Resource Management in Concurrency Runtime – Part 2
In my previous blog post, I talked about key concepts of the Concurrency Runtime’s (ConcRT) resource manager, starting with a definition of a resource. I then explained why an application might be composed of a number of scheduler instances. Eventually I mentioned how the resource manager helps in resource allocation to the schedulers in order to improve performance and increase utilization of hardware. Specifically, the ‘initial allocation’ algorithm was mentioned, which defines the resource allocation done at the time of scheduler initialization.
Today I will be talking about ‘dynamic migration’ which is another key concept of the resource manager. I will provide details on how the resource manager deals with resource utilization dynamically as the workload of schedulers change.
Dynamic Migration
Dynamic migration can be defined as moving resources from one scheduler to another in order to improve CPU utilization.
As an example, consider the scenario on an 8 way machine where there are two schedulers (let them be S1 and S2) created with MinConcurrency = 1 and MaxConcurrency = 8 (Please refer to this for a description of the scheduler policy values that involves resource management). As mentioned as part of the initial allocation algorithm, after S1 and S2 are created the resources will be shared proportional to the MaxConcurrency and they will both have 4 resources:
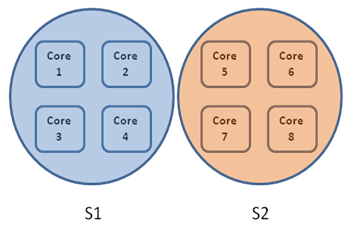
Until now this is all initial allocation. After this point, resource manager will start collecting information about the workload of the schedulers by polling periodically. At each poll the resource manager will capture the state of each scheduler instance with the IScheduler::Statistics() method. Let me note that the time a scheduler instance registers to the resource manager, it has to provide an implementation of IScheduler interface so that resource manager can call on that interface. The IScheduler::Statistics() method is expected to return three measurements calculated by the scheduler instance itself:
- Number of completed tasks since last statistics call
- Number of incoming tasks since last statistics call
- The total size of all work queues
The resource manager will keep a history of these measurements and derive a metric for scheduler workload for each scheduler. A statistically significant change in that metric (roughly speaking a positive or negative change as a factor of the standard deviation) will signify to the resource manager that the scheduler either needs one or more additional resources or can give away one or more. The bigger the change the more resources will be added or removed.
After polling each scheduler, the resource manager will have a list of schedulers (L1) that can give away a number of resources and a list of schedulers (L2) that needs a number of resources. Next thing to do then for all schedulers in L1, starting from the one with the minimum resource allocation priority, is to remove extra resources and re-allocate them to the schedulers in L2 starting with the highest priority. It is important to note that if L2 is empty, then schedulers in L1 will still keep their resources.
Let’s return back to the example above and assume that the resource manager has decided S1 can give away 2 resources and S2 can make use of 2 resources. The resource manager will inform S1 to give away 2 resources, oversubscribe the hardware threads with 2 more resources and inform S2 that it can now use the extra resources. It is expected that S1 will obey the protocol and release the resources as soon as possible. After this protocol completes, the allocation will be as follows:
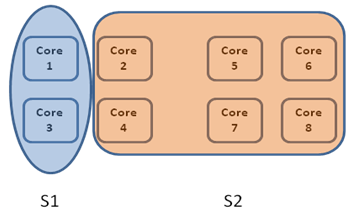
More Details on Dynamic Migration
We covered the general idea of dynamic migration. Let us walk through some what-if scenarios.
1. What happens if S1 has no work at all and S2 is still in need of resources, does S1 fall back to zero resources?
As a general rule of resource allocation, the resource manager will never allocate fewer resources to a scheduler than its MinConcurrency policy value. Therefore S1 will at least have 1 resource assigned. However since there is no work for S1, S1 will put that resource into inactive mode indicating to the resource manager that the resource is idle. Knowing this, the resource manager will share the underlying hardware thread by oversubscribing and providing another resource to S2.
2. What would happen if S1 shuts down and S2 is still in need of more?
All resources of S1 will become available. Resources will be allocated to S2 (not more than MaxConcurrency of S2) soon after.
3. On a machine with NUMA topology, is locality considered?
Locality information is used after the resource manager decides which scheduler is going to give away resources and which scheduler is going to take more (note that the schedulers are selected from the L1 and L2 list with respect to their allocation priority – therefore locality is less important compared to allocation priority). Let S1 (an element of L1) have R1 resources to give away and S2 (an element of L2) be in a need of R2 resources. If R1 is greater than R2 then the subset of resources to be allocated to S2 will be selected with respect to locality. Here is an example:
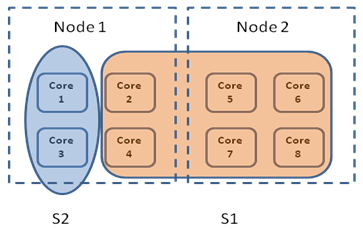
Assume this is the allocation layout before dynamic migration where Node1 and Node2 are NUMA nodes having 4 cores each. Let S1 be in need of 2 resources and S2 be able to give away 4. The resource manger will select two resources from S1 close to the ones in S2. Since resources of S2 (Core1 and Core3) are closer to Core2 and Core4 (as cores 1 to 4 are in the same node), the resource manager will migrate Core2 and Core4 to S2. After dynamic migration this would be the layout:
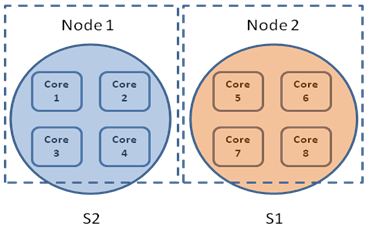
Next Steps and Feedback
Next I will demonstrate dynamic migration and focus on its performance characteristics. I would love to hear feedback regarding the blog content or areas of interest with respect to Concurrency Runtime to have a guided focus on blogging.