Backup Cloudera data to Azure Storage
Azure Blob Storage supports an HDFS interface which can be accessed by HDFS clients using the syntax wasb:// . The hadoop-azure module which implements this interface is distributed with Apache Hadoop, but is not configured out of the box in Cloudera. In this blog, we will provide instructions on how to backup Cloudera data to Azure storage.
The steps here have been verified on a default deployment of Cloudera CDH cluster on Azure.
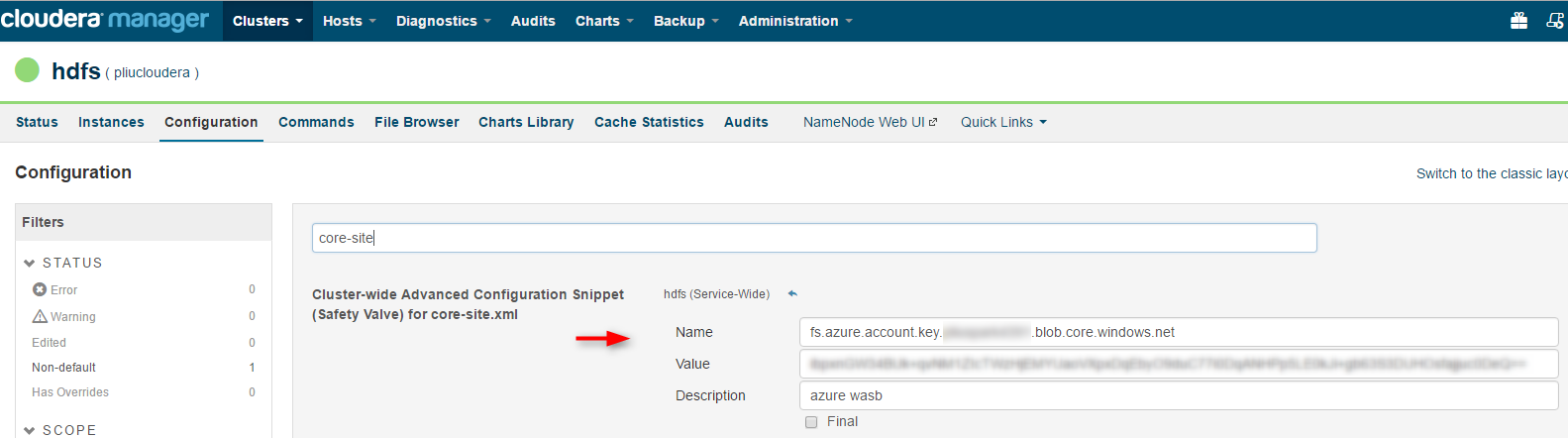
1. Go to Cloudera Manager, select HDFS, then Configuration, Search for "core-site", and add the following configuration to Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml, replace with your storage account name and key:
Name: fs.azure.account.key.<your_storage_account>.blob.core.windows.net
Value: <your_storage_access_key>
2. Redeploy stale client configurations, then restart all Cloudera services from Cloudera Manager.
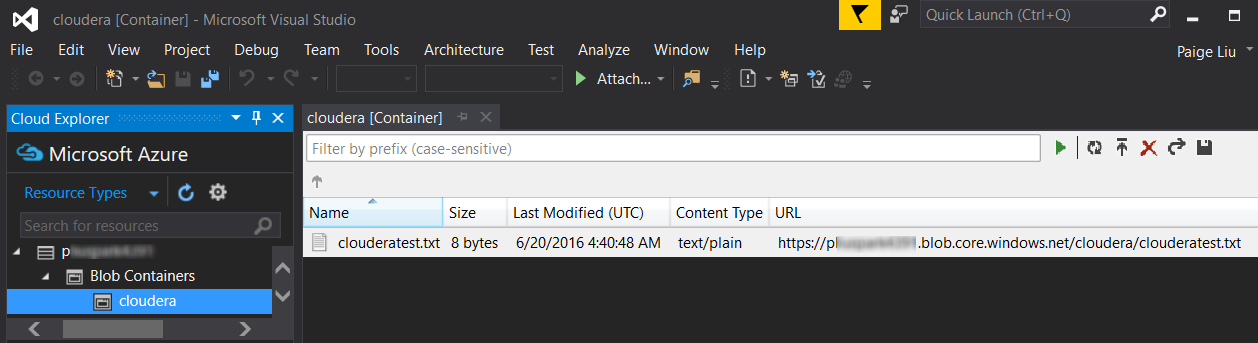
3. To test that Cloudera can access files in Azure storage, put some files in Azure storage. You can do so by using command line tools like AzCopy, or UI tools such as Visual Studio Server Explorer or Azure Storage Explorer.
4. SSH into any Cloudera node, run the following command. You may see some warnings, but make sure your can see the files in your Azure storage account. Note that if you don't specify a destination folder name, you must have the trailing slash in the wasb URL, as shown in the following example:
hdfs dfs -ls wasb://<your_container>@<your_account>.blob.core.windows.net/

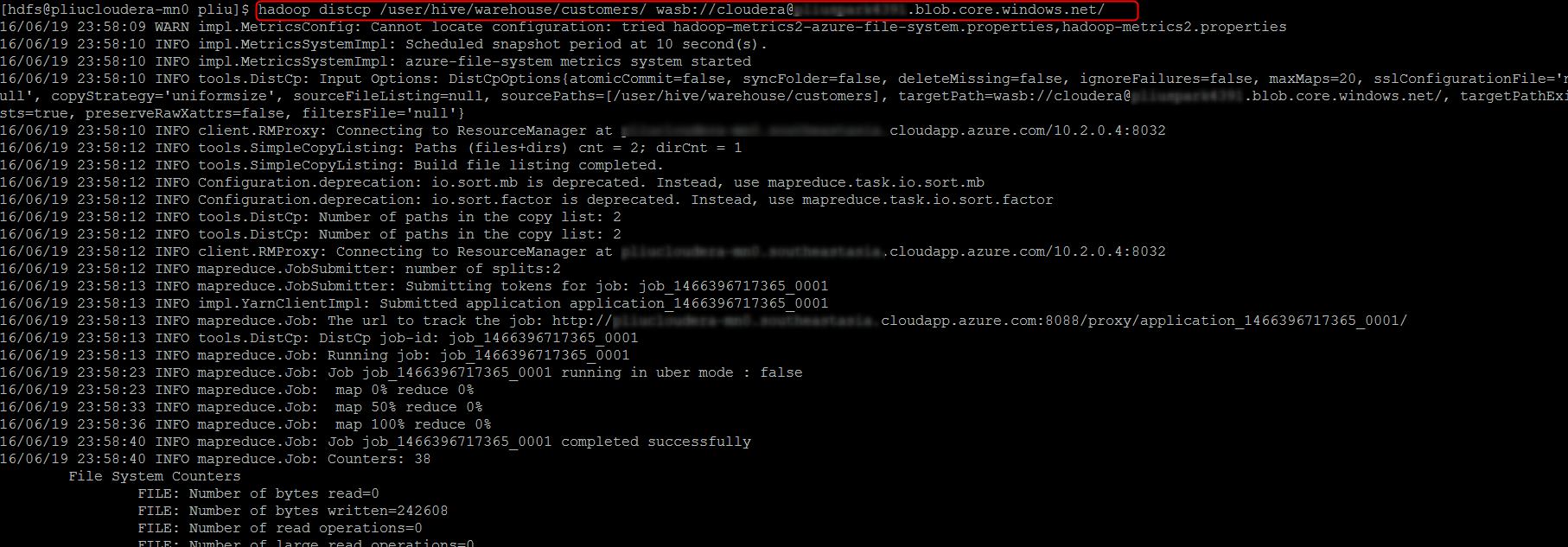
5. Run distcp on any Cloudera node to copy data from HDFS to Azure Storage.
# Run this command under a user who has access to the source HDFS files,
# for example, the HDFS superuser hdfs
hadoop distcp /<hdfs_src> wasb://<your_container>@<your_account>.blob.core.windows.net/
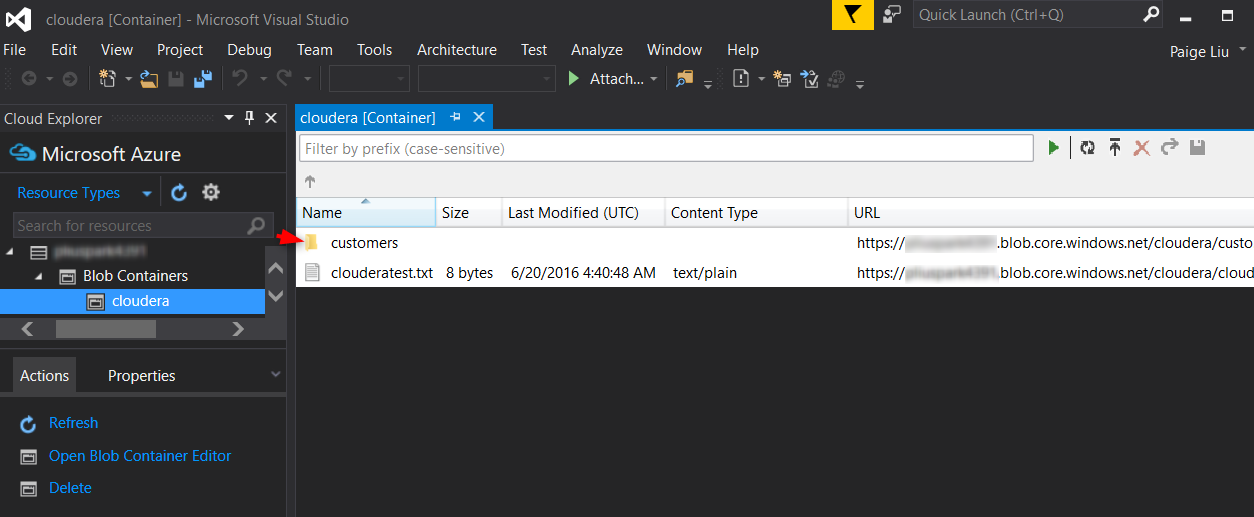
Now you should be able to see the source HDFS content showing up in Azure storage:
For more information about Hadoop support for Azure storage, please see this documentation.