Performance Comparison: Regex versus string operations
I consider regular expressions one of the most useful features ever. I use them a lot, not only when coding, but also when editing files and instead of copy and paste. I find the Visual Studio Find/Replace feature with regular expressions really useful as well. In case you are not familiar with it, you can use regular expressions to find and replace characters like this:
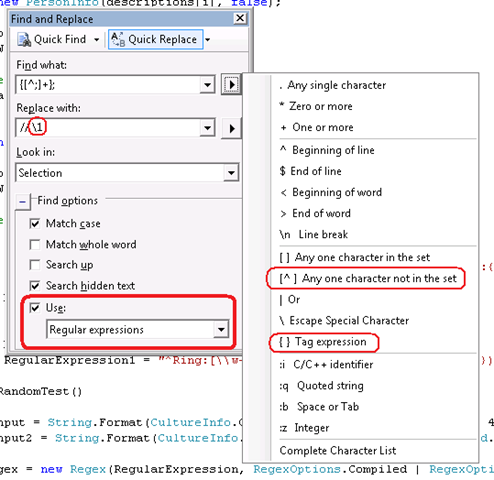
In the picture, I used the expression {[^;]+}; - meaning tag the string formed by any characters until ";" (at least one character) and replace the matching text with "// " followed by the tagged expression, forgetting the last ";". There are a lot of tutorials about regular expressions. I just learned the basics, and now I just try, fail, undo, and try again until I get it right.
Moving back to coding, .NET has great support for regular expressions. The classes are relatively easy to use (though at the beginning I had to play a while to find out how to capture strings in one match and other more advanced features). The biggest advantages I find in using Regex are that it makes parsing input very easy (once you have the regular expression in place) and it makes it much harder to introduce bugs - less code has by definition fewer bugs, and parsing with regular expressions requires less code than the traditional method of parsing strings with different string methods like get substring at different indexes, check that is starts or ends with certain characters etc.
However, there are cases when the string concatenation and parsing is better than the regular expressions: when the checks are done on a path that is executed a lot (a hot path), and that has strict performance requirements. Why? The regular expressions are slower than string concatenation.
I did a simple experiment and measured the time needed by regex and strings to perform the same operations. I considered I need to keep data about persons in the format "Firstname:Oana Lastname:Platon Money:2183 UniqueIdentifier:fwsjfjehfjkwh8r378". I have defined a constant that represents this format, and I'll use it to serialize the person data.
const string nameFormat = "Firstname:{0} Lastname:{1} Money:{2} UniqueIdentifier:{3}";
The data must be serialized and deserialized a lot of times (lets say that we need to send the data on the wire frequently or something like that). When deserializing the data, we need to make sure that it respects the pattern and then we need to extract the firstname, lastname etc.
1. Using regular expressions
I defined a regular expression like this:
static Regex regex = new Regex("^Firstname:(\\w+)\\sLastname:(\\w+)\\sMoney:(\\d{1,9})\\sUniqueIdentifier:([\\w-]+)$", RegexOptions.IgnoreCase | RegexOptions.Compiled);
Then, the code to parse the expressions and get the desired data is:
void ParseWithRegex(string description)
{
Match m = regex.Match(description);
if (!m.Success)
{
throw new ArgumentException("description doesn't follow the expected format");
}
this.firstname = m.Groups[1].Value;
this.lastname = m.Groups[2].Value;
if (!int.TryParse(m.Groups[3].Value, out this.age))
{
throw new ArgumentException("age doesn't have the correct value");
}
this.uniqueIdentifier = m.Groups[4].Value;
}
2. Using string operations
The verification that the given string respects the format becomes more difficult. In our case, the patters is pretty simple, but imagine that we needed to check an email address or something more complicated. In that case, the code would have had a lot of cases, to follow all possible solutions.
void ParseWithStrings(string description)
{
string[] parts = description.Split(new char[] { ' ', '\t' });
if (parts.Length != 4)
{
throw new ArgumentException("description doesn't follow the expected pattern");
}
this.firstname = parts[0].Substring(parts[0].IndexOf(":") + 1);
this.lastname = parts[1].Substring(parts[1].IndexOf(":") + 1);
if (!int.TryParse(parts[2].Substring(parts[2].IndexOf(":") + 1), out this.age))
{
throw new ArgumentException("age doesn't have the correct value");
}
this.uniqueIdentifier = parts[3].Substring(parts[3].IndexOf(":") + 1); ;
}
See that this is much more error prone than the previous code, because it needs to look at a lot of indexes and to substract the desired part of the string.
However, when I run the 2 methods in a loop and I measure how long they take with a stopwatch (from System.Diagnostics namespace), I get these results:
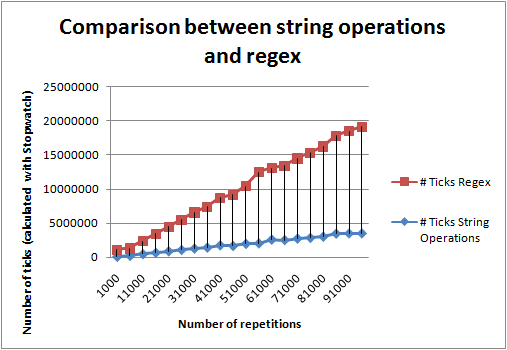
In conclusion, when choosing between using traditional string parsing or regular expressions, I would recommend:
- Start with regular expressions; if the path is not a hot path and doesn't have any strict performance requirements, this is the best choice, since it makes the code easier to read and maintain.
- If the performance goals are not reached (which means you have performance goals and you measured the performance!), try to improve your regular expressions. For example, adding ^ and $ (to specify that the pattern you are looking for is at the beginning or at the end of the string) when appropriate can improve the performance a lot. Also, make sure you use compiled expressions (if possible).
- If you are still not in graphic, replace the regular expressions with string concatenation and parsing.