How It Works: SQL Server Sparse Files (DBCC and Snapshot Databases) Revisited
Sarah and I have been approached by several customers wanting to know more about sparse file allocation behaviors. This post attempts to answer those questions.
Previous Posts
Spare File Allocations
The diagram shows page 80 on extent 10 and page 800 on extent 100. The top portion illustrates the actual storage movement during SQL Server copy on write (COW) activity. Some have the impression that the dirty pages are packed together in the spare file which is not the case.
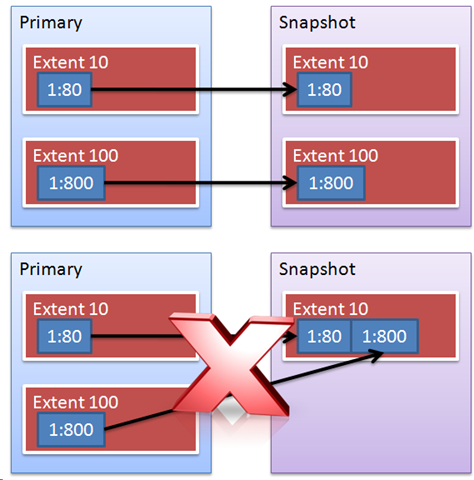
Page numbers are always used as the storage offset. (Formula: Page Number * 8192 = Storage Offset). When page 80 is dirtied it is first, copied to the offset (80 * 8192) in the spare file. When page 800 is dirtied it is copied to the offset (800 * 8192).
The first time any page is written to the sparse file the entire 64K extent is allocated. All other pages in the extent are written as zero's. So if you dirty page 80 a 64K allocation occurs in the sparse file at the 10th extent location. If you then dirty page 800 another 64K allocation takes place at the 100th extent offset. If you then dirty page 81 the data is written to the offset (81 * 8192) but additional space allocation is not needed because the original 64K allocation for the extent took place when page 80 was written to the sparse file.
Copy On Write In Action
The illustration below shows a very simplified table with a clustered and non-clustered index. The inserted rows are in sorted order with the clustered index and will be inserted in page 1:84.
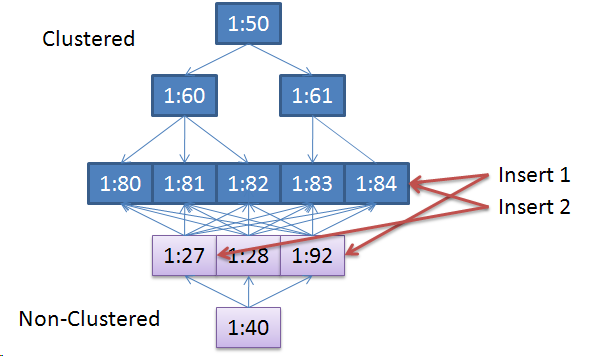
Insert 1: Identifies that 1:84 is the location for the data. Page 1:84 is copied to the sparse file and 64K is allocated (pages 80 to 88). The non-clustered index update occurs on page 1:92. This is a new extent so 64K is allocated and page 1:92 is copied to the sparse file.
Insert 2: Identifies that 1:84 is the location for the data. Page 1:84 has already been copied to the sparse file so on copy is needed. The non-clustered index update occurs on page 1:27. This is a new extent so 64K is allocated and page 1:27 is copied to the sparse file.
After the 2 inserts SQL Server has allocated 3 extents (64K * 3 = 192K) in the sparse file and only 3 pages (8 * 8192 = 24K) have been updated in the primary database requiring no new allocations.
- Continued inserts will allocate new pages for the clustered and non-clustered index.
- Page splits require 2 pages instead of one to be copied.
- New allocations in the primary are first copied to the snapshot.
Tracking The Affects From Primary to Sparse File
The EXAMPLE section contains a sample script that shows you how to see the affects of the copy-on-write behavior. You can use the same technique to visualize the copy-on-write behavior for your scenario.
WARNING: sys.dm_os_buffer_descriptors iterates all BUF structures in memory and should be used with caution. Do this testing on a TEST system and not production.
Extent database_id file_id page_id page_level allocation_unit_id page_type row_count free_space_in_bytes is_modified
----------- ----------- ----------- ----------- ----------- -------------------- -------------- ----------- ------------------- -----------
40 7 1 47 0 72057594043367424 DATA_PAGE 44 1892 1
88 7 1 93 0 72057594043432960 INDEX_PAGE 46 1748 1
120 7 1 126 0 72057594043498496 INDEX_PAGE 46 1748 1
The extent column is a good focal point. Because the table contains a clustered, and two non-clustered indexes 3 pages are modified to insert the 'Last' row. Each of these are on separate extents resulting in 3 copy-on-write operations.
As explained previously this results in 3 extent allocations (40, 88 and 120) of 64K in the sparse file. If another modification occurs on page 46, extent 40 in the snapshot is already allocated and a new allocation is not needed. However, if page 50 is modified then extent 48 will be allocated.
Mitigation's
At first I thought that studying the affects on the spare file at this level of granularity was more of an academic exercise. After I thought about this it became much more. Using the technique to determine the type of modification patterns no only helps with sparse files but the primary database file I/O patterns as well.
Looking over your index design and fill factors can make a big difference. For example, the customer that spurred this blog post was rebuilding indexes with 95% fill factor then doing data loads on a table with 6 indexes. This resulted in immediate page splits of the non-clustered indexes. Not only do the splits quickly populate the snapshot but elongate the insert operation. Their load is likely faster with a smaller fill factor to avoid splits in the primary and reduce the copy-on-write activities.
You can query sys.dm_db_index_usage_stats and do some deltas with the user_updates counter to get an idea of which indexes are being modified the most and therefore the most likely candidates to be driving the snapshot file growth.
Next you can query sys.dm_db_index_operational_stats to drill down further and look at the leaf_allocation_count and nonleaf_allocation_count to gauge if page splits are also occurring at the leaf or non-leaf layer for the index and the rate.
Keep in mind that the counters in sys.dm_db_index_usage_stats and sys.dm_db_index_operational_stats do not have any direct mapping to the number of pages copied to the replica.
If you have been having issues running in to the sparse file limit with 1450/665 errors, a mitigation strategy is to split off the indexes modified the most to a separate filegroup that consists of multiple files. The number of files required will vary. If you look at the growth rate of your sparse file and how quickly it has been reaching the limit, this can help you gauge the number of files you will likely need. Add more files as needed until you reach a balance where you can avoid hitting the limit until when you can drop the snapshot. You will want to rebuild the indexes after you add files so that you get the most even distribution of pages across the files.
If page splits are also causing extra snapshot file growth, you can mitigate with FILLFACTOR and PAD_INDEX. Page splits at the leaf level you can address with FILLFACTOR. Splits at non-leaf level you address by using PAD_INDEX along with FILLFACTOR.
Testing is the only way to determine what is the appropriate combination of FILLFACTOR and PAD_INDEX for your index. The level of mitigation on the snapshot file growth through FILLFACTOR and PAD_INDEX will vary based on the degree that page splits were contributing to the extra allocations.
EXAMPLE T-SQL SCRIPT
set nocount on
go
use master
go
drop database dbTestSnapshot
go
drop database dbTest
go
create database dbTest
go
use dbTest
go
create table tblTest
(
iID int PRIMARY KEY IDENTITY(1,1),
strData nchar(64)
)
go
create nonclustered index idxTest on tblTest(strData)
go
create nonclustered index idxTest2 on tblTest(strData, iID)
go
insert into tblTest (strData) values (N'First')
while(scope_identity() < 100)
begin
insert into tblTest (strData) values ( cast(scope_identity() as nvarchar(20)) + N' this adds some length to the column')
end
go
CREATE DATABASE dbTestSnapshot ON
( NAME = dbTest, FILENAME = 'C:\temp\dbTestSnapshot.mdf' )
AS SNAPSHOT OF dbTest;
GO
use dbTestSnapshot
checkpoint
go
use dbTest
checkpoint
go
dbcc dropcleanbuffers
go
insert into tblTest (strData) values (N'Last')
go
select (page_id / 8) * 8, allocation_unit_id as 'AllocUnit', *
from sys.dm_os_buffer_descriptors
where database_id in (db_id('dbTest'))
and allocation_unit_id in (select allocation_unit_id from sys.allocation_units where container_id
in (select hobt_id from sys.partitions where object_id = object_id('tblTest'))
and type = 1)
and is_modified = 1
order by page_id, page_level
go
Authors: Sarah Henwood - SQL Server Senior Support Escalation Engineer and Bob Dorr - SQL Server Principal Escalation Engineer