Sorted Seeks
The Optimizer model makes several assumptions when making plan choice decisions. These decisions can be false for particular queries and data sets, and sometimes this can cause plan issues. One such problem is called “The Sorted Seek Problem” by the Optimizer Team, and it affects plan selection, usually between clustered index or heap scan plans and bookmark lookup plans.
When costing a series of bookmark lookup operations (for a heap) or index seek operations (for an index), the costing code will effectively treat these as a series of random I/Os. These are much more expensive than sequential I/Os because the disk arm needs to be moved and the disk needs to spin around to find the right sector(s). When the correct page is found, it is loaded into the buffer pool and the engine will cache it for future references. The costing code also understands, on average, how often a page is likely to be found on subsequent operations in the cache, and it costs these accesses much more cheaply than the original access.
When a query needs to perform lookups into an access method, the costing code makes the assumption that rows are uniformly distributed over the pages in the table/index. Under this assumption, effectively each row that is accessed is expensive because we assume that it needs to be loaded from disk. (At some point, all pages may be in the buffer pool and no longer require the expensive random I/O operation to load a different record from a previously accessed page).
In practice, rows are usually not randomly distributed. In fact, many common user patterns will insert rows in physically clustered order. For example, you likely would insert all of the order details for an order at the time that the order was created. These could end up clustered on a very few data pages. As such, a plan that does a bookmark or index lookup into this structure may complete more quickly than the costing model has forecast. As a result, the Query Optimizer may pick a different plan that runs more slowly for the customer’s installation.
To be fair, there are a number of scenarios where the rows are uniformly distributed, so they would be broken under a different assumption. In the future, we may be able to provide additional features to find and fix such problems for customers. Today, your best option in such situations is to use query hints to force the index plan if you know that you have data that is physically clustered.
The following sanitized customer example demonstrates this scenario in more detail. The table is contains about 80 columns and 5.5 million rows. In the query, the filter qualifies just over 21,000 rows.
SELECT * FROM CustTable WHERE col='someconstvalue'
|--Parallelism(Gather Streams)
|--Table Scan(OBJECT:(CustTable), WHERE:(col=’someconstvalue’))
Table ‘CustTable’. Scan count 3, logical reads 416967, physical reads 22, read-ahead reads 413582, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Completed in 3 minutes 9 seconds
SELECT * FROM CustTable with (index=idxoncol) WHERE col='someconstvalue'
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000], [Expr1005]) WITH UNORDERED PREFETCH)
|--Index Seek(OBJECT:(idxoncol), SEEK:(col=’someconstvalue’) ORDERED FORWARD)
|--RID Lookup(OBJECT:(CustTable), SEEK:([Bmk1000]=[Bmk1000]) LOOKUP ORDERED FORWARD)
Table 'CustTable'. Scan count 1, logical reads 21167, physical reads 387, read-ahead reads 1354, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Completed in 11 seconds
The first query is the original user query, and the default plan picked is a parallel scan of the base table, applying the filter as a pushed non-SARGable predicate into the scan. It takes over 3 minutes to complete. The second plan uses an index hint to force a bookmark lookup plan. It completes in 11 seconds. If you assume that a random disk seek takes approximately 10 ms, you can’t do more than 100 in a second. For this query, 21,000 seeks would probably take over 3 minutes to do if each was a random I/O against a single disk. Therefore, there are likely fewer than 21,000 random I/Os happening. We can see this from the statistics I/O output – there are only 387 + 1354 actual page reads in the query.
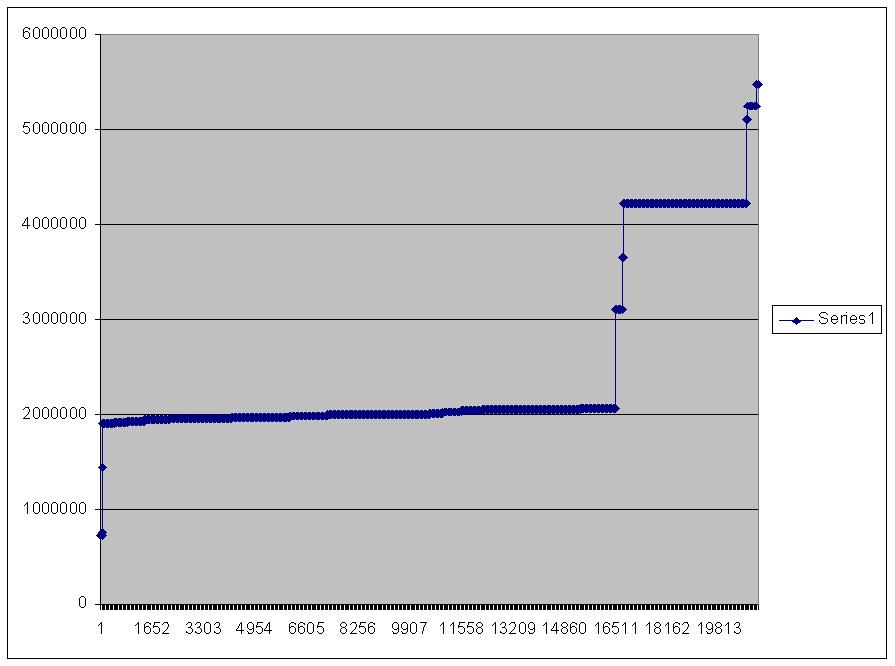
The actual data distribution is not uniform. In fact, it is heavily physically grouped. I ran a query that counted the physical row position in the heap and then filtered out the rows that qualified in this query. The rows should be somewhat randomly distributed through the set of rows to match the uniformity assumption. I copied this output into Excel and charted it:
[see attachment]
(The pre-filter row number is the y-axis, and the post-filter row number is the x-axis).
As you can see, the rows are very clustered on the disk. As such, many of the rows used in the bookmark lookups are found on pages that are already loaded into the buffer pool from previous I/Os. This significantly speeds up the query.
The recomendation for these cases is to use query hints if this is a significant issue for your query.
Enjoy,
Conor
{kind=link}