Ntfs Misreporting Free Space (Part 2)
Continuing our discussion on the internals of disk usage, we will now shift our focus to internal metadata usage.
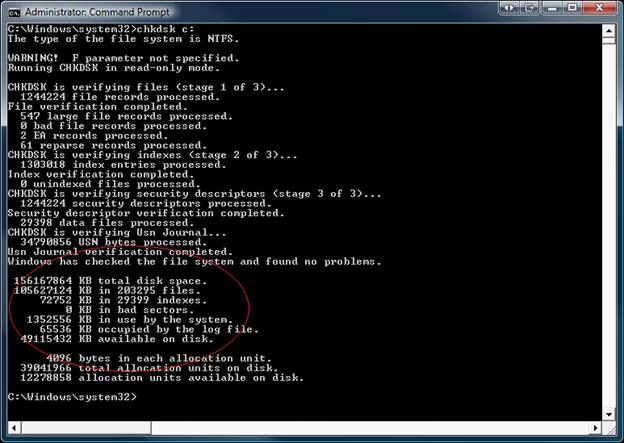
…….. KB in …. Indexes.
Consider for a moment a world without indexes… The $MFT is a database containing records that are accessed via FRS (file record segment) numbers. This FRS number includes an embedded sequence number that is updated anytime a file record is deleted & re-used. A file record must have a new identity once it has been deleted & re-used, so the sequence number is part of this unique identity. Without indexes, you would have to find files by remembering their FRS / Sequence numbers. It would be like remembering your favorite web sites by remembering the IP addresses. In this way, file indexes are like a DNS database so we don’t have to find files using FRS numbers. The folder structure has a reserved FRS number for the root. On all NTFS volumes, the root folder is FRS 0x5. Since the root is in a well known location, it can be accessed without doing any index lookups.
Each folder is like a set of DNS records containing information about a domain in the name space. The records contain information about the names and FRS numbers for the files “in” the folder. I put “in” in quotes because the folder itself does not actually contain any files (just records containing basic information about the files). The files are actually records in the MFT that are accessed by FRS number, so the index entries map names to FRS numbers. Folders use two types of metadata streams: $INDEX_ROOT:”$I30” and $INDEX_ALLOCATION:”$I30” to track the names that exist in their namespace. The streams have an attribute type code and a name. For example, $INDEX_ALLOCATION is the attribute type, and the attribute name is “$I30”. The “$I30” name is a short tag indicating that the stream contains file name indexes (as opposed to security indexes, reparse indexes, etc.)
Why “$I30”? Filenames are largely alphanumeric, and the first alphanumeric character in the UNICODE table is 0x30 (48 for those who are hexadecimally challenged). “$I30” is a shorthand method for saying “Index that’s alphanumeric”.
When a file is created, the $FILENAME information is packaged into a name index record which is stored in the parent folder’s $I30 index. With the exception of having one or two $I30 related streams, there is very little difference between a file and a folder.
Now, let’s create a new folder "NewFolder" in the root, and look at the $I30 index entry created in the root for "NewFolder".
D:\>md d:\NewFolder
D:\>dir d:\
Volume in drive D is d
Volume Serial Number is 4447-4F88
Directory of d:\
10/08/2008 02:42 PM <DIR> NewFolder
0 File(s) 0 bytes
1 Dir(s) 68,620,288 bytes free
If you open up an NTFS exploration tool and read the $INDEX_ALLOCATION:$I30 for the root folder, you will find an index entry in the root folder containing the filename “NewFolder”. In addition to NFI.EXE, there are some data recovery utilities that can be used to examine NTFS metadata, but I am not able to give any brand names on the blog. NFI.EXE is a useful tool for drilling down into NTFS, and it’s FREE in the OEM Support Tools Phase 3 Service Release 2. Since NFI is free, it is also not an officially “supported” utility. Despite this, NFI can tell you a lot of information about the allocated ranges of any file. Also, you can give it a logical sector number and it will find the file that owns the sector. For the purpose of this demonstration though, we will be using the standard command line interface “NFI.EXE C:” or “NFI.EXE [drive\path]”.
C:\Windows\system32>c:\shared\Disktools\nfi.exe d:\
NTFS File Sector Information Utility.
Copyright (C) Microsoft Corporation 1999. All rights reserved.
Root Directory
$STANDARD_INFORMATION (resident)
$FILE_NAME (resident)
$SECURITY_DESCRIPTOR (resident)
$INDEX_ROOT $I30 (resident)
$INDEX_ALLOCATION $I30 (nonresident)
logical sectors 78920-78927 (0x13448-0x1344f)
$BITMAP $I30 (resident)
Attribute Type 0x100 $TXF_DATA (resident)
Here is the sector in the root directory $I30 index allocation that contains our “NewFolder” index entry.
LBN 78922
0x0000 c6 06 3b 47 75 29 c9 01-c6 06 3b 47 75 29 c9 01 ╞.;Gu)╔.╞.;Gu)╔.
0x0010 c6 06 3b 47 75 29 c9 01-c6 06 3b 47 75 29 c9 01 ╞.;Gu)╔.╞.;Gu)╔.
0x0020 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
0x0030 06 00 00 20 00 00 00 00-07 00 24 00 53 00 65 00 ... ......$.S.e.
0x0040 63 00 75 00 72 00 65 00-0a 00 00 00 00 00 0a 00 c.u.r.e.........
0x0050 60 00 50 00 00 00 00 00-05 00 00 00 00 00 05 00 `.P.............
0x0060 c6 06 3b 47 75 29 c9 01-c6 06 3b 47 75 29 c9 01 ╞.;Gu)╔.╞.;Gu)╔.
0x0070 c6 06 3b 47 75 29 c9 01-c6 06 3b 47 75 29 c9 01 ╞.;Gu)╔.╞.;Gu)╔.
0x0080 00 00 02 00 00 00 00 00-00 00 02 00 00 00 00 00 ................
0x0090 06 00 00 00 00 00 00 00-07 03 24 00 55 00 70 00 ..........$.U.p.
0x00a0 43 00 61 00 73 00 65 00-03 00 00 00 00 00 03 00 C.a.s.e.........
0x00b0 60 00 50 00 00 00 00 00-05 00 00 00 00 00 05 00 `.P.............
0x00c0 c6 06 3b 47 75 29 c9 01-c6 06 3b 47 75 29 c9 01 ╞.;Gu)╔.╞.;Gu)╔.
0x00d0 c6 06 3b 47 75 29 c9 01-c6 06 3b 47 75 29 c9 01 ╞.;Gu)╔.╞.;Gu)╔.
0x00e0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
0x00f0 06 00 00 00 00 00 00 00-07 03 24 00 56 00 6f 00 ..........$.V.o.
0x0100 6c 00 75 00 6d 00 65 00-05 00 00 00 00 00 05 00 l.u.m.e.........
0x0110 58 00 44 00 00 00 00 00-05 00 00 00 00 00 05 00 X.D.............
0x0120 c6 06 3b 47 75 29 c9 01-e7 f8 69 2e d8 38 c9 01 ╞.;Gu)╔.τ°i.╪8╔.
0x0130 e7 f8 69 2e d8 38 c9 01-e7 f8 69 2e d8 38 c9 01 τ°i.╪8╔.τ°i.╪8╔.
0x0140 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
0x0150 06 00 00 10 00 00 00 00-01 03 2e 00 00 00 00 00 ...►............
0x0160 25 00 00 00 00 00 01 00-68 00 54 00 00 00 00 00 %.......h.T.....
0x0170 05 00 00 00 00 00 05 00-36 61 f9 9f 75 29 c9 01 ........6a∙ƒu)╔.
0x0180 8c 08 e1 8d 61 38 c9 01-8c 08 e1 8d 61 38 c9 01 î.ßìa8╔.î.ßìa8╔.
0x0190 8c 08 e1 8d 61 38 c9 01-00 00 00 00 00 00 00 00 î.ßìa8╔.........
0x01a0 00 00 00 00 00 00 00 00-00 00 00 10 00 00 00 00 ...........►....
0x01b0 09 00 4e 00 65 00 77 00-46 00 6f 00 6c 00 64 00 ..N.e.w.F.o.l.d.
0x01c0 65 00 72 00 6c 00 75 00-23 00 00 00 00 00 01 00 e.r.l.u.#.......
0x01d0 88 00 74 00 00 00 00 00-05 00 00 00 00 00 05 00 ê.t.............
0x01e0 f6 7d 8e 47 75 29 c9 01-a6 06 ab 47 75 29 c9 01 ÷}ÄGu)╔.ª.½Gu)╔.
0x01f0 a6 06 ab 47 75 29 c9 01-a6 06 ab 47 75 29 44 00 ª.½Gu)╔.ª.½Gu)D.
Below is the $I30 index entry in human readable format. Notice that it has everything needed to populate a WIN32_FIND_DATA structure, and most importantly, the FRS number of our newly created folder. The complete index record contains a duplicate copy of the $FILE_NAME attribute from the file record, and this allows FindFirstFile()/FindNextFile() to get all pertinent information about our found file without actually opening the file.
FileReference FRS,SEQ <0x25, 0x1> // FRS and Sequence number for "NewFolder"
ParentDirectory FRS,SEQ <0x5, 0x5> // FRS and Sequence number for the root folder.
CreationTime : 10/08/2008 LCL 14:40:04.520
LastModificationTime : 10/08/2008 LCL 14:40:04.707
LastChangeTime : 10/08/2008 LCL 14:40:04.707
LastAccessTime : 10/08/2008 LCL 14:40:04.707
Allocated Length : 0
File Size : 0
File Attribute Flags : 0x10000000 // Attribute flags
File Name : "NewFolder"
Now let’s do a pop quiz on indexes to see if everyone is on the same page…
Suppose that you write a fancy new application and you call FindFirstFile() / FindNextFile() in a loop. The cFilename string returned during one of the iterations is “MyFile.txt” (you also have the WIN32_FIND_DATA for the same file) .
1. Where did the name “MyFile.txt” come from?
2. If you call FindFirstFile()/FindNextFile() with a wildcard “*.*”, is it necessary to open each found file to retrieve the WIN32_FIND_DATA?
3. When you call FindFirstFile(), what is NTFS doing behind the scenes?
4. What happens when you close the search handle?
Answers
1. If you said “from the file’s parent folder’s $I30 index”, then you are correct.
2. If you said “no”, then you are correct. The WIN32_FIND_DATA is also retrieved from the $I30 index. There is no need to open the individual files to get this information.
3. When you call FindFirstFile, NTFS opens the $I30 index stream(s) for the target folder and scans through the index entries for the first record that matches the specified wild card. A search context is also created to keep track of the current search location in the index stream.
4. The target folder’s index handle is closed and the search context is freed.
If you passed the quiz (or at least understand the answers), you're ready to read on…
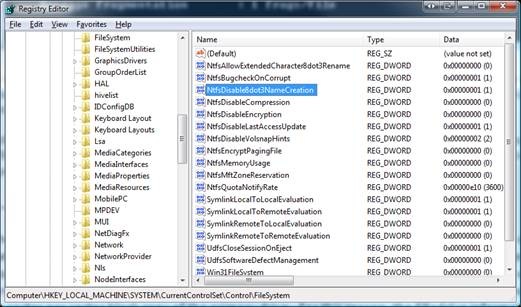
In short, high index usage is the result of having a large number of index entries. Common sense would dictate that you probably have the same number of indexes as you have files - Right? Well....the answer is not quite that simple. Suppose that you have 8.3 names turned on and you create a file called "tiny.txt". This file is both 8.3 and LFN compliant, so there will be exactly one index entry created for this file. Now consider what happens when you create a file named "MyFileHasAReallyLongName.txt". This is NOT 8.3 compliant, so NTFS will create an 8.3 name ("MyFile~1.txt"). Now NTFS has to maintain an 8.3 index entry, AND an LFN index entry for a single file. This effectively doubles index usage (plus, long filenames have to be stored in the index and that also makes the LFN filename index larger than normal). If you plan to create a large number of files on a volume, then it is a good practice to either use 8.3 compliant names, or disable 8.3 name creation altogether.
If you have a large folder and want to see how many bytes are in use by indexes, then use contig.exe (from https://technet.microsoft.com/en-us/sysinternals/bb545046.aspx) to find out the allocated length of the folder's $INDEX_ALLOCATION. Then divide this number by how many files are in the folder. That will give you bytes per index entry.
Below is an example of how to determine how to determine index stream size for a folder.
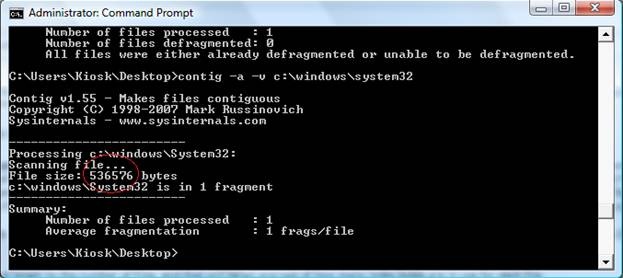
In my “System32” folder, I had a $I30 index allocation which was 536,576 bytes long. It contained records for 2,460 files, so this averages out to 218 bytes per index. The presence of 8.3 names can be discovered by running “DIR /X”. On my systems, I don’t have a need for 8.3, so I turned off 8.3 via the registry (refer to KB121007).
Whenever possible, try to distribute large numbers of files across several volumes. If you have to put millions of files on a single volume, try to keep your filenames short to save space and improve performance.
…….. KB in …. bad sectors.
When a bad sector is detected by CHKDSK /R or if a write occurs because of a bad sector on disk, the cluster that contains the bad sector will be added to the allocated range of $Badclus. If $Badclus contains any allocated ranges, then it's time to consider replacing the hard drive.
IMPORTANT: If you have a software mirrored volume, and one hard disk has bad sectors, then it is likely that one of the drives in the mirror is going to fail soon. If this happens, keep in mind that when you replace the failing drive, the regenerated mirror set will still still have sectors marked in the $Badclus file even though the mirror is healthy. Since a mirror is a perfect block-by-block copy of the volume, all information for all files is duplicated between the members (including $Badclus). For this reason, the $Badclus information is mirrored to the working drive as well as the failing drive.
…….. KB in use by the system.
System usage is comprised of $MFT, $Logfile, $Secure, and all other supporting structures in the MFT. If you are looking for system usage, you will need to drill down into the NTFS metadata files.
In most cases, high system usage cannot be “fixed”, but it can be kept under control by proper configuration and user education. NFI will give you the information about the size of the various internal metadata files, and you can research the details on how each of the internal system files work, but there simply isn’t enough room in a blog post to talk about them all. However, we will discuss the two most common problems that we see: 1. High $MFT usage, and 2. Bloated Security Stream in the $Secure File.
1. High $MFT Usage Every file on the volume is defined by ONE OR MORE file records that are exactly 1KB in size. If the MFT is large, it's because you have a large number of file records in the MFT (free records are also included in the total MFT size). Below are two different ways to view the MFT information. FSUTIL will show you the valid data length, while NFI will give a view of where the fragments of the $MFT:$DATA attribute are laid out on disk.
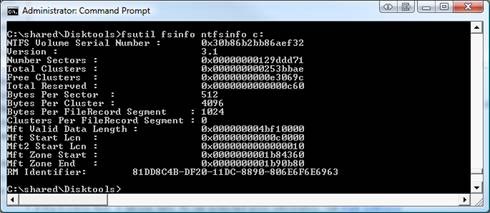
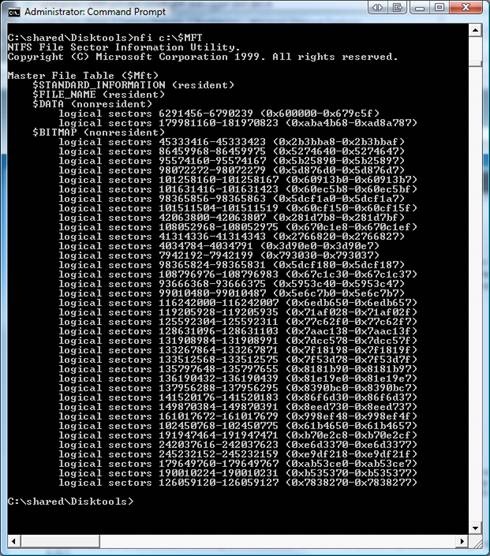
Unfortunately, if your $MFT is too big and you want it to be smaller, you will have to reformat the drive. Just keep in mind that once you restore your files, you will have 1KB of MFT allocated for each file on the drive (lots of extra file records are needed to restore your 20GB compressed files), but I will assume that everyone read part 1 and they are not going to do that. C|;3)
2. Bloated Security Stream in the $Secure File
Following good development practices will save you lots of headaches with your $Secure file. If you write applications that ACL & re-ACL files over and over and over, your $Secure file probably looks like mine (love those logon scripts from the IT department)…
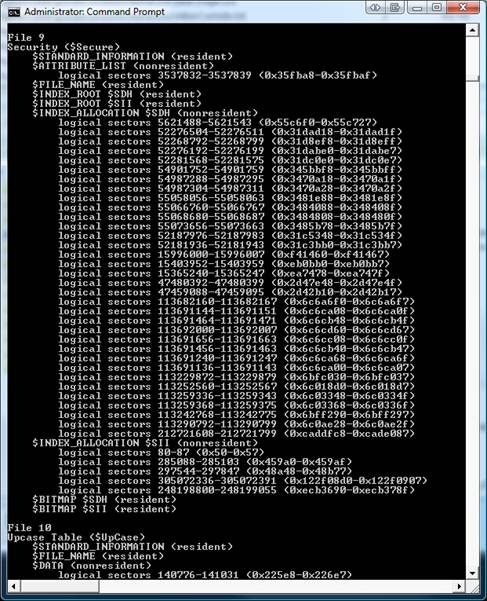
To those of you who are savvy with file system internals, you probably noticed something was missing in the picture above. The $Secure file shows $SII/$SDH INDEX_ROOT(s)/INDEX_ALLOCATION(s), but where is the actual security stream $DATA:$SDS?
There simply was no more room in the base file record for the $DATA:$SDS attribute, so it was moved to a child record. To find the child record, we can read the $ATTRIBUTE_LIST (via sector editor) and find the pointer to the file record(s) that hold the $SDS stream metadata. To keep the legal department happy, I can’t give you the data types, but I can tell you that my $DATA:$SDS stream (shown below) is split between two child records because the $SDS stream is heavily fragmented. The first child record is FRS 0x1888, and the other is FRS 0x12d7e. If you were to read those two file records, they would each contain the mapping information for approximately 400 fragments of my security stream.
LBN 3537832
0x0000 10 00 00 00 20 00 00 1a-00 00 00 00 00 00 00 00 ►... ..→........
0x0010 09 00 00 00 00 00 09 00-00 00 d4 00 09 00 00 00 ..........╘.....
0x0020 30 00 00 00 20 00 00 1a-00 00 00 00 00 00 00 00 0... ..→........
0x0030 09 00 00 00 00 00 09 00-07 00 24 04 53 65 53 63 ..........$.SeSc
0x0040 80 00 00 00 28 00 04 1a-00 00 00 00 00 00 00 00 Ç...(..→........
0x0050 88 18 00 00 00 00 37 00-00 00 24 00 53 00 44 00 ê↑....7...$.S.D.
0x0060 53 00 02 00 01 01 00 00-80 00 00 00 28 00 04 1a S.......Ç...(..→
0x0070 f9 01 00 00 00 00 00 00-7e 2d 01 00 00 00 0f 00 ∙.......~-......
0x0080 00 00 24 00 53 00 44 00-53 00 00 00 00 00 00 00 ..$.S.D.S.......
0x0090 90 00 00 00 28 00 04 1a-00 00 00 00 00 00 00 00 É...(..→........
0x00a0 09 00 00 00 00 00 09 00-60 17 24 00 53 00 44 00 ........`↨$.S.D.
0x00b0 48 00 00 00 00 00 00 00-90 00 00 00 28 00 04 1a H.......É...(..→
My security stream may look scary because it has 400 fragments, but it is only about 3.3MB plus the size of the $SII & SDH streams. If it were to grow past the 1GB range, I would start looking for the cause of the growth.
In theory, you can bloat your $SDS stream by creating lots of unique security descriptors, but this is usually not the cause of bloating. Instead, most mischief is caused by application developers who call SetFileSecurity() without properly preparing their security descriptor buffer.
Most applications:
1. Allocate some heap memory.
2. Init the SD via InitializeSecurityDescriptor().
3. Set up the ACE’s.
4. Assign security to the target object.
The problem is that heap memory is like recycled paper. When you call InitializeSecurityDescriptor() the first few bytes of your buffer will say “I’m a security descriptor”, but the ending bytes will have some text from an e-mail you decided not to send to your boss. As the SD is filled in with ACE’s, the letter to the boss is overwritten with the ACE’s. At that point, your buffer looks like a valid SD to the system, but there’s still some slack space at the end that says “Porsche destroyed in the fire. Yours truly, Larry”. When you send this buffer to SetFileSecurity(), NTFS takes this buffer and computes a hash value to determine whether this SD is unique (the salutation to your boss is also included in the hash). If the hash is identical to a hash value in the $SDH stream, then we do a comparison between the new & existing SD’s. If they match a byte-per-byte comparison, then the existing SD is used. If not, your new SD is added to the stream (along with the bad news about the boss’ car). To prevent this, always zero your entire security descriptor buffer prior to calling InitializeSecurityDescriptor(). You will prevent $SDS bloating and your boss will never know about the car.
I hope you all find this information useful in your sleuthing efforts.
Best regards,
Dennis Middleton “The NTFS Doctor”