C++ AMP: It's got character, but no char!
In C++ AMP, the type char is part of the subset of the C++ language restricted from use on accelerators. Fortunately, it’s relatively easy to work around this restriction, and you may even get better performance to boot (though this is dependent on the code you’ve written and the GPU you are running on among other factors). For example, even with support for a character type, it is a much better idea to initialize an array using integer values rather than character values. Let’s take a look at this issue in more detail.
Scenario
Suppose you want to work with an STL vector of char type data containing size number of elements in C++ AMP. You cannot write the following because you cannot use unsigned char in the restricted scope:
array_view<unsigned char> d_data(size, data.data()); // THIS WON’T COMPILE!!
parallel_for_each(extent<1>(size), [=] (index<1> idx) restrict(amp)
{
// Example 1. Read each character in the vector
... = d_data[idx];
// Example 2. Increment each character in the vector
d_data[idx]++;
// Example 3. Add a value to each character in the vector
d_data[idx] += val;
// Example 4. Assign a value to each character in the vector
d_data[idx] = val;
});
d_data.synchronize();
However, if the vector is very large and the data can fit in 8 bits, then an array of unsigned char values is exactly what you may wish to use. Without support for char and unsigned char in C++ AMP, you could use integers and unsigned integers to accomplish your task, but care must be taken to ensure that writing all 32 bits does not trounce on other concurrent writes. Let’s see how we can work around this restriction.
Working to a solution
In the example above, the first step is to define an array view of unsigned integers via a cast. Since each unsigned integer can represent four characters, you’ll have to divide size by four (rounding up) and cast the vector to a vector of unsigned integers:
array_view<unsigned int> d_data((size+3)/4, reinterpret_cast<unsigned int*>(data.data()));
The rest of the work-around involves arithmetic, bit masks, and atomic operations. If you’re not interested in the details, you can skip to the next section to see a set of functions that should help you treat an array, array_view, or C-style array as if the element type was char.
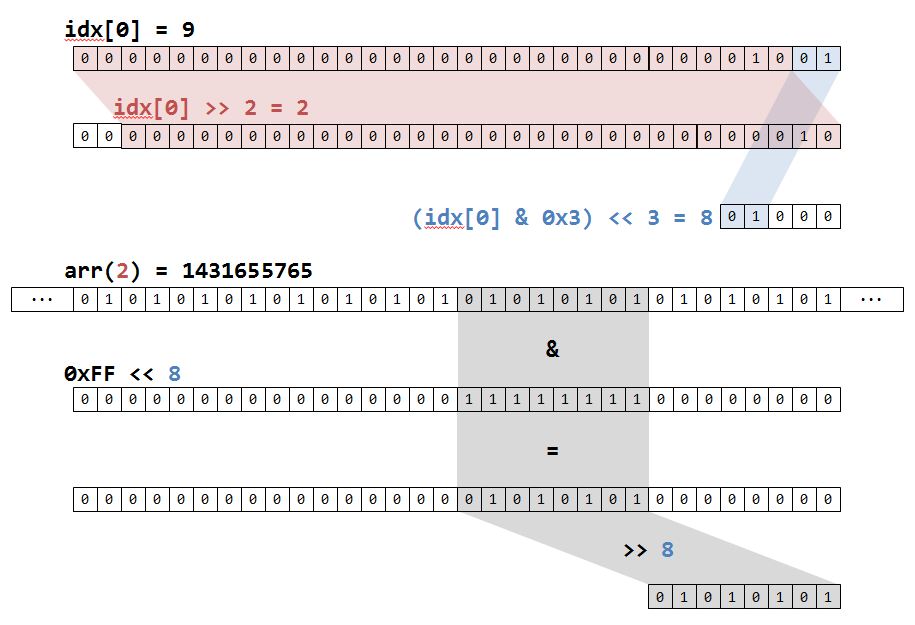
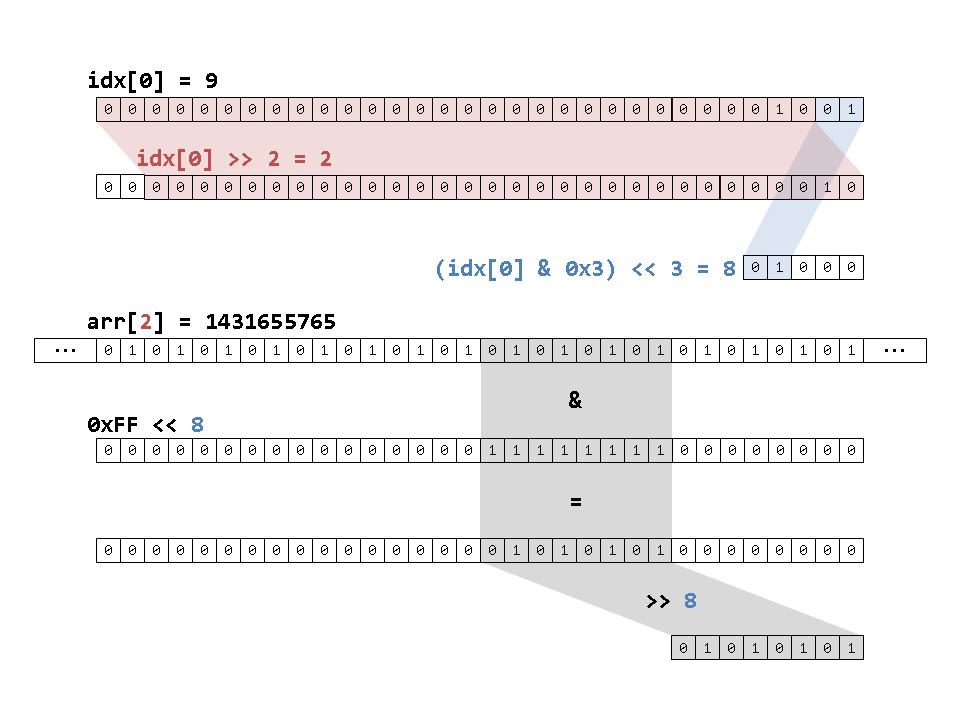
Reading the 8-bit character value (d_data[idx]) is possible with the following expression:
((arr(idx[0] >> 2) & (0xFF << ((idx[0] & 0x3) << 3)))) >> ((idx[0] & 0x3) << 3)
Note we have to use idx[0] rather than idx (though we could have indexed into the array directly with idx since division is overload over the index type). Let’s break this down with a picture:
{kind=link}
These bit manipulations allow us to find the 10th character by looking at the 2nd byte in the 3rd unsigned integer.
In addition to similar bit manipulations and arithmetic, writing to an 8-bit character element involves the use of atomic operations. Although it may be safe to write to the 8 bits concurrently, using integers and unsigned integers requires writing to 32 bits. There is thus the potential for a data race since the neighboring characters may be written at the same time. So even if you wouldn’t need an atomic operation to write to the 8 bits, you will most likely need one since you have to write to 32 bits! (The exception is if you know that you're not concurrently writing to any of the neighboring characters in the same 32 bits. In that case, you don't need the atomic operation.)
Incrementing an 8-bit character element (d_data[idx]++) is possible with the following line:
atomic_fetch_add(&arr(idx[0] >> 2), 1 << ((idx[0] & 0x3) << 3))
As with the expression to read an 8-bit character, this line involves many of the same bit operations. The key is to align the value 1 with the character that needs to be incremented.
Adding a value to an 8-bit character element (d_data[idx] += val) requires only a minor change to the above, and it can be computed with the following line:
atomic_fetch_add(&arr(idx[0] >> 2), val << ((idx[0] & 0x3) << 3))
Note the change from 1 to val.
Finally, writing a value to an 8-bit character element (d_data[idx] = val) can be done with two calls to atomic_fetch_xor. The trick is to change the 8 bits while leaving the others unchanged. We can thus zero out the 8 bits by xor’ing in the original value and then set the 8 bits to the desired value by xor’ing it. Here is the code for our example:
atomic_fetch_xor(&arr(idx[0] >> 2), arr(idx[0] >> 2) & (0xFF << ((idx[0] & 0x3) << 3)));
atomic_fetch_xor(&arr(idx[0] >> 2), (val & 0xFF) << ((idx[0] & 0x3) << 3));
Note that incrementing a character and adding a value to a character are atomic, but writing a character, as written, is not atomic. It uses atomic operations so that it can be completed concurrent to a write to a neighboring character, but it cannot be completed concurrent to a write to the same character since the whole operation is not atomic. It is possible to make the write atomic using an atomic compare-and-exchange operation. By reading the value, and then making sure that the write is completed before any other bits change, the value can be written atomically. For completeness, let’s take a look at this code as an aside:
bool done = false;
while (!done)
{
unsigned int orig = arr[idx / 4];
unsigned int repl = orig ^ (orig & (0xFF << ((idx[0] & 0x3) << 3)));
repl ^= (val & 0xFF) << ((idx[0] & 0x3) << 3);
done = atomic_compare_exchange(&arr[idx / 4], &orig, repl);
}
Solution
The following set of functions will let us rewrite the above code with minimal changes:
// Read character at index idx from array arr.
template <typename T>
unsigned int read_uchar(T& arr, int idx) restrict(amp)
{
return (arr[idx >> 2] & (0xFF << ((idx & 0x3) << 3))) >> ((idx & 0x3) << 3);
}
// Increment character at index idx in array arr.
template<typename T>
void increment_uchar(T& arr, int idx) restrict(amp)
{
atomic_fetch_add(&arr[idx >> 2], 1 << ((idx & 0x3) << 3));
}
// Add value val to character at index idx in array arr.
template<typename T>
void addto_uchar(T& arr, int idx, unsigned int val) restrict(amp)
{
atomic_fetch_add(&arr[idx >> 2], (val & 0xFF) << ((idx & 0x3) << 3));
}
// Write value val to character at index idx in array arr.
template<typename T>
void write_uchar(T& arr, int idx, unsigned int val) restrict(amp)
{
atomic_fetch_xor(&arr[idx >> 2], arr[idx >> 2] & (0xFF << ((idx & 0x3) << 3)));
atomic_fetch_xor(&arr[idx >> 2], (val & 0xFF) << ((idx & 0x3) << 3));
}
// Helper function to accept 1D indices of index<1> type instead of integers.
template <typename T>
unsigned int read_uchar(T& arr, index<1> idx) restrict(amp) { return read_uchar(arr, idx[0]); }
template<typename T>
void increment_uchar(T& arr, index<1> idx) restrict(amp) { increment_uchar(arr, idx[0]); }
template<typename T>
void addto_uchar(T& arr, index<1> idx, unsigned int val) restrict(amp) { addto_uchar(arr, idx[0], val); }
template<typename T>
void write_uchar(T& arr, index<1> idx, unsigned int val) restrict(amp) { write_uchar(arr, idx[0], val); }
With these functions, we can write the code we wanted to write at the beginning as follows:
array_view<unsigned int> d_data((size+3)/4, reinterpret_cast<unsigned int*>(data.data()));
parallel_for_each(extent<1>(size), [=] (index<1> idx) restrict(amp)
{
// Example 1. Read each character in the vector
... = read_uchar(d_data, idx);
// Example 2. Increment each character in the vector
increment_uchar(d_data, idx);
// Example 3. Add a value to each character in the vector
addto_uchar(d_data, idx, 2);
// Example 4. Assign a value to each character in the vector
write_uchar(d_data, idx, 3);
});
d_data.synchronize();
These techniques and abstractions make it possible and easy to write char-based code on the GPU using C++ AMP. It’s worth noting that the ideas above also apply to C-style arrays declared as tile_static variables.
Comments are welcome below and in our forum. Also if you have an interesting computation that benefits from using the char type, we'd be curious to see it. One common case where 8-bit data shows up is where you have an input device, such as a camera, that produces 8-bit data. Another case is this example of a 256-bin histogram. Do you have another computation that benefits from using 8-bit data on the GPU?