MS-PST - How to decode data pages using Permutative Decoding.
The current version of the MS-PST open specification document can be found here: https://msdn.microsoft.com/en-us/library/ff385210(office.12).aspx
Introduction
The PST is a structured binary file format that contains messages, folders, and attachments. The file structure can be logically separated into 3 layers: the Node Database (NBD) layer, the Lists, Tables, and Properties (LTP) layer, and the Messaging layer. Each layer builds on the one before and because of this it is necessary to completely understand the NDB layer before the LTP layer, and to understand the LTP layer before the Messaging layer.
This article assumes that you have also read my previous articles regarding the MS-PST file format. While it is not necessary to understand how the Node and Block BTrees work to make use of the information in this article, you may find it very useful. After all, if you don’t know how those work you will have a very hard time locating a data block in your own PST file to work with for the purposes of this article.
My previous articles can be found here:
Locate a Data Page to Decode
Section 2.4.1 contains a list of Special Internal NID values. I'm going to use the NID 0x122 which is for the NID_ROOT_FOLDER. Every PST file should have one of these and is where you would start of you wanted to access the e-mail stored in the PST file. In my clean PST file I found the NBTENTRY for NID 0x122 in the first page of the Node Btree.

Figure 1: NBT Page containing the NBTEntry with a NID value of 0x122.
If you have gone through either of my other 2 blogs on the PST file format you will notice that the bidData value is 0x64, which is what we need to locate the BBTENTRY in the Block BTree. I also found the BBTENTRY that I was looking for in the first page of the Block BTree.

Figure 2: BBT Page containing the BBTEntry with a bid value of 0x64.
The 13th BBTEntry is the one that we are looking for and it tells us that the data block associated with this node resides at offset 0x53C0 and contains 0x3E (62) bytes of data.
Data blocks exist on 64 byte boundaries and like BTPages they also have a block trailer of 16 bytes. So, you need to add the amount of raw bytes as specified by the cb, the block trailer, and then round up to the nearest multiple of 64. That is the actual size of the block.
62 + 16 = 78. Round up to the next multiple of 64, 128.
So, starting at file offset 0x53C0 read 128 bytes.
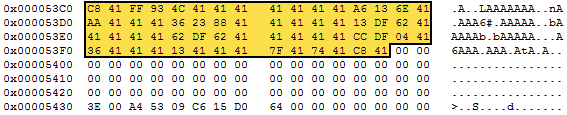
Figure 3: The 128-byte data block at file location 0x53C0.
How to Decode the Data
If you tried to make sense of the 62 bytes highlighted above you won't get very far. That is because the bytes are encoded. Look in the Header at the bCryptMethod property. This should be at offset 0x201 in a Unicode PST file. In my PST file the value is 0x01. According to section 2.2.2.6, 0x01 means NDB_CRYPT_PERMUTE. The algorithm for this encoding/decoding method can be found in section 5.1.
The majority of the code in this section is taken up by the mpbbCrypt byte array. You need to copy this as-is and be careful not to make any changes to it.
byte mpbbCrypt[] =
{
65, 54, 19, 98, 168, 33, 110, 187,
244, 22, 204, 4, 127, 100, 232, 93,
30, 242, 203, 42, 116, 197, 94, 53,
etc...
};
Following that, we have some #define pre-processor directives followed by the CryptPermute function written in C++:
#define mpbbR (mpbbCrypt)
#define mpbbS (mpbbCrypt + 256)
#define mpbbI (mpbbCrypt + 512)
void CryptPermute(PVOID pv, int cb, BOOL fEncrypt)
{
byte * pb = (byte *)pv;
byte * pbTable = fEncrypt ? mpbbR : mpbbI;
const DWORD * pdw = (const DWORD *) pv;
DWORD dwCurr;
byte b;
if (cb >= sizeof(DWORD))
{
while (0 != (((DWORD_PTR) pb) % sizeof(DWORD)))
{
*pb = pbTable[*pb];
pb++;
cb--;
}
pdw = (const DWORD *) pb;
for (; cb >= 4; cb -= 4)
{
dwCurr = *pdw;
b = (byte) (dwCurr & 0xFF);
*pb = pbTable[b];
pb++;
dwCurr = dwCurr >> 8;
b = (byte) (dwCurr & 0xFF);
*pb = pbTable[b];
pb++;
dwCurr = dwCurr >> 8;
b = (byte) (dwCurr & 0xFF);
*pb = pbTable[b];
pb++;
dwCurr = dwCurr >> 8;
b = (byte) (dwCurr & 0xFF);
*pb = pbTable[b];
pb++;
pdw++;
}
pb = (byte *) pdw;
}
for (; --cb >= 0; ++pb)
*pb = pbTable[*pb];
}
How is your C++? Can you tell what is going on here? Why are we working with DWORDs if it's a byte array and what's with all that bit shifting? It's actually a lot simpler than it looks. When you break this down to what needs to be done to decode each individual byte this is what is really happening:
- Get the byte to be decoded from the source byte array.
- Perform a bitwise AND operation with the value of the byte and the value 0xFF.
- If decoding, start at index 513 of the mpbbcrypt byte array, add the value from step 2 to the index, and retrieve the value.
- If encoding, start at index 0 and do the same thing.
It's possible to simplify the code quite a bit for readability purposes. Here is an example of what it might look like written in C#.
public void CryptPermute(byte[] pv, int cb, bool fEncrypt)
{
int idx = (fEncrypt ? 0 : 512);
int temp = 0;
for (int pvIndex = 0; pvIndex < cb; pvIndex++ )
{
temp = pv[pvIndex];
temp = temp & 0xFF;
pv[pvIndex] = mpbbCrypt[temp + idx];
}
}
If you're only interested in decoding purposes you can simplify it even more by removing the fEncrypt parameter and the idx variable.
public void DecryptPermute(byte[] pv, int cb)
{
int temp = 0;
for (int pvIndex = 0; pvIndex < cb; pvIndex++)
{
temp = pv[pvIndex];
temp = temp & 0xFF;
pv[pvIndex] = mpbbCrypt[temp + 512];
}
}
That's it? Yes, it really is. When decoded those 62 encoded bytes look like this. Notice that only the highlighted bytes have changed. The padding and PageTrailer are not processed by the decryption method.
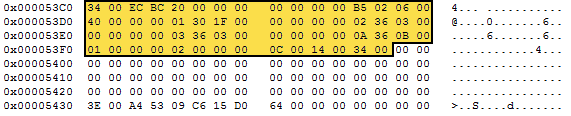
Figure 4: Decrypted 62-byte data block.
So, what do you do with those decrypted bytes? That will be a topic for a future blog.