have upto 5 concurrent readers on a partition per consumer group
- In EventProcessor.java file
context.checkpoint(data);
statement keeps track of reader current position in the event stream. This saves current checkpoint into storage account with details of consumer group, event hub.
You can get more details on this from /en-us/azure/event-hubs/event-hubs-features.
- For batch processing of event, you can use LinkedList of EventData. That will be pass as parameter in sender.sendSync.
- If you want to have multiple instance of reader application,
o Configure multiple partitions in event hub.
o In Step 3, in reader code, change value of “Host1” as unique for each instance of the reader, which is a parameter in EventProcessorHost constructor.
Recap
To handle high volume events in Azure event hub, first we had configured eventhubs. Then we used java api to insert data into different partitions of eventhub. We then created multithreaded Java application to read data from eventhub partitions.