Detecting Race Hazards across tiles with the GPU debugger
This post assumes you have read the introduction and prerequisite: Visual Studio Race Detection for C++ AMP. I will also assume that you have enabled all the race detection hazard options of the Exceptions dialog, as described in that prerequisite blog post. In this post, I am going to share an example that demonstrates detection of race hazards that happen across tiles in C++ AMP code.
There are 3 race detection options for data hazards that happen across tiles:
- Detect read after write hazards across thread groups
- Detect write after read hazards across thread groups
- Detect write after write hazards across thread groups
Note that these specifically check for race conditions across thread tiles and would not detect race conditions inside a single thread tile. You would still have to use the other runtime checks we covered in the previous posts for such cases.
To demonstrate a case of a race hazard across thread tiles, I’m going to use the reduction sample code below. The code intends to calculate the sum of the elements of a given vector:
1. #include <amp.h>
2. #include <vector>
3.
4. using namespace Concurrency;
5.
6. const unsigned tile_size = 256;
7.
8. void VectorSum(std::vector<int>& data)
9. {
10. unsigned element_count = static_cast<unsigned>(data.size());
11. int sum = 0;
12.
13. array_view<int, 1> av_src(element_count, data);
14. array_view<int, 1> av_sum(1, &sum);
15.
16. parallel_for_each(av_src.extent.tile<tile_size>(), [=] (tiled_index<tile_size> tidx) restrict(amp)
17. {
18. tile_static int tile_data[tile_size];
19.
20. unsigned local_idx = tidx.local[0];
21. tile_data[local_idx] = av_src[tidx.global];
22. tidx.barrier.wait();
23.
24. // Reduce within a tile using multiple threads.
25. for (unsigned s = 1; s < tile_size; s *= 2)
26. {
27. if (local_idx % (2 * s) == 0)
28. {
29. tile_data[local_idx] += tile_data[local_idx + s];
30. }
31.
32. tidx.barrier.wait();
33. }
34.
35. // Update global sum
36. if (local_idx == 0)
37. {
38. av_sum[0] += tile_data[0];
39. }
40. });
41.
42. sum = av_sum[0];
43. }
44.
45. void main()
46. {
47. const int size = 1024;
48. std::vector<int> a;
49.
50. srand(0);
51. for (int i = 0; i < size; i++)
52. {
53. a.push_back(rand() % 100);
54. }
55.
56. VectorSum(a);
57. }
The code first computes partial sums within tiles between lines 18 - 33 and the partial sum is written to tile_data[0]. In the next stage, it adds the partial sum to the global av_sum variable.
If you run this code under the GPU debugger with all race detection options turned on, you should see a warning message for a race hazard across tiles at line 38:
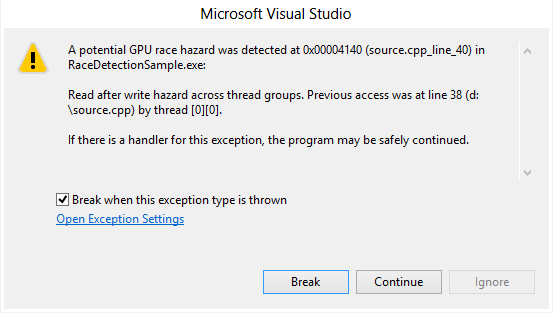
Since multiple threads from different tiles read and write to the global variable av_sum, their accesses must be synchronized. To fix this race condition we cannot use tile_barriers as they don’t work for inter-tile synchronization. Atomic instructions can be used for this purpose, so replacing the addition statement with its atomic counterpart
atomic_fetch_add(&(av_sum[0]), tile_data[0]);
and running it under the debugger we should not encounter any race hazards. Note that the algorithm used here is far from ideal and using atomics in this manner has performance problems as all threads in the kernel need to be synchronized. For much more efficient implementations of reduction algorithms, see our Reduction sample.