Beyond Hello World - Update 4, File loading 27 times faster!
CLCV V4 now loads files about 27 times faster than V3 when running on my laptop. The tree view is also about 5 times faster. This comes from changing my initial naive implementation to a smarter one where I minimize the inter-thread communication and handle the tree view much more efficiently. More information about the source code is at the bottom of this post. Here is what I learned in working on V4.
- Updating WPF UI elements can be expensive for large numbers of items. An effective and simple strategy is to only load data into WPF UI elements that the user actually needs to see - don't use WPF objects as the store for large numbers of objects.
- Updating pixels on the screen is expensive - even with relatively high performance hardware. Changing pixels (e.g. updating UI controls) at a rate faster than the monitor refresh rate is a waste of system resources, CPU time, GPU time, and memory bandwidth. UI updates that are related to (or driven from) high throughput tasks should be paced to no more than the monitor refresh rate.
V3 was the first functional version of CLCV and while it worked, it loaded files very slowly - talking 90 seconds or so (on my laptop) to load the largest data file (about 8.75MB in size). Given that the ultimate goal is to handle CSV files that hold data for the entire Windows Vista source code tree, I really needed to improve CLCV's performance.
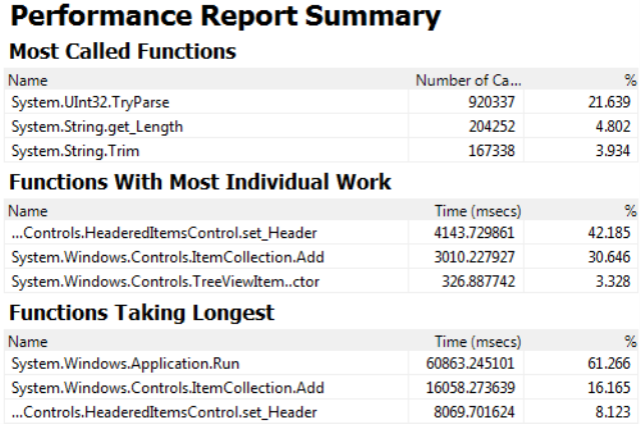
The cause of the performance problem was easy to find using the Visual Studio 2005 profiler. I simply enabled instrumented profiling and the offending code was obvious.
The most time consuming operation in V3 wasn't the actual file read time, it was the overhead of building the tree of tree view items. In V3, the file reading thread sent a message to the UI thread for every new file and directory from the CSV file. The UI thread then added that information to the tree of tree view control items as the file was read. This was very time consuming and took much longer than actualy reading the file.
It turns out that building a tree of tree view items is simply expensive. The most expensive part being setting the string that is displayed as the item's header. This is closely followed by actually making a new item the child of another (ItemCollection.Add). I don't yet know why this is expensive, only that it is. It may be because I'm building the tree bottom up instead of top down - Kiran Kumar discusses this as a potential issue here. I need to chat with my friend Tim Cahill the WPF performance guy about this a bit more.
For V4, I took a different approach: I re-factored the code so the file loading thread now does all the work of constructing a tree of objects that represent the original directory structure and its files. I also moved the logic that updates the progress bar from the UI thread to the file loader thread - only sending progress messages to the UI thread every 33 milliseconds (this is configurable).
The results were dramatically better. The file loader thread could read the file and re-construct the directory tree much faster than the previous version. On my laptop, the 8.75MB file could be loaded in about 1.47 seconds - not bad at all. In this version, the file loader thread sends a message to the UI thread to update the progress bar no more frequently than every 33 milliseconds (about 30 times per second). This is more than often enough so that the progress bar is visibily smooth, but not so much that updating the progress bar takes too long.
Experiment: Updating the progress bar is expensive - way to expensive to do this for every line read from the file. You can see how expensive this can be by using CLCV V4 and setting the "Progress Update Interval" in the options dialog box to 0. When this is zero, the file reading thread will send a message to the UI thread for every record read from the the CSV file. The messages get queued up in the UI threads dispatcher object and processed as fast as the UI can handle them. Processing all these messages and updating the progress bar takes a much longer time than processing the entire file! The lesson here is that the overall process of updating the UI (chaning pixels on the screen) is simply expensive. There is really no need to update the UI faster than the monitor refresh rate. Often about 1/2 to even 1/3 of the monitor refresh rate is just fine.
Note that for most things, a UI update rate of 30 or so updates per second will present a smooth animaition to the user. If needed, updating the UI faster -- at or close to the monitor refresh rate -- will work well.
Next, I needed a strategy for minimizing the costs of building the tree of tree view items that display the directory tree and files. Given that the file reader thread builds a tree structure, the solution was simple: CLCV V4 only populates the tree view control when it needs to, and only populates the items the user needs to see. After the file is loaded, the UI code updates the tree view with the top level elements. When the user expands an element, the UI thread then populates the data for that item's children.
In this way, CLCV only pays the costs for populating elements the user needs to see; only tree view items that will actually be displayed are created and added to the tree view item tree. This also amortizes the costs of the items displayed over the time the user actualy minipulates the control. So even if the user browses the entire three, he never experiences a sluggish tree view control.
Experiment: This works quite well, if you use CLCV version 3 to load the large test file (test-l.clc.csv) the first click on the bottom entry ("GSFD") will take a noticeably, and annoyingly, long time to expand ( about 2.5 seconds on my laptop). With V4, this happens quickly: it takes about 150ms to populate 922 child items (~6,000 items per second, or ~166us). It looks like it takes about anothe r300 milliseconds to draw the new items: its hard to measure this because WPF doesn't have a begin and ending events for item expansion (I just used a stop watch).
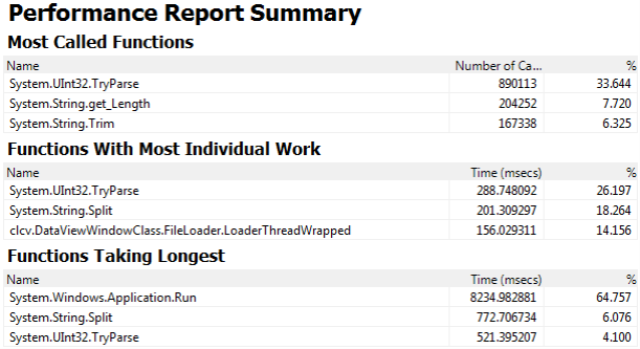
With V4, the profiler shows a very different picture: The bulk of the CPU time during file loading is spent actually parsing the text data from the file, primarily converting text fields to decimal values using UInt32.TryParse().
This is as expected. It probably isn't worth optimizing the conversion operations by writing a hand crafted text to Uint32 conversion routine as such a routine would need to handle localization and othe rissues. I expect it would only result modest performance improvements. The primary file loading bottleneck in V4 isn't CPU time, but I/O efficiency.
Loading a 8.75MB file in 1.47 seconds is pretty good - its about 6 MB/s; and its plenty fast enough for my intended scenario. But, it is still slow compared to other applications. I've developed other tools (such as CLC itself) that are completly I/O bound and use only one thread for the entire application. These tools easily drive the disk at its maximum sequential read rate of about 35 MB/s while handling much more complex string opeations than merely parsing some CSV data. For example, CLC is an order of magnitude faster than CLCV. The reason is the stream reader class - it doesn't do asynchronous or un-buffered I/O and its paying the cost of transcoding ANSI or UTF8 text into UTF16 for storing in .NET string objects.
In contrast, my natively implemented tools read files fully asynchronously in un-buffered mode. This makes I/O operations happen in paralell with data processing - not sequentially. They also parse the text data directly from the buffers populated by the operating system file read operation - no data copies are needed. Next, they handle ANSI and UNICODE directly - they don't transcode all input text to UTF-16.
Now this isn't to say that the StreamBuffer class is slow - it isn't. Using off the shelf I/O libraries in native C++ results in comparable performance to the .NET StreamBuffer class. The difference comes from using hand crafted I/O routines specificaly designed to for sequntial text line reading and maximizing parallism between disk I/O and computation.
One of my future tasks is writing a COM wrapper for my hand crafted C++ I/O libraries so they can be used efficiently from .NET languages. I expect this will allow CLCV to come very close to the file read performance of my native tools.
Source Code for this post: CLCV-BLOG-4.ZIP contains the source code to this post. I didn't include the data files in this zip file as they haven't changed - you can simpy use the ones from CLCV-BLOG-3.ZIP.