Code As Dependency Configuration
In his article on Inversion of Control and Dependency Injection, Martin Fowler has a quite interesting section towards the end where he talks about how to configure loosely coupled systems. One of his points is that in some cases, it makes more sense to tie it all together using code than by using a configuration system.
When I introduce the concept of Code As Configuration for most people, they seem to instantly stop listening to what I'm saying. Configuration (the ability to change the behavior of the application without changing its code base) is good, so why would you ever want not to enable configuration? In .NET, this notion is particularly strong because System.Configuration makes it so easy to create a rich configuration object model backed by XML configuration files.
With Dependency Injection, the configurable entities are types (defined in various assemblies). Because of Dependency Injection, each library in your application can be compiled in isolation, since its volatile dependencies are being injected at run-time. A design pattern such as Constructor Injection is fairly simple and intuitive to use as long as you use it in isolation during development (e.g. while unit testing), but when it comes to tying everything together in an executable application, all these dependencies must be loaded into an object hierarchy such as this one:
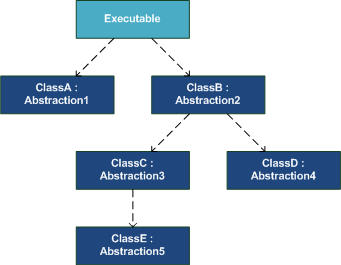
In this example, each class is defined in a separate assembly. Note that the arrows indicate usage, not dependencies. For the application to run in the desired configuration, ClassC must consume an instance of ClassE, and so forth. However, ClassC only knows about Abstraction5, which is being injected into it via its constructor:
public class ClassC : Abstraction3
{
private Abstraction5 a5_;
public ClassC(Abstraction5 a5)
: base()
{
this.a5_ = a5;
}
protected override string DoStuffCore()
{
StringBuilder builder = new StringBuilder();
builder.AppendLine("I am really Class C. My dependency says:");
builder.Append(this.a5_.DoStuff());
return builder.ToString();
}
}
The other classes are implemented in a similar way; ClassB, for example, only communicates with Abstraction3 and Abstraction4 and doesn't have any knowledge of ClassD or ClassC (let alone that in this configuration, ClassC consumes ClassE).
The executable must somehow construct the correct object graph. A common approach is to use the app.config file to define this hierarchy (for an example, Spring.NET supports this option). To properly identify which type to instantiate when an abstraction is requested, an assembly-qualified type name is provided in the configuration file, and reflection is used to create instances of the configured types.
This very common approach comes with a rather painful drawback: Since the executable application has no dependencies on any of its servers, none of the containing assemblies are automatically copied to the output directory. Although the application compiles, it crashes when executed because Fusion is unable to locate the assemblies specified in the configuration file.
To work around this, you can either put all of your assemblies in the GAC or copy them to the relevant output directory, but both of these options are either repetitive or requires automation. In any case, this drawback can be a bit counter-productive during development.
Another approach is simply to code the desired configuration into the top-level executable. Whether this is a viable option depends on your reason for isolating your volatile dependencies in the first place. If your motivation is genuinely to support plug-ins or other extensibility models, configuration-driven Dependency Injection is certainly the right approach, and hard-coding a particular configuration is not an option. For other scenarios, however, this solves the problem of managing and deploying the correct assemblies.
In my example, the client will create the entire object hierarchy like this:
static void Main(string[] args)
{
Abstraction1 a1 = Program.CreateAbstraction1();
Abstraction2 a2 = Program.CreateAbstraction2();
Console.WriteLine(a1.DoStuff());
Console.WriteLine(a2.DoStuff());
Console.ReadKey(true);
}
private static Abstraction1 CreateAbstraction1()
{
return new ClassA();
}
private static Abstraction2 CreateAbstraction2()
{
Abstraction5 a5 = new ClassE();
Abstraction4 a4 = new ClassD();
Abstraction3 a3 = new ClassC(a5);
Abstraction2 a2 = new ClassB(a3, a4);
return a2;
}
Since all implementations use Constructor Injection, the client can construct the entire object tree by starting with the leaves and working its way to the root of the tree. Notice that although this creates an object hierarchy as illustrated above, the dependency hierarchy is flattened:
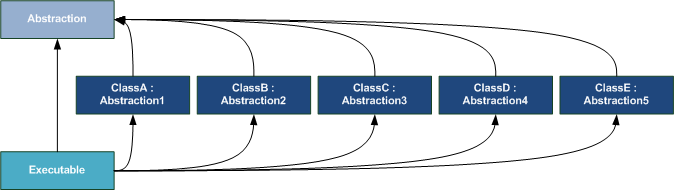
Apart from the top-level executable, each assembly only has a dependency on an assembly containing the abstractions (base classes and interfaces). Since such an assembly is considered a stable dependency, isolation has been achieved for all libraries. The only assembly with volatile dependencies is the top-level executable, but that's commonly where your UI resides, so it's not going to be testable in any case (and should be kept as minimal as possible).
Since the top-level executable has all relevant dependencies for the desired configuration, all required assemblies will automatically be part of the build.
Obviously, if you ever need to run the application in a different configuration, you will need to change the code, compile and redeploy, but that's not particularly different from the pure configuration scenario. Even if you use a configuration file, you will still need to compile and deploy your new or changed modules. In my opionion, it's the overhead of actually deploying even a single file that carries the greatest cost; whether you copy one or all of your files is merely a question of network or disk transfer time.
For applications where you control the entire code base and no extensibility support is required, the Code As Configuration technique can make development teams more productive without sacrificing significant functionality.