What is Vectorization?
Hi, I am Jim Hogg, a Program Manager in the Visual C++ compiler team. This short post explains “What is vectorization?”. It provides background for an upcoming sequence of posts on a new feature within the Visual Studio 2012 C++ compiler, called “auto-vectorization”.
Modern, 64-bit processors, such as the Intel 64 and AMD64, include a set of 16 registers that perform arithmetic operations on integers. [Think of a register as a cell, 64-bits wide, in ultra-fast memory – so fast, it can be accessed in a single machine cycle – a nanosecond, or less]. These registers are called RAX, RBX, RCX and so on. They are called scalar registers because they hold just one value at any time. We can write C++ code that adds two integer variables together. That compiler may transform the program to add those two values, using the RAX and RBX registers. If we have 1000 pairs of integers to add together, we need to execute 1000 such additions.
However, for several years, these chips have included an additional set of 16 registers, each 128 bits wide. Rather than hold a single, 128-bit wide value, they can hold a collection of smaller values; for example, 4 integers, each 32 bits wide. These registers are called XMM0, XMM1 and so on. They are called vector registers because they can hold several values at any one time. The chips also provide new instructions to perform arithmetic on these 4 packed integers. So we can add 4 pairs of integers with a single instruction, in the same time that it took to add just 1 pair of integers when using the scalar registers. [These new instructions are called SSE, which stands for “Streaming SIMD Extensions”]
Suppose we want to add array b into array a with the following code:
1: 1 const int N = 1000;
2: 2 float a[N], b[N];
3: 3 // Initialize a[i] = i; b[i] = 100 + i
4: 4 int main() {
5: 5 for (int n = 0; n < N; ++n) a[n] += b[n];
6: 6 }
The compiler will transform this code into a loop that uses registers to perform the required additions.
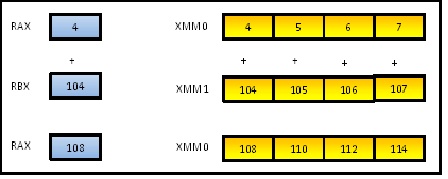
Here is a diagram that illustrates the situation. We see the calculation at the point where the loop variable n holds 4, and is performing the operation a[4] += b[4]. This is transformed into adding register RAX (holding 4) into RBX (holding 104) yielding 108, which is stored back into RAX. Because a and b each holds 1000 elements, we must carry out this addition operation 1000 times.
On the right, we see that same calculation, but now performed not just for b[4] , but for b[4] thru b[7] in parallel, in a single step. We add the vector register called XMM0 into the other vector register called XMM1, storing the result back into XMM0. So instead of yielding the single result of 108, we obtain 4 results: 108, 110, 112 and 114. We have done 4 iterations of the loop in a single operation.
Vectorization, then, is the process of using these vector registers, instead of scalar registers, in an attempt to make the program run faster. In a perfect world, our example loop would execute 4 times faster.
Vectorization can be performed in two ways:
- Manually, by you, the programmer. You need to write in assembly language, or call built-in functions (called “intrinsics”), from your C++ program. This gives you low-level control, but is difficult. You don’t want to be doing this.
- Automatically, on your behalf, by the compiler. This relies upon the compiler being smart enough to recognize loops that can be safely vectorized, and doing so.
This is enough background to understand the upcoming series on auto-vectorization, but here is another article if you want to dig deeper.