Markdown Part 4 - Outlining
This is part of the "Markdown mode" series:
Part 3.5 - Posted on the VS Gallery
Part 3 - A live tool window previewer
A few nights ago, around midnight, I was in that I'm-pretty-tired-but-too-tired-to-fall-asleep-now state, and so decided to find something small that I could add to one of my extensions. Since Markdown Mode is the ripest for this type of thing, I decided to add outlining (a.k.a. folding) support for Markdown files:
Structure
Outlining regions tend to follow some type of structural decomposition of a file; in C#/VB/C++/etc., you get outlining regions for structural units like namespaces, structs/classes, methods/functions, and (sometimes) blocks. In Markdown, while there isn't an exact equivalent of these groupings, you can use the headers in a Markdown file to roughly break the file into sections.
The logic for this is fairly simple:
- A section starts at a header, such as an
H1orH3. - A section ends when you run into either:
- The end of the file, or
- A section of equal or greater "size", where
H1>H2> ... >H6.
- A section contains all sections between the start and endpoint (much as a namespace contains classes which contain methods which contain statements).
This code lives in MarkdownParser.ParseMarkdownSections, which is in MarkdownParser.cs. It returns an enumeration of these sections from first/largest to last/smallest.
Outlining
Once the decomposition logic exists, the outlining code is simple. Like many of the other features we've dealt with, this also uses tagging, exporting an ITagger<IOutliningRegionTag>. There's also a bit of logic for computing the collapsed form (what shows up in the editor when you collapse the region) and the collapsed hint form (what you see in a tooltip when hovering over the collapsed form). Still, the total size of OutliningTagger.cs is just under 100 lines, since the hard part is computing the sections.
Margin
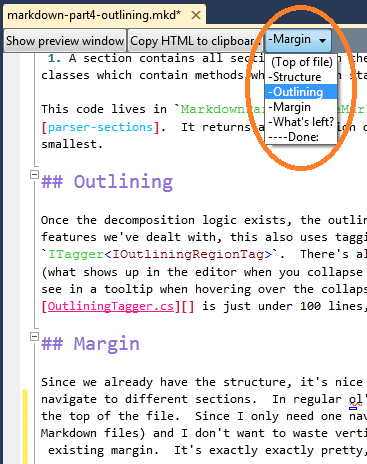
Since we already have the structure, it's nice to be able to see the structure and quickly navigate to different sections. In regular ol' code files, we get this in the navigation bar at the top of the file. Since I only need one navigation bar (there isn't a module/method split for Markdown files) and I don't want to waste vertical space, I just stuck a simple combo box onto the existing margin. It's exactly exactly pretty, but it gets the job done. I suppose there's an interesting conversation to be had here, in how much time/effort I should spend to make this visually congruous with the navigation bar; for my lack of talent in this area, it would probably take me longer to figure that out than it did to write this whole feature (which was about 45 minutes), so it isn't high on my list.
What's left?
Since outlining wasn't exactly on the list of features, I haven't exactly knocked anything off the TODO block. From this point on, however, I think I'm just going to add new features as I find them useful, so I've gotten rid of the "TODO" list and kept only list of things I've finished. I've also dropped the "no longer doing" portion of the list.
Done:
Outlining supportSpell checking support – my teammate Roman built a sample that does spell checking, so that would be nice to add, especially since I'm writing prose.Put the extension out on the VS Gallery!Syntax coloring (the obvious one); things like bold, italics, links, pre blocks and code blocks, etc.Turn URL labels into clickable hyperlinks – this is pretty easy to do with the new URL tagging support in the editor.A tool window for showing the current output (as a webpage) of the buffer I'm editing, updating live while I'm editing it. Alternatively, this may be just another document or a margin, depending on where I end up. I'm not very good at visual schtuff, so it'll probably be as simple as it can be and still get the job done.Syntax support for regular html – Markdown lets you use intersperse regular html into your Markdown files, so it would be nice to get these to be correctly syntax highlighted. This may actually be really simple (just using aContentTypethat derives from html), but if it isn't, it isn't high on my list, mostly because I don't tend to use it for anything other than anchor tags.