SQL Server 2008 - Resource Governor Questions
A couple of common questions have surfaced related to the SQL Server 2008 Resource Governor feature. The SQL Server 2008 BOL has a lot of good information so start don't forget to review that as well.
Metadata and Runtime Data
A set of DMVs exist for resource governor. The 'dm_ ' indicates the current 'in-use' (running values and statistics). These DMVs are helpful to view the various pool and group activities and supplement the performance counters well.
sys.dm_ resource* Running values and statistics sys.resource* Metadata values
Classification
Classification takes place during login the sessions maintains the classification for its lifetime. The classifier is a UDF similar to a login trigger returns a group name.
ALTER RESOURCE GOVERNOR DISABLE
Resource governor is dynamic and as such a disable is not absolute. Assume you have GroupA and sessions are assigned to GroupA (see sys.dm_exec_sessions group_id column). You then issue the disable command.
SQL Server will:
- Return the "default" group and pool to default values. For example the memory and cpu values will return to 0:100 and the query memory grant percentage to 25%.
- The classifier is ignored and all new sessions are assigned to the "default" group
- Existing sessions will remain assigned to GroupA until disconnected.
Internal Group
Activities such as the lazy writer, ghost record cleanup and others are assigned to the internal group. This is not a group that can be used by classifier. If "internal" or an invalid group is returned from the classifier the "default" group is used instead.
There are limited locations where the session is temporarily permitted to the internal group. One area is when producing a trace event. As an administrator you do not want to enable tracing on the server and commands to start failing memory allocation. If you had a pool set to 0:10 for memory and the production of the trace event exceeded the 10% max goal you don't want it to fail. It makes it really hard to support a server when support functions are limited. Instead SQL Server temporarily promotes the session to the "internal" group to produce the event and then returns the session to the assigned group.
Importance is not priority
The importance setting should not be looked at as a thread or process priority setting. For example a pool using 0:10 CPU with a group of high importance may not get resources ahead of a pool using 0:100 CPU and a normal importance. The resource governor is designed to avoid live and deadlock scenarios while attempting to maintain a high level of concurrency. There are times when other decisions will outweigh the importance decision.
Why when I disable resource governor does dm_exec_sessions and error messages indicate the "default" group assignment?
Disabling resource governor resets the "default" group and pool values to the defaults 0:100, 25% memory grant limit and such. All new sessions are assigned to the default pool as the classifier is disabled.
This behavior makes the SQL Server 2008 work similar to SQL Server 2005 but there are some subtle differences. You are really running with the "internal" and "default" pools and groups. Aspects of memory and scheduling can be applied to these groups. For example the default memory grant percent in SQL Server 2005 was 20. When resource governor is disabled the "default" group setting is "25%"
Active query is taking too much CPU how can I throttle it?
Individual queries can't be throttled but the groups and pools can be altered dynamically. It is important to remember that once a session is established it is bound to the group until disconnected.
Assume you have PoolA with a 50:100 min:max CPU configuration. You can alter the pool to 25:50 and issue a reconfigure. This is a change that can be dynamically applied so all groups associated with pool take on the 25:50 CPU behavior.
There are several configuration options that can be dynamically applied. Others are applied but may not take effect until the next batch due to the nature of the setting. An example of this would be group max requests. This is applied when the request is started.
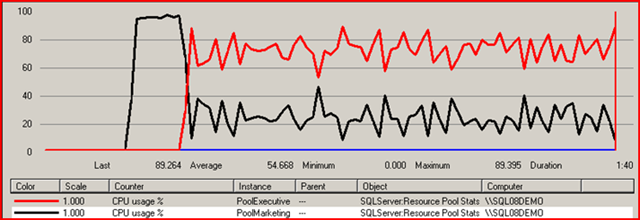
If PoolMarketing is max CPU percent is set to 10% and PoolExecutive to 100% why does marketing exceed 10%?
This example assumes a single query executing from each pool.
CPU percentage is determined at a per scheduler level. The max CPU percent is only a guideline to use when scheduler resources are under contention. So there are several possibilities here.
- This a a multiple processor computer and each session is using a separate CPU. Since there is no contention the CPU usage would not be limited for either query.
- I will tell you that this was a single CPU computer. Notice that the Marketing pool query start and used almost 100% CPU until the Executive query starts. This is where the SQL Server scheduler encounters contention and the balancing begins. It still exceeds 10% and this can be expected. Because Executive is not requiring 90% CPU Marketing is allowed to use the extra bandwidth. Perhaps Executive is waiting on I/O or other resource and does not need the CPU resource at a 90% level.
My classifier has a bug and is leading to connection timeouts. How can I correct it?
The classifier should run quickly. However, we have all made coding mistakes that cause infinite loops or other bad behavior. This will cause all new login attempts to timeout. So I would you login to disable the classifier and correct it?
- DAC logins do not execute the classifier.
- Starting SQL Server in single user move (-m command line parameter) does not execute the classifier.
------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------
CUSTOMER SUPPORT QUICK START (spring 2007 as is) ------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------
Here is an overview I provided to the support team in the spring of 2007.
The resource governor is designed to provide a fair level of scheduling, apply memory, concurrency and wait constraints. The design involves pools, groups and session classification assignments. The pool and group have separate controls that are combined to provide the governance activities. Pools can have more than one group assignment but a group can only be assigned to one pool.
Pools, Groups
Pool
Limited to 20 (18 user defined and 2 built-in [internal and default]) - pool and group names are case sensitive
The variance goal of RG is 5%. 100% / 5% is 20 or the logical max break down based on granularity of the feature
Pool Controls
Pool controls provide the key min and max limits for CPU and Memory.
Min/Max CPU% (Note: Applied per scheduler not as percent of all schedulers)
Min/Max Memory%
Warning: Pools that establish min and max memory values should be done with caution. As soon as the pool is available at runtime the memory boundaries are applied. This occurs even if a group is not yet bound to the pool. It is a bad practice to create pools with memory limitation that are seldom used as the SQL Server memory manager has to account for the pool and use the limits even when sessions are not active.
Group
A group can be associated with a single Pool but a Pool can have many group associations.
The code does not limit the groups but we should recommend to customers they keep a reasonable set of groups or maintenance and troubleshooting could become complex.
Group Controls
Group controls allow limitations that are generally applied to an individual worker request.
Importance (Low, Normal, High 1:3:9)
Max Concurrent Requests (Note: If transaction active request won’t honor this limit to avoid deadlocking.)
Request Max CPU Time Seconds
Request Max Memory Grant Percent
Request Max Memory Grant Timeout Seconds
Request MAX DOP
Special Pools and Groups: internal and default
The internal and default pools and groups are created during installation of the master database and are special, system groups. The internal pool and group is assigned to system tasks such as checkpoint, lazy writer and others. The default group is used whenever the classification is disabled (UDF not installed), invalid group name returned or any error in the classifier UDF is encountered.
The default pool and group can be ALTERED but the internal group parameters are fixed values.
Classification UDF
Classification is controlled by a server wide UDF, stored in master) that is run just like a login trigger. Once the authentication portion of the login has completed the ‘PreConnect’ activity takes place. This PreConnect state can be traced with the new PreConnect trace events as well and the ‘PreConnect’ state shown in sys.dm_exec_sessions and sys.dm_exec_requests. The classifier is not added to sys.dm_exec_query_stats but the individual statements are. Using the sql_handle in sys.dm_exec_requests the classifier can be identified.
The rules for the classifier are not limited to but include the following:
· UDF must return a group name of type NVARCHAR(128) == sysname
· Group names returned are case sensitive comparisons (this may use server setting in the future)
· Returning an invalid group results in assignment to the ‘default’ group
· UDF can’t assign to the ‘internal’ group. Returning internal results in assignment to ‘default’ group
· UDF can’t call XPROCs, Linked Server or other such T-SQL such as waitfor delay.
· UDF is part of the login process so it should execute quickly or logins can timeout
· Session is bound to the group for the life of the session
· If UDF fails (ex_raise) or returns invalid group name the session is assigned the default group.
· If no classification UDF is active/present the session is assigned the default group.
· System tasks (checkpoint, lazy writer, …) are assigned to internal and don’t execute the classifier
· DAC does not execute the classification UDF allowing the DBA to access the server if the UDF is misbehaving
· Starting SQL Server with –m –f avoids execution of the classifier UDF allowing resource governor meta data changes
· Classifier allows access to common tables, DMVs and intrinsic to obtain information such as application name for group assignment decisions
Classifier Invocation
The classifier is a UDF that is fired right after the login triggers and before the T-SQL debugger is enabled during login. The classifier runs under the ‘interal’ group as classification can’t take place until after the classifier returns the proper group.
Importance (HIGH, MEDIUM (normal - default), LOW)
A group property that should be clearly understood is the importance. Importance does not imply a priority scheme such as one might be used to with thread and process priorities in the Windows schedulers.
Importance is just used as a simple weighting among active workers for the pool. When a worker is added to the runnable list (Resume) the importance is use as a factor for position in the list against other workers in the same pool on the same scheduler. The importance does not carry across multiple schedulers nor does it carry across multiple pools on the same scheduler. It only applies to active workers of groups assigned to the same pool.
Session Boundary
The classification only takes place during the initial creation of the session. Version 1 is not shipping with a SET statement allowing a session to change their group explicitly. This means that we don’t have to conver all the possible scenarios about behavior when a SET is used in a proc versus a batch or transaction scope activities. It also means that sp_resetconnection does not re-execute the classifier. The classification is done in the login function only (same place as login triggers) and the classification is bound to the session for life of the session.
There are limited internal locations that the group may be altered. An example of this is producing a trace event. The production of the trace event is wrapped with an auto scoped class that binds the working to the internal group until the event is produced. This prevents unwanted conditions such as out of memory when a memory limited pool is producing an event. When running in C2 audit mode is an event can’t be produced the SQL Server is shutdown. The SQL Server will prevent such issues by establishing a temporary assignment to the internal pool when required.
Metadata – Master.mdf
The metadata is stored in the master database. When I first read about the feature I was thinking about a hosting scenario and that the hosted databases could have different groups and pools and that put me in the mindset that the database had the metadata. This is not the case. Master holds the metadata for resource governor, including the classification UDF. They don’t have to be but the pools, groups and classifier would need be scripted and established on alternate servers you want to restore or attach databases on and maintain the resource governor settings. If the database is restored or attached on a server without the classifier, pools or groups the default behavior applies.
This is critical to CSS for attempting reproductions. It will be important that when cloning a database you also get the pools, groups and classifier. For example, the pool may have a memory limit the changes the plan selection. If the memory limitation is not applied a different plan could be selected. Outside of the clone a DTA tuning exercise may need the proper settings to perform the what-if analysis.
This is also important to customers because they will need to properly maintain the resource governor metadata on test servers to be able properly establish testing environments.
Alternate Workloads
The resource governor does not force the min and max setting for all pool or group properties. The scheduling decisions are only made when there are 2 or more active users on the same scheduler. If scheduler bandwidth is available the worker can exceed the max configured value because doing so does not violate the scheduling for another pool.
Memory limits are upheld because it would be extremely difficult to exceed the max value and be able to quickly return to the max limit when another pool needed to use it.
The group provided a max concurrent user limit. This can be exceeded by something like an open transaction. For example, if a worker is returning to run a batch and already has an open transaction the worker may be allowed to execute and exceed the concurrent user limit. If the server did not allow this we can create unwanted blocking and deadlock situations. Allowing the user to continue is the best solution.
With all this variations possible to properly test alternate pools, groups and workloads should be applied to testing environments. You can’t simply configure a pool to support 0:50 CPU and test for proper query duration. Without alternate load the pool will get 100% of the CPU. You would have to create an alternate pool set to 0:50 and have something like ‘while(1=1) declare @iID int’ running on each scheduler to make sure the 50% target is maintained and the testing can validate the true response parameters.
Variance
Variance among this is common. The CPU% values should never be set to anything less than a 5% boundary. Resource governor does not provide strict, percentage guarantees but instead we should use the terms like ‘in aggregate’ or ‘in average’ the values are upheld. The scheduling goes into the possible CPU variances and explains how over time, with the proper loads the designated values should average near the designated settings.
DMVs
There are several for resource governor. The following are the meta data DMVs showing the currently established meta data. These can be different from the running values until the proper reconfigure has taken place.
select * from sys.resource_governor_resource_pools
select * from sys.resource_governor_workload_groups
select * from sys.resource_governor_configuration
The following dm_* DMVs expose the running values
select * from sys.dm_resource_governor_resource_pools
select * from sys.dm_resource_governor_workload_groups
Examples
The following example creates a pool for 0:25 CPU, 0:100 Memory then creates and assigns a group with low importance to the pool. All of the create commands have matching alter commands.
Create a Pool
CREATE RESOURCE POOL Pool1
with
(
MAX_CPU_PERCENT = 25
)
Create A Group
CREATE WORKLOAD GROUP Group1
with
(
IMPORTANCE = Low
)
using Pool1
Create Classifier
create function RDORR_CLASSIFICATION ()
RETURNS sysname
with SCHEMABINDING -- Schema binding is required
as
begin
return N'Group1' -- All new sessions are assigned to Group1
end
Enable the Classifier
ALTER RESOURCE GOVERNOR WITH (CLASSIFIER_FUNCTION = dbo.RDORR_CLASSIFICATION)
ALTER RESOURCE GOVERNOR RECONFIGURE
Disable the Classifier
ALTER RESOURCE GOVERNOR WITH (CLASSIFIER_FUNCTION = NULL)
ALTER RESOURCE GOVERNOR RECONFIGURE
------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------
CPU Scheduling (Fair Scheduling) (spring 2007 as is)
------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------
Here is an overview I provided to the support team in the spring of 2007. Some of this has changed and is patented but the overall idea stands and is helpful.
The resource governor design includes scheduling. I want to make it very clear that the resource governor does NOT attempt to limit actual CPU. The design is based on balancing activity on a per scheduler bases based on the pool settings and active workers and when contention is not a factor all CPU resources are made available to the worker. This design makes it critical that customers test pool parameters using alternate workloads when in QA testing environments.
The scheduling portion of the RG improvement is SOS based and happens on a per scheduler basis. SOS does not look across schedulers when determining what the local runnable list should look like. The runnable list has changed from simple linked list like SQL Server 2005 were you add to tail or head to a percentile design.
Under limited explanation the percentile design is essentially an array of runnable list used like a time window. When a worker is ‘Resumed’ (added to the runnable list tail) the proper percentile bucket is selected.
Say the current runnable list dequeue position is at the percentile location of 2. The time window would move forward as 2, 3 … and 1 would be the end of the time window. Workers enqueued at location 2 (current time) would be processed. Once the workers at location 2 are processed the current dequeue location moves ahead to position 3 and so forth.
C
[0][1][2][3][4][5][6]
When a worker is resumed the pool information and importance is used to determine the location in the time window that is appropriate for the enqueue. Let’s take an example of 2 workers. Worker A is assigned to pool 1 which is configured for 0:25 and Worker B is assigned to pool 2 which is configured for 0:75. Both workers are active at the current (C) location =2. It helps to think of the activity in terms of quantums and not CPU usage. In this case we want Worker A to get 1 quantum and Worker B to get 3 quantums out of the next 4 quantums to uphold the pool goal targets.
In a simplified discussion what will happen is Worker B will get placed in the runnable queue in bucket 3 and Worker A will get placed in bucket 6. The dequeue will advance to bucket 3 and scheduler worker B. Worker B yields (quantum exceeded) and determines the next location to enqueue. It should enqueue in location 4, repeat this for 5 and then 6. When the dequeue activity reaches position 6 both worker A and worker B get scheduling quantums and the activity repeats.
Remember this is all per scheduler based using the current active tasks to determine the pools allotted scheduling resources. As active tasks come and go from the scheduler the percentile enqueue locations are adjusted, attempting to provide fair scheduling quantums to the active workers based on pool settings.
There are conditions that the worker is just added to the head of the current buckets runnable list. This has been the case since SQL Server 7.0 and the conditions remain similar. An example might be that a worker was waiting on a I/O request that just finished. Since it was not using any scheduling quantums it is added to the beginning of the current runnable list for the current quantum and the next yield will apply the RG activity.
NO SLEEP: The scheduler never adds logic to maintain the max CPU by adding sleeps.
CSS is likely to get inquiries that I set my CPU max to 50% and SQL Server is still using 100% CPU. This is by design. If the CPU has bandwidth the scheduler just works off the runnable queues and allows the workers to execute. As long as the quantum sharing takes place SQL Server still uses the available hardware. This is again why testing of the various settings is importing with alternate T-SQL workloads using CPU bandwidth. As long as there is nothing in the current dequeue location the runnable list will progress to the next slot and so forth until it finds a runnable user or the scheduler becomes idle. So a pool with a cap of 20% will queue at the proper percentile buckets but if no other activity is present the worker gets to use the scheduler quantums.
Preemptive Activities
The RG CPU implementation is only responsible for CPU time acquired from the SQL_OS schedulers. It does not attempt to control any preemptive (XPROC, Linked Server, sp_OA,…) CPU usage. The one exception to this statement is SQLCLR. The SQLCLR activities are supported by SOS_Tasks and as such some of the CLR activity can be controlled by the SQL_OS schedulers. As a reminder not all CLR activity maps to a SOS_Task so some aspects of SQLCLR may not be controlled by the RG.
Importance
Groups and thus SOS_Tasks can be assigned importance levels (Low, Normal or High.) This is distinctly different from thread priorities as changing thread priorities can cause unwanted side effects such as:
· Irresolvable spinlock and other synchronization object starvation
· Alteration of I/O priority
· Memory allocation operations
The importance indicates to a single scheduler the relative priority of the request.
· Importance does not span multiple schedulers and SOS_Tasks can’t be migrated to different SOS_Schedulers.
· The task remains bound to the scheduler.
· Tasks with internally boosted priority always go to the head of the runnable list. For example: An aborted task is placed at the head of the runnable list.
Ratio
The current importance ratio is LOW:NORMAL:HIGH - 1:3:9.
Current Tasks
The CPU activity for RG only applies to runnable tasks. Tasks that are in a wait state don’t affect current calculations.
The CPU ratios are recalculated as needed when a user is resumed on the scheduler.
Note: If no other tasks are present on the CPU the full bandwidth of the CPU can be used by the task.
Use Available
Whenever CPU is available it is assigned to one or more of the runnable tasks to use. The Max CPU limit only becomes a hard limit when exceeding it would cause another pool to drop below its Max setting. SQLOS will always attempt to maximize the CPU resource usage.
This is an important point because you won’t be able to develop a set of pools and groups in SQL Server as a way to manage CPU on the machine in a way to give CPU resources to other applications.
SQL 2005 Compatibility
The RG change slightly changes the scheduling from what SQL Server 2005 and previous SQL_OS or UMS schedulers provided. Even when all users are running under the DEFAULT POOL and DEFAULT GROUP the fairness is being applied. In previous versions of SQL Server you went to the end of the runnable list and it was more of a round-robin approach. The RG design places the worker in the proper percentile bucket so overall the fairness of schedule resources may slightly change the scheduling behavior.
Bob Dorr
SQL Server Senior Escalation Engineer