Building large models using Solver Foundation Services
In a previous post I wrote about the Term class and its use in building Solver Foundation models. Now I'd like to explore the use of Term in large models. It's also an opportunity to put into practice some of the things I talked about in my "writing high performance code" post.
Terms are the building blocks that are used to build constraints and goals. When you use operators like +, -, *, or Foreach, you are implicitly building a Term tree. When Solver Foundation solves a model, it interprets this term tree in order to determine the problem type (e.g. linear programming, constraint programming, etc), and which solver to call. If you have complicated term trees then this analysis will take more time.
Let's take a step back. You'd never write C# code like this:
string[] x = ...;
string s = "";
for (int i = 0; i < 1000; i++) {
s += x[i];
}
The reason you would never do this (well, I would never do it, I can't speak for you...) is that strings are immutable reference types and so concatenating two strings results in the creation of a third. Concatenating strings in a loop leads to O(n^2) behavior.
Fortunately the BCL provides the StringBuilder class:
string[] x = ...;
StringBuilder build = new StringBuilder();
for (int i = 0; i < 100; i++) {
build.Append(x[i]);
}
Time the two routines and you will see the difference. I bring this up because Terms are also immutable, so we see similar patterns when building Solver Foundation models. For example, goals and constraints are often sums of terms. Consider our well-worn Petrochem example, with the additional twist that there are only 5 facilities capable of refining crude into a given end product.
private static void PetrochemOriginal(int constraintCount, int decisionCount) {
SolverContext context = SolverContext.GetContext();
context.ClearModel();
Model model = context.CreateModel();
// Fill
double[] ranges = new double[decisionCount];
double[] demands = new double[constraintCount];
double[][] yield = new double[constraintCount][];
for (int i = 0; i < constraintCount; i++) {
yield[i] = new double[decisionCount];
}
double[] cost = new double[decisionCount];
Random r = new Random();
FillData(constraintCount, decisionCount, ranges, demands, yield, cost, r);
// Decisions
Decision[] refine = new Decision[decisionCount];
for (int i = 0; i < decisionCount; i++) {
refine[i] = new Decision(Domain.RealRange(0, ranges[i]), "refine" + i.ToString());
model.AddDecision(refine[i]);
}
// Goal
Term sumOfCosts = 0;
for (int i = 0; i < decisionCount; i++) {
sumOfCosts += cost[i] * refine[i];
}
model.AddGoal("goal", GoalKind.Minimize, sumOfCosts);
// Constraints
int nnz = 5;
for (int j = 0; j < constraintCount; j++) {
Term production = 0;
for (int i = 0; i < nnz; i++) {
production += yield[j][i] * refine[i];
}
model.AddConstraint("demand" + j.ToString(), production >= demands[j]);
}
// Save
using (var output = new System.IO.StreamWriter("sometest.mps")) {
context.SaveModel(FileFormat.MPS, output);
}
}
The term tree for the lefthand side of each constraint looks like the diagram on the left, but the one on the right is easier to digest.
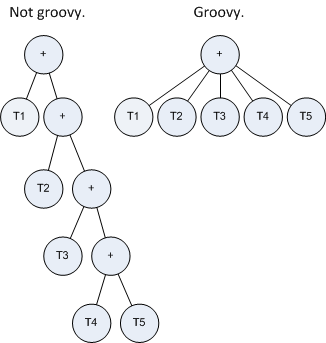
For convenience we can add a helper class SumTermBuilder. It aggregates subterms in a List, and when you call ToTerm() it gives you back a Sum term (the groovy term tree in my diagram).
/// <summary>It's a sum term builder.
/// </summary>
public class SumTermBuilder {
private Term[] _terms;
private int _count;
/// <summary>
/// </summary>
public SumTermBuilder(int capacity) {
if (capacity < 1)
capacity = 1;
_terms = new Term[capacity];
}
/// <summary>Clear.
/// </summary>
public void Clear() {
_terms = new Term[Math.Max(_count, 8)];
_count = 0;
}
/// <summary>
/// </summary>
public void Add(Term term) {
if (_terms.Length <= _count)
Array.Resize(ref _terms, _count * 2);
_terms[_count++] = term;
}
/// <summary>Create the corresponding term.
/// </summary>
public Term ToTerm() {
if (_terms.Length != _count)
Array.Resize(ref _terms, _count);
Debug.Assert(_terms.Length > 0);
return Model.Sum(_terms);
}
}
Now the constraint creation code becomes the following (the goal code is similar):
// Constraints
int nnz = 5;
SumTermBuilder production = new SumTermBuilder(constraintCount);
for (int j = 0; j < constraintCount; j++) {
for (int i = 0; i < nnz; i++) {
production.Add(yield[j][i] * refine[i]);
}
model.AddConstraint("demand" + j.ToString(), production.ToTerm() >= demands[j]);
production.Clear();
}
If we add stopwatches to the different phases of the model creation and compare the original code to the SumTermBuilder code, we see there is a significant difference. Here I have timed each phase for constraintCount=10000, decisionCount = 100.
|
Before |
After |
Change |
Fill |
0.025547 |
0.024754 |
3.1% |
Decision |
0.12387 |
0.000204 |
99.8% |
Goal |
0.030136 |
0.001858 |
93.8% |
Constraints |
0.238609 |
0.228829 |
4.1% |
Save |
1.167652 |
0.570951 |
51.1% |
Total |
1.585816 |
0.826597 |
47.9% |
We will add a class similar to SumTermBuilder in our upcoming 2.1 release to support efficient creation of this kinds of models.