
Database Collations During Microsoft Dynamics NAV Upgrades
This blog post describes how collations might change during an upgrade from a Dynamics NAV 2009 database to Dynamics NAV 2013, why they change, and how to determine the destination collation.
Today’s guest blogger is Erik Hougaard (b|l|t). Erik is a Dynamics NAV MVP who describes himself like this:
“Since he was a kid, Erik has been programming in Basic, Poly Pascal, and everything else that would run on a 4.77 MHz CPU. He got started with Dynamics NAV programming for IBM® with “IBM-Navigator 3.00″ in 1990. During the 90s, he programmed with Navision and many other systems, both in Denmark and USA. Since 2000, as R&D Manager at E Foqus Denmark, he has been the designer of several Dynamics NAV add-ons, and architect on the Glomaris OI .NET based framework. Erik programs robots, builds 3D printers, and plays the trombone in his spare time.”
Erik was the first person to reach out to us about this issue. Afterwards, we wanted to write a blog post about it, but before we had started writing, Erik asked if he could blog about this. So we decided to let Erik write on the team blog instead. Please visit his blog at https://www.hougaard.com/?s=nav for more interesting posts about Dynamics NAV.
Collation Changes During Upgrades
When you’re creating a database in Dynamics NAV, you’re met with the database wizard, and on the Collation tab, you select the collation for the database:
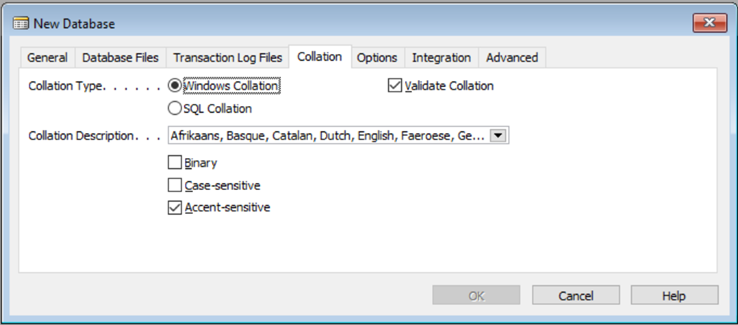
For many users, this is a strange dialog, and is often translated as just selecting a language. But collations are an integrated part of a database table or column, and something that is generally quite hard to change afterwards. Among other things, the collation defines the sorting order of text columns in the database and the base translation of characters going in and out of the database.
An example of how a collation works can be found in Danish, where AA is the same as the Danish letter Å. The Danish letter Å happens to be the last letter of the Danish alphabet, where A of course is the first. By selecting the correct Danish collation, entries that start with AA will be sorted last instead of first.
In Dynamics NAV 2009 and earlier, all text was stored using 8-bit character sets, meaning that a letter is stored in the database as a 0-255 (8-bit) value. Different code pages and character maps where used in different countries to allow for the unique letters of those countries to fit within the 8-bit limitation.
Fast forward to the introduction of modern Dynamics NAV. In Dynamics NAV 2013, the internal representation of TEXT and CODE variables changed from 8-bit to Unicode. Unicode is a universal character set that is aiming to include all known characters in the world. Currently, over 120.000 characters are defined in Unicode. SQL Server stores Unicode text as 16-bit (UTF-16) characters with some trickery to represent some characters as 32-bit.
So, when converting a Dynamics NAV 2009 database to Dynamics NAV 2013, text columns in the database must be converted to Unicode, and this is where this story starts.
We were converting a customer database from Dynamics NAV 2009 to Dynamics NAV 2016. All went well, everything looked fine, and all parties where happy, until I got a call from the database administrator (DBA) at the customer, who said: “Why have you changed the collation on our database to Greenlandic?”
Dynamics NAV has never been popular with DBAs, mainly because most of the classic SQL optimization tricks do not work well in a Dynamics NAV database, so this was just adding to the dislike.
I was sure that we hadn’t changed the collation, but when looking at the database, sure enough, there it was – the database was no longer Danish_Norwegian, but instead Danish_Greenlandic…very strange.
Collation before conversion

Collation after conversion

The “100” in the name indicates that the collation is a Windows collation. These were introduced in SQL Server 2008. Collations named SQL_* are compatible with SQL Server 2005 or older actually.
We started back tracing our steps, and soon discovered that the change in collation was happening during one of the upgrade steps when FINSQL was running. There were no missed dialogs or user interactions where a collation choice was ignored.
I reached out to Microsoft in Lyngby, and they started to investigate. Soon the answer came.
FINSQL has a built-in translation table with collations. Due to the fact, that the database must be upgraded to Unicode, a Unicode “friendly” collation should be used. From the table, we could lookup:
"Danish_Norwegian" = "Danish_Greenlandic_100",
And there it was: Danish_Norwegian becomes Danish_Greenlandic when being upgraded to Dynamics NAV 2013 (A complete list is found at the end of this blog post).
So how does this information help to answer the question from the DBA?
First, this was not a glitch, there is a purpose here. Second, now with a Unicode-based database, character sets are no longer a worry. Local letters will not suddenly turn into strange characters. Now, the collation is actually only controlling the sorting, but no longer the character translation. So, the DBA wanted Danish sorting, he still got Danish sorting.
Digging even deeper, because that’s what nerds like to do, it seems that, around 2005, the Norwegians stopped using the AA sorting for Å, so the collation settings in SQL Server for Denmark and Norway separated into two different collations.
Next time your database changes collation during an upgrade, you now know why.
Here is the complete list of changed collations:
| Before | After |
|---|---|
| “Latin1_General” | “Latin1_General_100” |
| “Albanian” | “Albanian_100” |
| “Arabic” | “Arabic_100” |
| “Cyrillic_General” | “Cyrillic_General_100” |
| “Chinese_Taiwan_Stroke” | “Chinese_Traditional_Stroke_Count_100” |
| “Chinese_PRC” | “Chinese_Simplified_Pinyin_100” |
| “Croatian” | “Croatian_100” |
| “Czech” | “Czech_100” |
| “Danish_Norwegian” | “Danish_Greenlandic_100” |
| “Estonian” | “Estonian_100” |
| “Finnish_Swedish” | “Finnish_Swedish_100” |
| “French” | “French_100” |
| “Greek” | “Greek_100” |
| “Hebrew” | “Hebrew_100” |
| “Hungarian” | “Hungarian_100” |
| “Icelandic” | “Icelandic_100” |
| “Japanese” | “Japanese_XJIS_100” |
| “Korean_Wansung” | “Korean_100” |
| “Latvian” | “Latvian_100” |
| “Lithuanian” | “Lithuanian_100” |
| “Macedonian” | “Macedonian_FYROM_100” |
| “Polish” | “Polish_100” |
| “Romanian” | “Romanian_100” |
| “Slovak” | “Slovak_100” |
| “Slovenian” | “Slovenian_100” |
| “Modern_Spanish” | “Modern_Spanish_100” |
| “Thai” | “Thai_100” |
| “Turkish” | “Turkish_100” |
| “Ukrainian” | “Ukrainian_100” |
| “Vietnamese” | “Vietnamese_100” |
| “SQL_Latin1_General_CP437_BIN” | “Latin1_General_100” |
| “SQL_Latin1_General_CP437_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP437_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_Pref_CP437_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP437_CI_AI” | “Latin1_General_100” |
| “SQL_Latin1_General_CP850_BIN” | “Latin1_General_100” |
| “SQL_Latin1_General_CP850_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP850_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_Pref_CP850_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP850_CI_AI” | “Latin1_General_100” |
| “SQL_1xCompat_CP850_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_Pref_CP1_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1_CI_AI” | “Latin1_General_100” |
| “SQL_AltDiction_CP850_CS_AS” | “Latin1_General_100” |
| “SQL_AltDiction_Pref_CP850_CI_AS” | “Latin1_General_100” |
| “SQL_AltDiction_CP850_CI_AI” | “Latin1_General_100” |
| “SQL_Scandinavian_Pref_CP850_CI_AS” | “Danish_Greenlandic_100” |
| “SQL_Scandinavian_CP850_CS_AS” | “Danish_Greenlandic_100” |
| “SQL_Scandinavian_CP850_CI_AS” | “Danish_Greenlandic_100” |
| “SQL_AltDiction_CP850_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1250_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1250_CI_AS” | “Latin1_General_100” |
| “SQL_Czech_CP1250_CS_AS” | “Czech_100” |
| “SQL_Czech_CP1250_CI_AS” | “Czech_100” |
| “SQL_Hungarian_CP1250_CS_AS” | “Hungarian_100” |
| “SQL_Hungarian_CP1250_CI_AS” | “Hungarian_100” |
| “SQL_Polish_CP1250_CS_AS” | “Polish_100” |
| “SQL_Polish_CP1250_CI_AS” | “Polish_100” |
| “SQL_Romanian_CP1250_CS_AS” | “Romanian_100” |
| “SQL_Romanian_CP1250_CI_AS” | “Romanian_100” |
| “SQL_Croatian_CP1250_CS_AS” | “Croatian_100” |
| “SQL_Croatian_CP1250_CI_AS” | “Croatian_100” |
| “SQL_Slovak_CP1250_CS_AS” | “Slovak_100” |
| “SQL_Slovak_CP1250_CI_AS” | “Slovak_100” |
| “SQL_Slovenian_CP1250_CS_AS” | “Slovenian_100” |
| “SQL_Slovenian_CP1250_CI_AS” | “Slovenian_100” |
| “SQL_Latin1_General_CP1251_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1251_CI_AS” | “Latin1_General_100” |
| “SQL_Ukrainian_CP1251_CS_AS” | “Ukrainian_100” |
| “SQL_Ukrainian_CP1251_CI_AS” | “Ukrainian_100” |
| “SQL_Latin1_General_CP1253_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1253_CI_AS” | “Latin1_General_100” |
| “SQL_MixDiction_CP1253_CS_AS” | “Latin1_General_100” |
| “SQL_AltDiction_CP1253_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1253_CI_AI” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1254_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1254_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1255_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1255_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1256_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1256_CI_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1257_CS_AS” | “Latin1_General_100” |
| “SQL_Latin1_General_CP1257_CI_AS” | “Latin1_General_100” |
| “SQL_Estonian_CP1257_CS_AS” | “Estonian_100” |
| “SQL_Estonian_CP1257_CI_AS” | “Estonian_100” |
| “SQL_Latvian_CP1257_CS_AS” | “Latvian_100” |
| “SQL_Latvian_CP1257_CI_AS” | “Latvian_100” |
| “SQL_Lithuanian_CP1257_CS_AS” | “Lithuanian_100” |
| “SQL_Lithuanian_CP1257_CI_AS” | “Lithuanian_100” |
| “SQL_Danish_Pref_CP1_CI_AS” | “Danish_Greenlandic_100” |
| “SQL_SwedishPhone_Pref_CP1_CI_AS” | “Finnish_Swedish_100” |
| “SQL_SwedishStd_Pref_CP1_CI_AS” | “Finnish_Swedish_100” |
| “SQL_Icelandic_Pref_CP1_CI_AS” | “Icelandic_100” |
That’s it. Thanks for writing the blog post, Erik!
Read more about SQL and Windows collations here:
https://docs.microsoft.com/en-us/sql/t-sql/statements/collations


