SP2013 - How to influence the Language detection at the document/item level
Hi Search Enthusiasts
Today I'd like to demonstrate a small workaround for language detection issues in SP2013.
Why document language is important ?
The language is at the center to any linguistics features in SP2013: Tokenization (wordbreaking), Stemming (lemmatization), Fuzzy Name matching, thesaurus etc.OOB we do our best to determine the primary language of any document or list item but as any automatic detection system, it might not be suitable to all cases.
When the content has a small text footprint like a DB row, a list item or else, it is even harder to automatically determine a language. List items is a common problematic.
Our Goal
Be able to control the language at the document or list item level (fine language granularity).
Steps by Steps
Here are the steps I took to achieve that goal.
1. Create a Site Column that will hold all potential languages I wish to force.

2. Call it ForcedLanguage (Multiple Choice type) and assign it to a different SiteColumn group ("SP2013 Search Default").
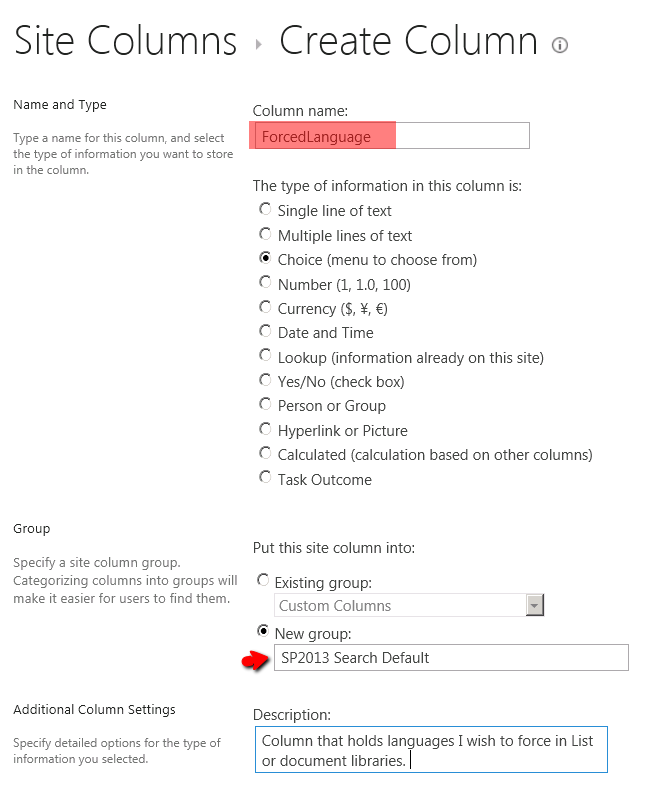
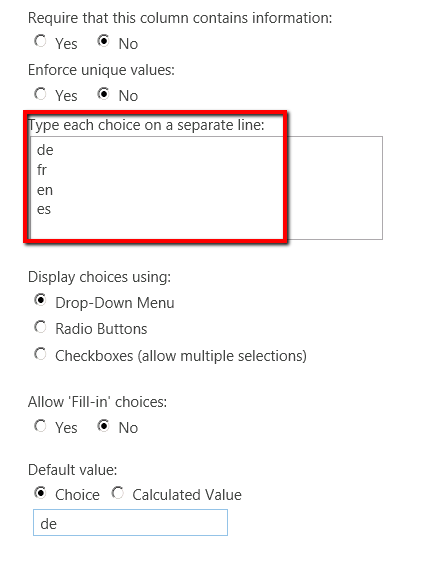
3. Define the list of languages you want granularity for and define the default value.
Now that we have our Site Column, we can start to use it across documents libraries or custom list.
4. We will use the default "Shared Documents" document library which I've update with a few text files.
In your document library settings, add the ForcedLanguage column to your library or list.
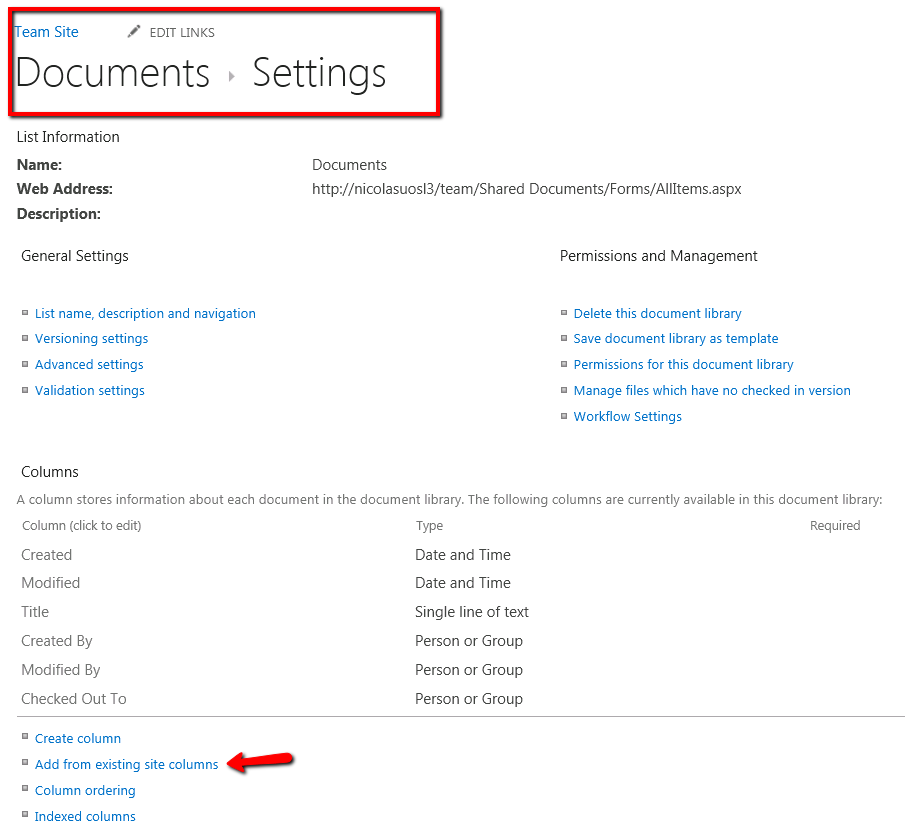
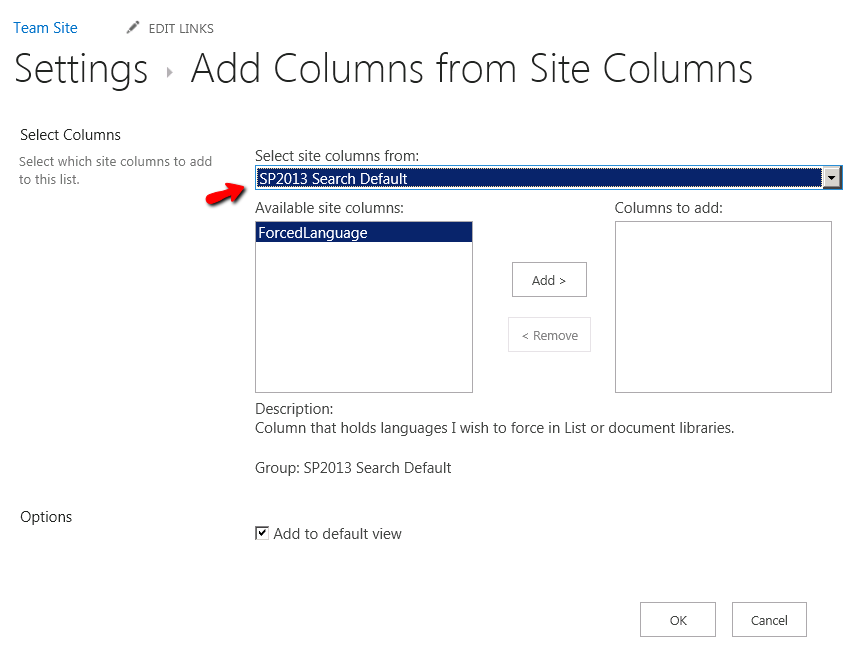
For the purpose of the demonstration I will add it to the default view as well.
5. Execute a full crawl
The full crawl will generate the necessary crawled properties associated with our new Site Column.
The crawled property ows_ForcedLanguage of type Text is the one we will use to map
6. For the sanity of the demonstration we will verify the default language our documents.
Using the SP2013 Search Query Tool (https://sp2013searchtool.codeplex.com/) , we can check the existing detected language. I'm querying the name of one of the log file I've uploaded.
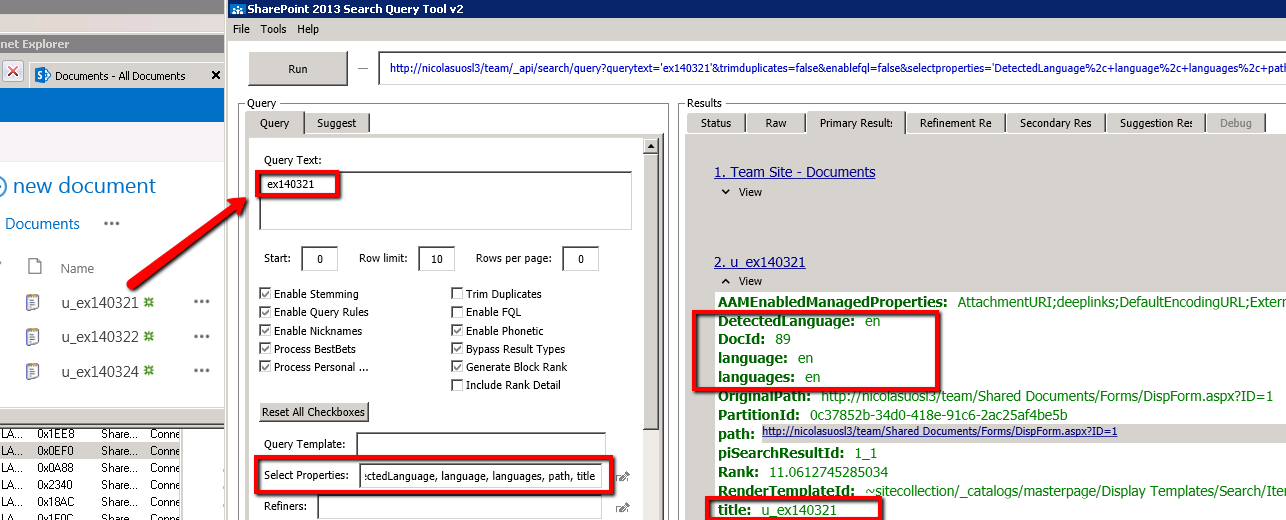
We can see English being the default language our items are assigned to.
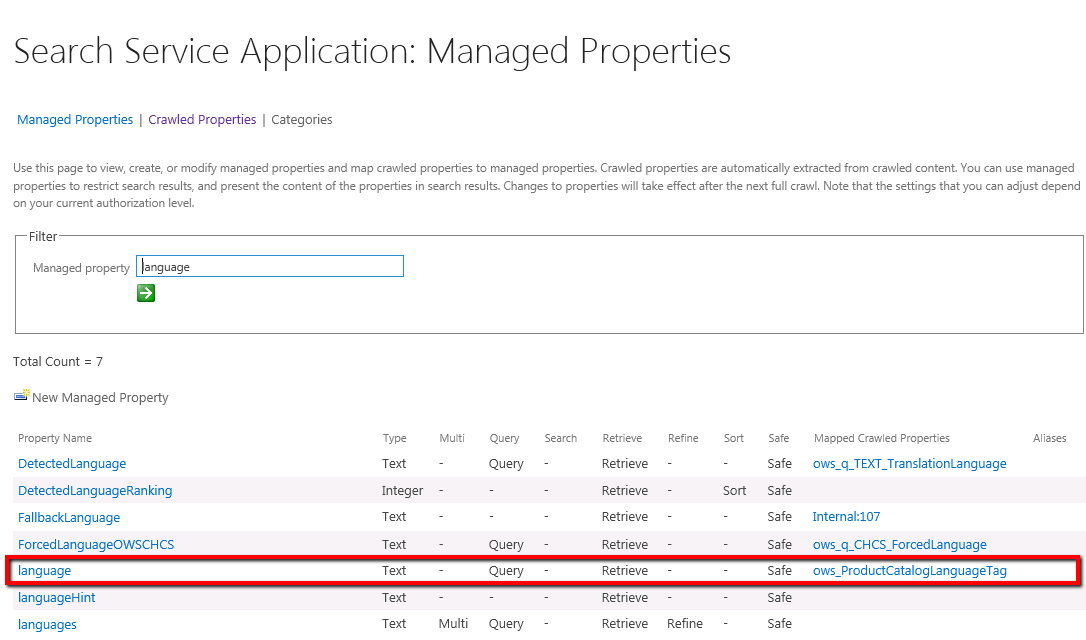
7. Now Map the crawled property ows_ForcedLanguage to the “language” managed property.
Go to the Search Schema, edit the language managed property.
Map the ows_ForcedLanguage to the language managed property.
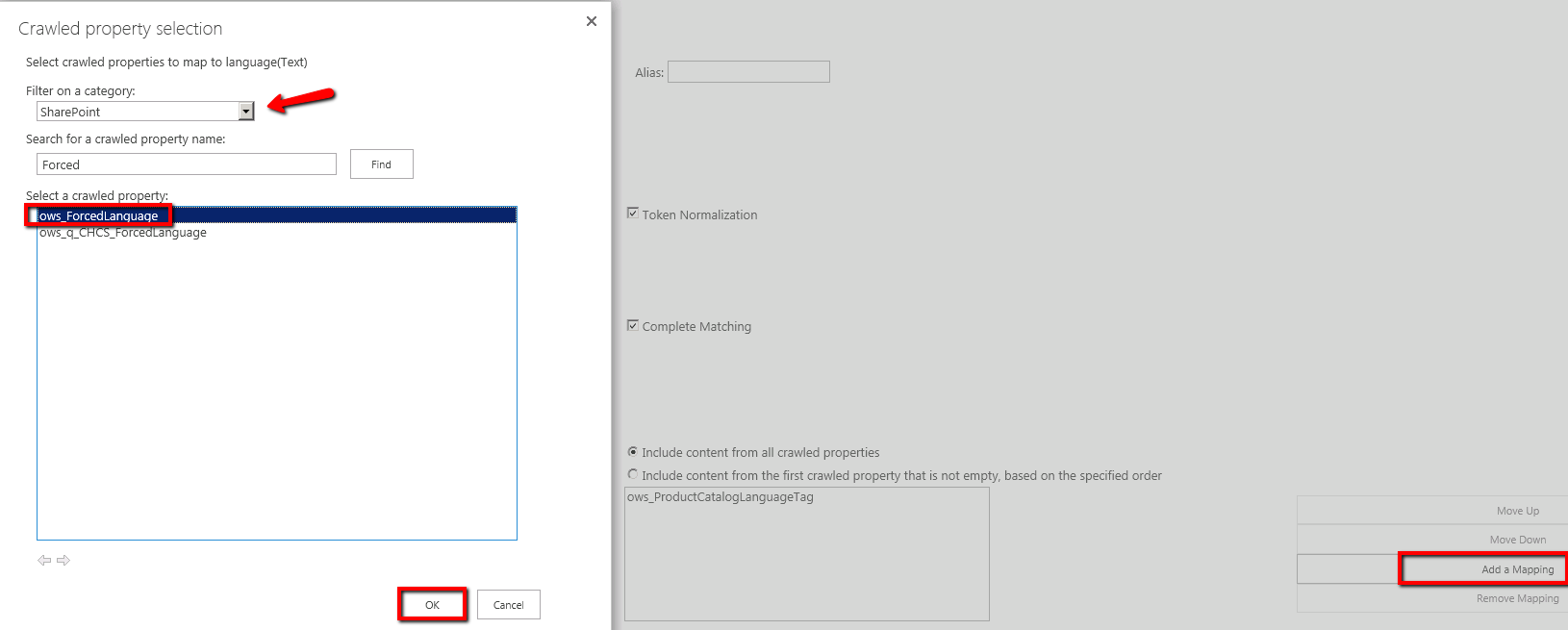
8. At that point, our mapping is ready but we need to populate the ForcedLanguage column for our existing items.
I use SP2013 PowerShell to do so.
$web = get-SPweb "https://nicolasuosl3/team"
$list = $web.GetList("https://nicolasuosl3/team/Shared Documents")
foreach ($item in $list.Items) { $item["ForcedLanguage"]="fr"; $item.Update() }
9. Once done, execute an incremental crawl again.
10. Using the same Query tool as previously, run the same query as in Step #6.
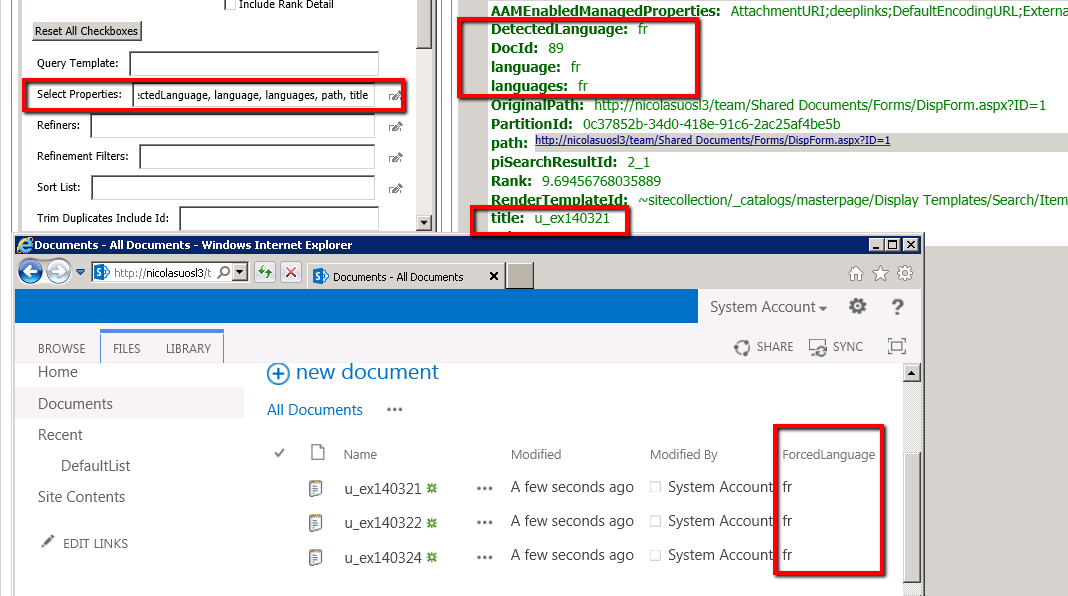
All documents have the language marked as "fr" like in our list.
11. For the sake of the demonstration, change the language of an item and execute an incremental crawl.
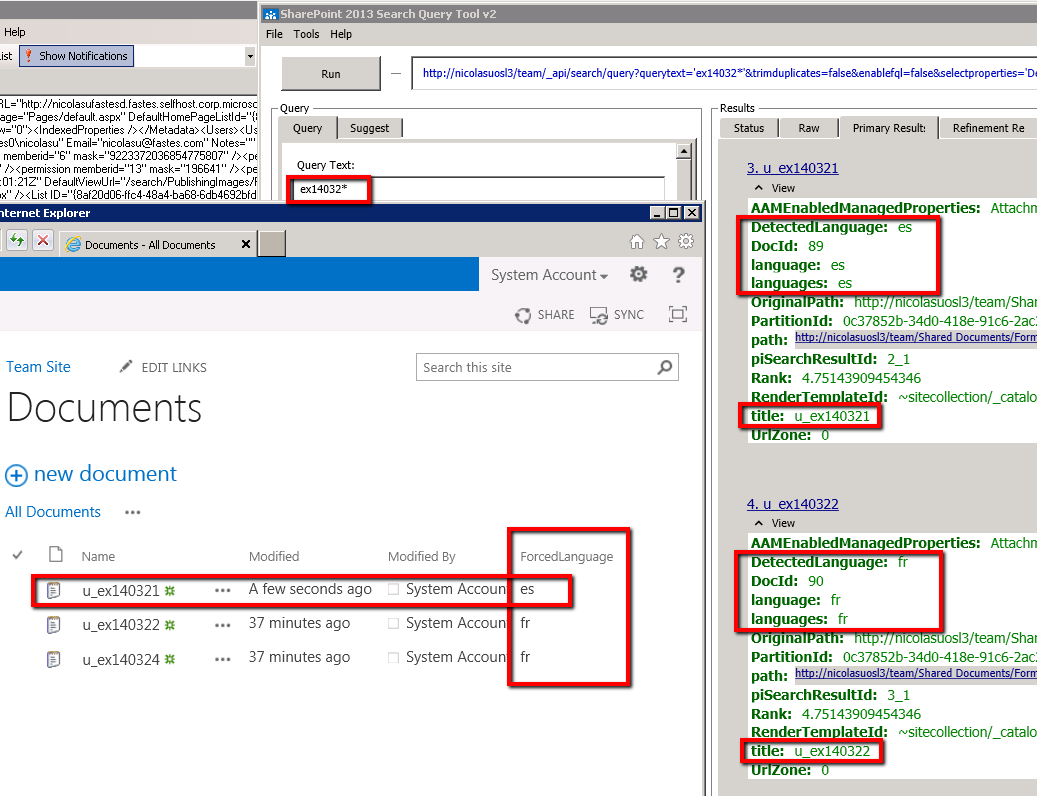
Done !
Conclusion
Forcing the language for each item of a list can allow you to have a consistent language across items. This consistency might be necessary for issuing Search requests in a multicultural organization.
HTH
Stay tuned !