RDP 6.0 Bulk Decompression Walkthrough
n a previous blog, RDP 6.0 Bulk Compression Walkthrough, we looked at how a data stream is compressed using RDP 6.0. This blog will take the compressed data that is sent over the wire to an RDP client and then decompressed to obtain the original data. Most of this blog will center on [MS-RDPEGDI] Remote Desktop Protocol: Graphics Device Interface (GDI) Acceleration Extensions Section3.1.8.1.4.4 Decoding a Compressed Stream. This blog will mainly include only details that are important to the example walkthrough itself. Important details not covered here can be found in section 3.1.8. RDP version 6.0 supports an extension to the compression techniques described in [MS-RDPBCGR] Remote Desktop Protocol: Basic Connectivity and Graphics Remoting Specification section 3.1.8. This extension is called "RDP 6.0 Bulk Compression" (RDP6.0-BC) and is only supported for server-to-client traffic.
[MS-RDPEGDI] https://msdn.microsoft.com/en-us/library/cc241537(PROT.10).aspx
[MS-RDPBCGR] https://msdn.microsoft.com/en-us/library/cc240445(v=PROT.10).aspx
There are 6 tables and a flowchart that are needed to walk through the sample data. These can be found under [MS-RDPEGDI] 3.1.8.1.4.1 Literal, EOS, and Copy-Offset Tables and [MS-RDPEGDI] 3.1.8.1.4.4 Decoding a Compressed Stream respectively.
All of the tables are used for both compression and decompression. I will not be reproducing the tables here. They can be found in either the [MS-RDPEGDI] document or in my RDP 6.0 Bulk Compression Walkthrough blog. Here is a list of the tables we will use along with the flowchart for Decompression. You may find it easier to print these off in order to follow the walkthrough.
RDP 6.0 Compression Walkthrough blog
Table 1: Bit-lengths for the 294 Huffman-encoded LiteralOrEosOrCopyOffset codes
Table 2: Huffman codebook for the 294 Huffman-encoded LiteralOrEosOrCopyOffset codes
Table 3: Bit count and base value lookup tables to encode and decode copy-offset values
Table 4: Table 4: Bit lengths for the 32 Huffman-encoded LengthOfMatch codes
Table 5: Huffman codebook for the 32 Huffman-encoded LengthOfMatch codes
Table 6: Bit count and base value lookup tables to encode and decode length-of-match values
The following flow chart describes how the data in a compressed stream is decoded.
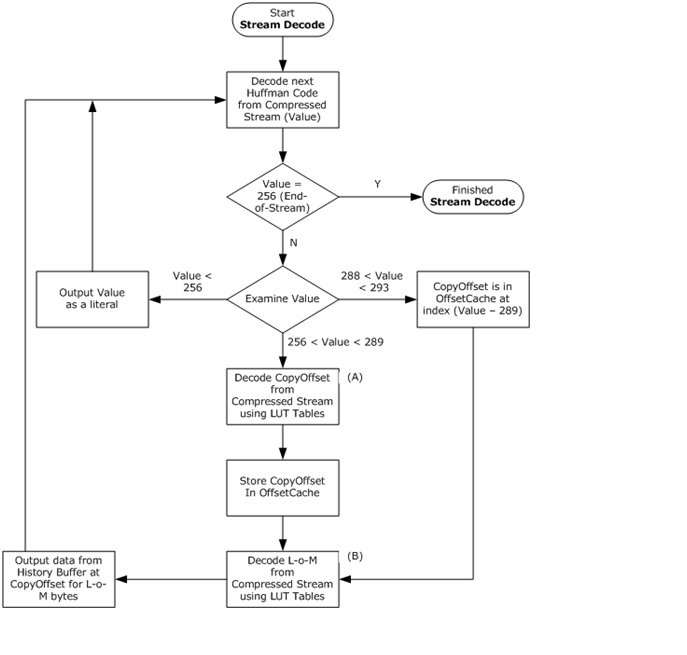
Decoding a compressed stream
Decoded literals are merely placed on to the output stream. However, decoded values representing copy-offset and length-of-match items (copy-tuples) require further processing by using the lookup tables.
Let's take a look at some important concepts before we look at the example. The shared state necessary to support the transmission and reception of RDP6.0-BC compressed data between a client and server requires a history buffer and a current offset into the history buffer (HistoryOffset). The size of the history buffer is 64 KB. The HistoryOffset MUST start initialized to zero, while the history buffer MUST be filled with zeros. After it has been initialized, the entire history buffer is immediately regarded as valid.
In addition to the history buffer and HistoryOffset, a small cache MUST also be managed by the client and server endpoints. This cache is referred to as the OffsetCache and is used to store the last four unique copy-offsets encountered during data compression (copy-offsets are described in [MS-RDPBCGR] section 3.1.8.1). This saves on bandwidth in cases where there are many repeated copy-offsets. Whenever the history buffer is initialized or reinitialized, the OffsetCache MUST be emptied. The uncompressed data is first inserted into the local history buffer at the position indicated by HistoryOffset by the sender. The compressor then runs through the length of newly added uncompressed data to be sent and produces as output a sequence of literals (bytes to be sent uncompressed) or copy-tuples which consists of a <copy-offset, length-of-match> pair. The copy-offset component of the copy-tuple is an index into the history buffer (counting backwards from the current byte being compressed in the history buffer towards the start of the buffer) where there is a match to the data to be sent.
There are two algorithms that are also key in the decompression process.
1) Decoding the Copy-Offset
Decoding of the copy-offset is shown in the flowchart by the Action A item. The following describes the algorithm for decoding a copy-offset.
LUTIndex = DecodedHuffmanCode - 257
BaseLUT = CopyOffsetBaseLUT[LUTIndex]
BitsLUT = CopyOffsetBitsLUT[LUTIndex]
StreamBits = ReadBitsFromCompressedStream(BitsLUT)
CopyOffset = BaseLUT + StreamBits - 1
The ReadBitsFromCompressedStream function reads the number of bits specified by the parameter from the compressed stream.
2) Decoding the Length-of-Match
Decoding of the length-of-match is shown in the flowcharte by the Action B item. The following describes the algorithm for decoding a length-of-match
.
HuffmanCode = ReadNextHuffmanCodeFromCompressedStream()
LUTIndex = DecodeHuffmanCode(HuffmanCode, HuffmanCodeTable)
BaseLUT = LoMBaseLUT[LUTIndex]
BitsLUT = LoMBitsLUT[LUTIndex]
StreamBits = ReadBitsFromCompressedStream(BitsLUT)
LoM = BaseLUT + StreamBits
The ReadNextHuffmanCodeFromCompressedStream function reads the next Huffman code from the compressed stream, and the DecodeHuffmanCode function decodes the Huffman code given by the first parameter using the Huffman codebook table specified by the second parameter. The definitions of any remaining functions used in this pseudocode are the same as those described in
That should cover all of our bases, so let's get started!
Original Input Data : 01 00 00 00 0a 00 0a 00 20 00 20 00 80 00 80 00
Input to the Decoder: 24 89 d1 2e 79 64 32 60 c8 7d fd 6d 01 60 32 ee
24 89 d1 2e 79 64 32 60
0 1 2 3
01234567 89abcdef 01234567 89abcdef 01234567 89abcdef 01234567 89abcdef
00100100 10001001 11010001 00101110 01111001 01100100 00110010 01100000
aaaaaabb bbbbcccc cccCCCCCd ddddddee eeeeeEEf f f f f f f fg ggggGGGG GGGGGGGG
c8 7d fd 6d 01 60 32 ee
4 5 6 7
01234567 89abcdef 0123467 89abcdef 01234567 89abcdef 01234567 89abcdef
11001000 01111101 11111101 01101101 00000001 01100000 00110010 11101110
GGGZ
Step 1 - Found good code and length with 6 bits. Decode is a Literal
aaaaaa = 001001 (bLE) -- Transposed = 100100 (bBE) = 0x24 - Need to transpose back to the original encoded stream.
Table 2. 0x24 -> 0x01 at index 1 - Note the <examine value> decision in the flowchart, if < 256 output as a literal
Table 1. code index 1 = 6 bits (this is used for the encoding side only as the code is a huffman code (i.e. unique prefix code))
Output Stream: 0x01
History Buffer: 0x01
History Offset: 1
CopyOffsetCache:
Step 2 - Found good code and length with 6 bits Decode is a Literal
bbbbbb = 001000 (bLE) - (again start with 6 bits -- bbbbbb
Transposed = 000100 (bBE) = 0x04
Table 2. 0x04 -> 0x00 at index 0
Table 1. code index 0 = 6 bits (again this is used only for the encoding stage)
Output Stream: 0x01 0x00
History Buffer: 0x01 0x00
History Offset: 2
CopyOffsetCache:
Step 3 - Wrong Huffman code using 6 bits
Next Input: Try 6 bits first
(cccccc): 1001110 (bLE)
Transposed = 0111001 (bBE) = 0x39
Table 2. Code Index 258. Table 1 shows 7 bits are needed. I.e. wrong huffman code, so increase bitlength to 7 and try again.
Step 4 - Found good code and length with 7 bits
Next Input: 7 bits
(ccccccc): 10011100 (bLE) - add a bit and try again
Transposed = 00111001 (bBE) = 0x39
Table 2. 0x39 -> code index 258
Table 1. index 258 needs 7 bits. Confirmed.
See Flowchart: Decode value.
256<value<290 -> decode copyoffset (Examine Value Conditional Branch)
Step 5 - Decode Copy-Offset
Decode Copy-Offset Using Table 3 - Bit count and Base Value lookup tables for encoding/decoding copy-offset values (See Decoding Copy-Offset algorithm from above)
LUTIndex = DecodedHuffmanCode - 257 = 258 - 257 = 1
BaseLUT = CopyOffsetBaseLUT[1] -> CopyOffsetBitsLUT = 0 CopyOffsetBaseLUT = 2
BaseLUT = CopyOffsetBaseLUT[LUTIndex] = 2
BitsLUT = CopyOffsetBitsLUT[LUTIndex] = 0
StreamBits = ReadBitsFromCompressedStream(BitsLUT) -- Need to read 0 (CopyOffsetBitsLUT) bits
CopyOffset = BaseLUT + StreamBits ( 1 = 2 + 0x0 - 1 = 1)
Store in CopyOffsetCache (as per the flowchart).
CopyOffsetCache: 0x01
Step 6 - Decode LoM
Flowchart - Decode LengthOfMatch bits using LUT Tables
Using Tables 5 and 4 to get the 32 Huffman Encoded LengthOfMatch bits
(CCCC): 1000 (bLE)
Transposed = 0001 (bBE) = 0x01
Use Decoding LoM algorightm
Table 5 - Codebook for 32 Huffman-encoded LoM codes -- Code Index -> 0 (index found using Huffman code of 1)
Table 4 - Bit Lengths Confirms 4 bits. Code Index - 0
Using Tables 6 Bit count and base value lookup tables for encoding/decoding LoM values
LoM = BaseLUT + StreamBits
LUTIndex = 0
BaseLUT = LoMBaseLUT[0] = 2
BitsLUT = LoMBaseLUT[0] = 0
StreamBits = ReadBitsFromCompressedStream(BitsLUT)
LoM = BaseLUT + StreamBits = = 2 + 0 = 2
Match Offset is calculated as 1 byte backwards from the CURRENT HISTORY OFFSET
Output at location 1 two bytes (note the buffer is reset to 0x00,0x00,0x00..0x00 at the start)!
-> 0x00 0x00
Output Stream: 0x01 0x00 0x00 0x00
History Buffer: 0x01 0x00 0x00 0x00
History Offset: 4
CopyOffsetCache: 0x01
Step 7 - Wrong Huffman Code trying with 6 bits
Next Input: try first 6 bits
(dddddd) 100101 (bLE)
Transposed = 101001 (bBE) = 0x29
Table 2. 0x29 at index 9
Table 1. Index 9 = 7 bits NOT 6. So continue Huffman decoding with now 7 bits.
Step 8 -- Found good code and length with 7 bits
Next Try: 7 bits
(ddddddd): 1001011 (bLE)
Transposed = 1101001 (bBE) = 0x69
Table 2. 0x69 -> Index 10 (oxoa)
Table 1. Index 10 -> 7 bits. Confirmed.
Value < 256 so a literal output it and add to history
Output Stream : 0x01 0x00 0x00 0x00 0x0a
History Buffer: 0x01 0x00 0x00 0x00 0x0a
History Offset: 5
CopyOffsetCache: 0x01
Step 9 - Wrong Huffman code trying 6 bits
Next Input: 6 bits
(eeeeee): 100111 (bLE)
Transposed = 111001 (bBE) = 0x39
Table 2. Code Index 258. Table 1 shows 7 bits are needed. I.e. wrong huffman code, so increase bitlength to 7 and try again.
Step 10 - Found good code and length with 7 bits
Next Input: 7 bits
(eeeeeee): 1001111 (bLE)
Transposeed = 1111001 (bBE) = 0x79 (121)
Table 2. 0x79 -> Index 259
Table 1. Index 259 -> 0x7 or 7bits confirmed
Figure 10. Decode Value.
256 < value < 289 -> decode copy-offset
Step 11 - Decode Copy-Offset
Using Table 3.
LUTIndex = DecodedHuffmanCode - 257 = 259 - 257 = 2
BaseLUT = CopyOffsetBaseLUT[2] ->
CopyOffsetBitsLUT = 0
CopyOffsetBaseLUT = 3
CopyOffset = BaseLUT + StreamBits -1 = 3 + 0x00 (no bits) -1 = 2
Add to CopyOffSet Cache at head
CopyOffsetCache: 0x02 0x01
Using Tables 5 and 4 to get the 32 Huffman Encoded LengthOfMatch bits
Step 12 - Decode LoM
(EE): 00 (bLE)
Transposed = 00 (bBE) = 0x00
Table 5. Code Index -> 1
Table 4. Confirms 2 bits.
Using Tables 6 to get match length parameteres
LUTIndex = 1
BaseLUT = LoMBaseLUT[1] = 3
BitsLUT = LoMBaseLUT[1] = 0
Need to read 0 (BitsLUT) additional bits to calculate Length of Match Value
LoM = BaseLUT + StreamBits = 3 + 0 = 3
Output a copy from location 2 bytes backwards from current history offset and count three bytes
-> 0x00 0x0a 0x00 (noting the history buffer is reset to 0x00,0x00..0x00 at start)
Output Stream : 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00
History Buffer: 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00
History Offset: 8
CopyOffsetCache: 0x02 0x01
Step 13 - Wrong Huffman Code with 6 bits
Next Try: 6 bits
(ffffff) 101100 (bLE)
Transposed = 001101 (bBE) = 0x0d
Table 2. 0x0d -> index 24
Table 1. index 24 -> 8bits Mismatch add a bit and decode again
Step 14 - Wrong Huffman Code with 7 bits
Next Try: 7 bits
(fffffff) 1011001 (bLE)
Transposed = 1001101 (bBE) = 0x4d
Table 2. 0x4d -> index 32
Table 1. index 32 -> 8 bits needed. Mismatch add a bit and decode again
Step 15 - Successful with 8 bits - Decode is a Literal
(ffffffff) 10110010 (bLE)
Transposed = 01001101 (bBE) = 0x4d
Table 2. 0x4d -> index 32 (0x20)
Table 1. index 32 -> 8 bits. verified.
Value < 256 so a literal output it and add to history
Output Stream : 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00 0x20
History Buffer: 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00 0x20
History Offset: 9
CopyOffsetCache: 0x02 0x01
Step 16 -- Found good code and length with 5 bits
(ggggg) 00011 (bLE)
Transposed = 11000 (bBE) = 0x18
Table 2. 0x18 -> index 289 (0x121)
Table 1. Index 289 -> 5 bits. Verified
288 < value < 293 (Flowchart - Examine value conditional)
Step 17 - Decode Copy offset from Cache
Using Table 3.
CopyOffsetCacheIndex = DecodedHuffmanCode - 289 = 289 - 289 = 0
CopyOffset Cache : 0x02 0x01 index 0 (head) -> 0x02 = 2
(We swap this value with the head of the cache -> NOP)
Step 18 - Decode LoM
Using Table 5 to decode next huffman encoded LoM index.
(GG) 0x00 (bLE)
Transposed = 00 (bBE) = 0x00
-> LoM Code Index 1
Table 4. Confirms 2 bits in length.
Using Table 6.
LoMBitsLUT[1] = 0
LoMBaseLUT[1] = 3
LoM = LoMBaseLUT + StreamBits (LoMBitsLUT) = 3 + 0
Output a copy from location 2 bytes backwards from current history offset and count three bytes
-> 0x00 0x20 0x00 (noting the history buffer is reset to 0x00,0x00..0x00 at start)
Output Stream : 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00 0x20 0x00 0x20 0x00
History Buffer: 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00 0x20 0x00 0x20 0x00
History Offset: 12
CopyOffsetCache: 0x02 0x01
Step 19 - Decode is a literal
(GGGGGGG) 1001100 (bLE)
Transposed = 0011001 (bBE) = 0x19
Table 2. 0x19 -> index 128 (0x80)
Table 1. Index 128 -> 7 bits. Verified
128 < 256 do a literal output it and add to history
Output Stream : 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00 0x20 0x00 0x20 0x00 0x80
History Buffer: 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00 0x20 0x00 0x20 0x00 0x80
History Offset: 13
CopyOffsetCache: 0x02 0x01
Step 20 - Found good code and length with 7 bits
Get next Huffman Code.
(GGGGG) 00011 (bLE)
Transposed = 11000 (bBE) = 0x18
Table 2. 0x18 -> index 289 (0x121)
Table 1. Index 289 -> 5 bits. Verified
288 > value > 293
Step 21 - Decode Copy offset from Cache
Using Table 3.
CopyOffsetCacheIndex = DecodedHuffmanCode - 289 = 289 - 289 = 0
CopyOffset Cache : 0x02 0x01 index 0 (head) -> 0x02 = 2
(We swap this value with the head of the cache -> NOP)
Step 22 - Decode LoM
Using Table 5 to decode next huffman encoded LoM index.
(GZ) 0x00 (bLE)
Transposed = 00 (bBE) = 0x00
-> LoM Code Index 1
Table 4. Confirms 2 bits in length.
Using Table 6.
LoMBitsLUT[1] = 0
LoMBaseLUT[1] = 3
LoM = LoMBaseLUT + StreamBits (LoMBitsLUT) = 3 + 0
Output a copy from location 2 bytes backwards from current history offset and count three bytes
-> 0x00 0x80 0x00 (noting the history buffer is reset to 0x00,0x00..0x00 at start)
Output Stream : 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00 0x20 0x00 0x20 0x00 0x80 0x00 0x80 0x00
History Buffer: 0x01 0x00 0x00 0x00 0x0a 0x00 0x0a 0x00 0x20 0x00 0x20 0x00 0x80 0x00 0x80 0x00
History Offset: 16
CopyOffsetCache: 0x02 0x01