Run Hue Spark Notebook on Cloudera
When you deploy a CDH cluster using Cloudera Manager, you can use Hue web UI to run, for example, Hive and Impala queries. But Spark notebook is not configured out of the box. Turns out installing and configuring Spark notebooks on CDH isn't as straightforward as is described in their existing documentation. In this blog, we will provide step by step instructions on how to enable Hue Spark notebook with Livy on CDH.
These steps have been verified in a default deployment of Cloudera CDH cluster on Azure. At the time of this writing, the deployed CDH is at version 5.7, HUE 3.9, and Livy 0.2. The steps should be similar for any CDH cluster deployed with Cloudera Manager. Note that Livy is not yet supported by Cloudera.
1. Go to Cloudera Manager, go to Hue and find the host name of the Hue Server.
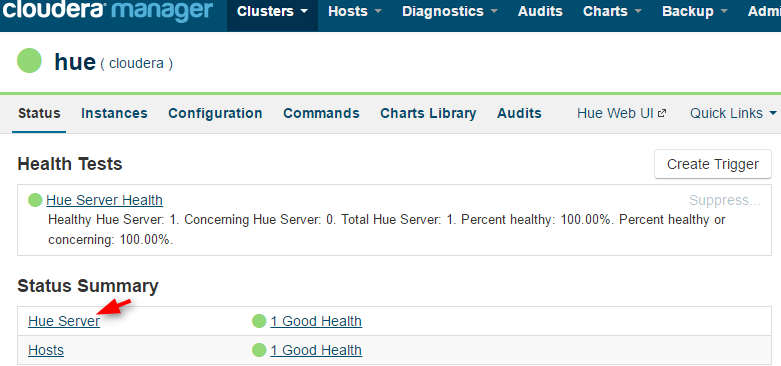
2. In Cloudera Manager, go to Hue->Configurations, search for "safety", in Hue Service Advanced Configuration Snippet (Safety Valve) for hue_safety_valve.ini, add the following configuration, save the changes, and restart Hue:
[desktop]
app_blacklist=
[spark]
server_url=https://<your_hue_server>:8998/
languages='[{"name": "Scala", "type": "scala"},{"name": "Python", "type": "python"},{"name": "Impala SQL", "type": "impala"},{"name": "Hive SQL", "type": "hive"},{"name": "Text", "type": "text"}]'
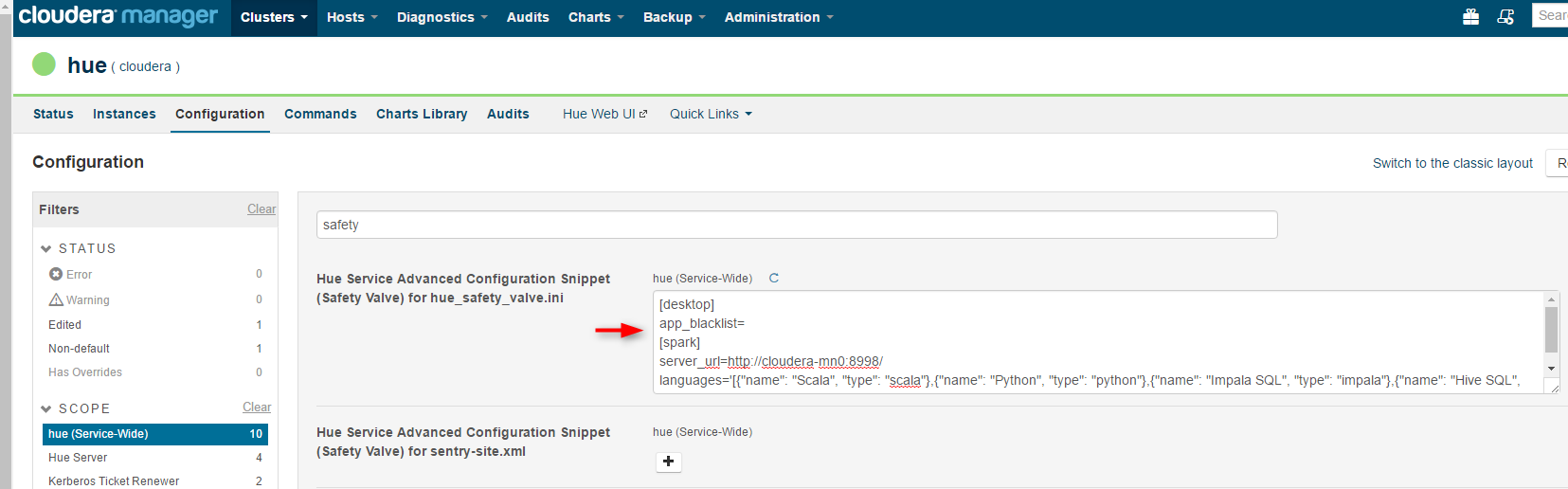
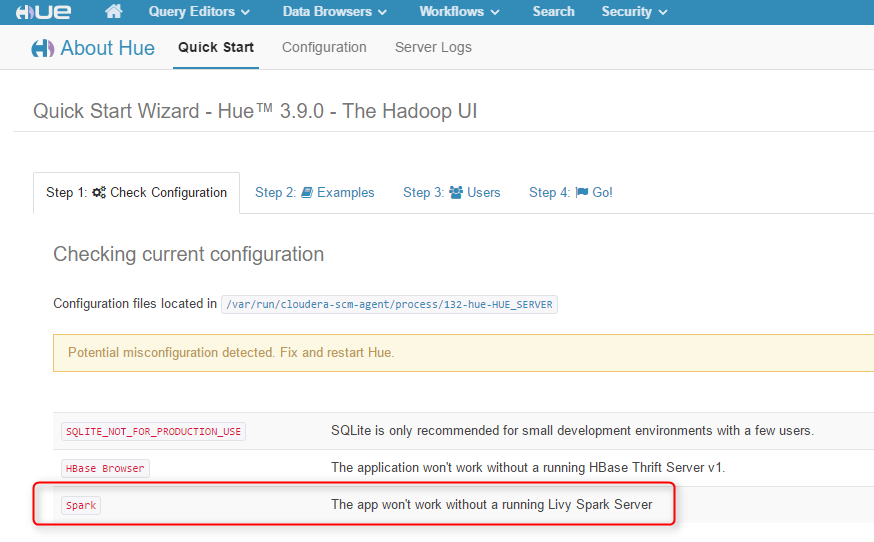
Now if you go to the Hue Web UI, you should be able to see the Spark notebook. The Spark notebook uses Livy to submit Spark jobs, so without Livy, it's not functioning yet.
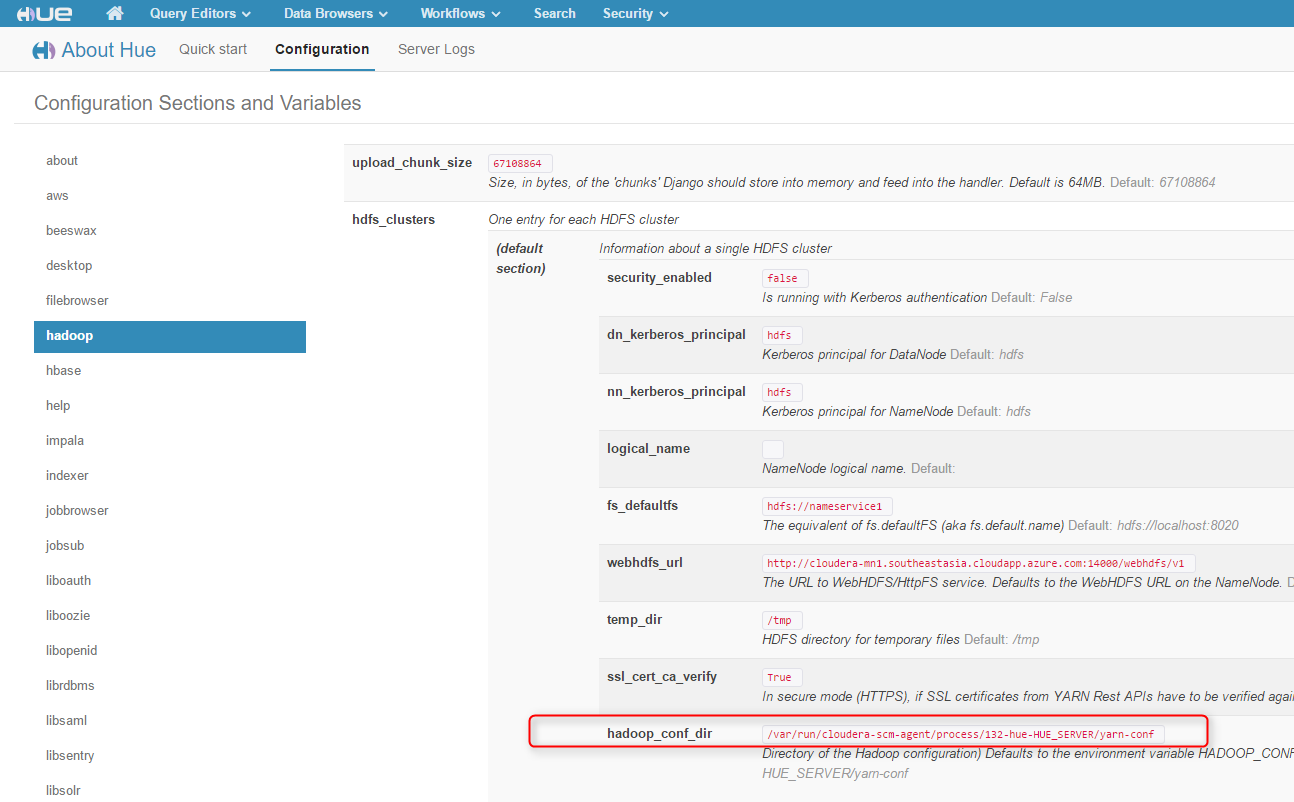
3. In the Hue Web UI, go to Configuration, find hadoop_conf_dir and note it down:
4. SSH to your Hue server, for simplicity, unless specified we'll run the following commands in sudo or as root user:
#download Livy
wget https://archive.cloudera.com/beta/livy/livy-server-0.2.0.zip
unzip livy-server-0.2.0.zip -d /<your_livy_dir>
#set environment variables for Livy
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark
export JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera
export HADOOP_CONF_DIR=<your hadoop_conf_dir found in the previous step in Hue configuration>
export HUE_SECRET_KEY=<your Hue superuser password, this is usually the user you use when you log in to Hue Web UI the first time>
#run Livy. You must run Livy as a user who has access to hdfs, for example, the superuser hdfs.
su hdfs
/<your_livy_dir>/livy-server-0.2.0/bin/livy-server
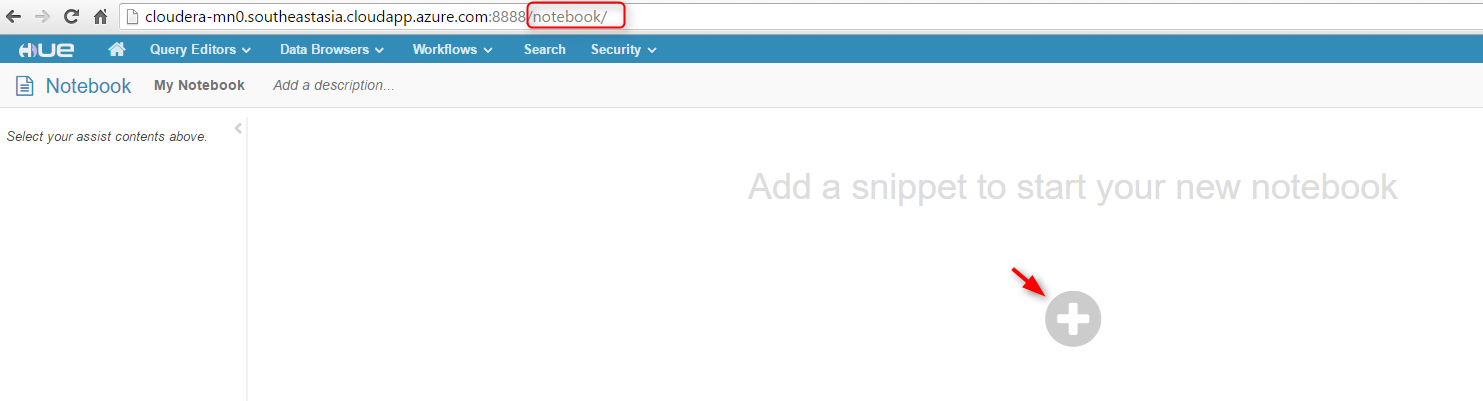
5. Now if you go to Hue Web UI again, the warning about Spark in Step 2 should be gone. Go to the root of your Hue Web UI URL, then add "/notebook" in the URL. You should be able to add a notebook to run code:
In the following example, we added a Scala snippet and ran it in the notebook:
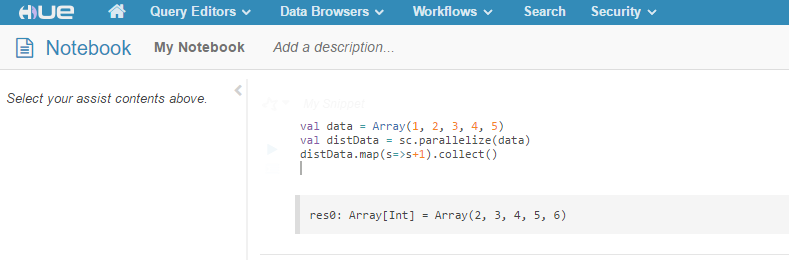
If you keep your ssh console with Livy running open, you will see when you start to run your code in a notebook, a Spark job is being submitted. If there's any error, you will also see it in the console.
You can also add Impala snippet, and use the various graphing tools:
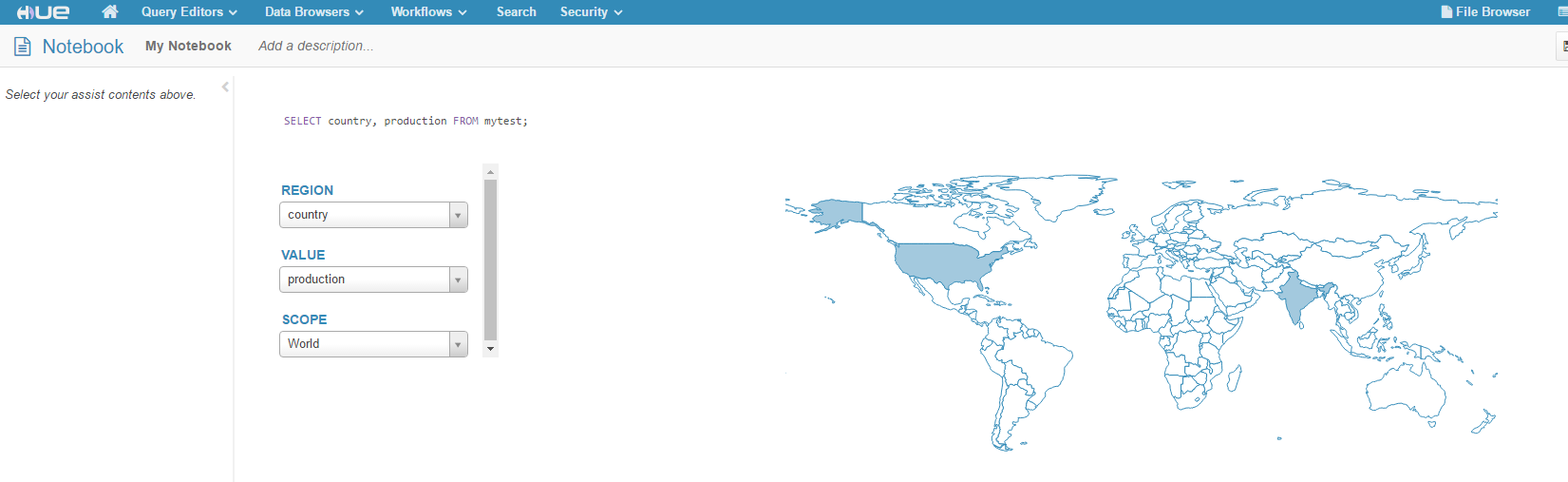
For more information about Hue Spark notebook, please see gethue.com/spark.