スレッドとオブジェクトインスタンス
さてさて、この blog、基本的には玄人向けに濃い話題ばっかり書いていたのですが、実は最近、新人さんの方々にも割と読んでいただいていることが判明。ちょ、さすがにぜんぜん意味不明なエントリが多いのでは?? とか思ったりするのですが、そんな感じだとたまには割と入門者向けのエントリも書いてみたくなります。そんなわけで、今日はたまには基本に立ち返って、スレッドとオブジェクトインスタンスの話題を書いてみます。このネタを取り上げようと思ったのは、ある人からの質問メール。(ちょっと微修正しましたが^^)
「最近、3 階層のアプリケーションを、課題で作っていたんですよ。 そして、その UI 層の入力チェックメソッドを、 メンバメソッドにすべきか static メソッドにするかを考えていて、 ふと気になったことがあります。 static メソッドだと、メンバメソッドと違って、毎回インスタンスを 生成する必要がなく、便利ですが、物理的に一つしかないので、 二つのスレッドから微小時間ずれてアクセスされると、トラブルが 起こるんではないでしょうか?」 |
これは非常によい視点、だと思います。というのもアプリケーション開発者にとって重要なのは、どうすれば動くかではなく、どうするのが正しいのか、だからです。単純に動くかどうか、だけでいえばメンバメソッドだろうと static メソッドだろうとどっちで書いても動くように見えるはずですが、過負荷状態になったときにもしかしたらトラブルになるかも? だったらどう書くのが正しいのか? ……というように論理的に考えることは非常に重要です。というわけで、この質問に敬意を表して、全力で答えてみたいと思います^^。
この質問、もうちょっと具体的な例として書いてみると、例えば UI 層のチェックメソッドを以下のように static メソッドとして実装した場合に
public class DataCheckUtil
{
public static bool CheckEmailString(string email)
{
if (Regex.IsMatch(email, @"\w+([-+.']\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*") == true)
{
return true;
}
else
{
return false;
}
}
}
これが Web アプリケーションのようなマルチスレッドアプリケーションで、複数スレッドから同時に呼び出された場合にちゃんと問題なく動くかどうか? という質問です。
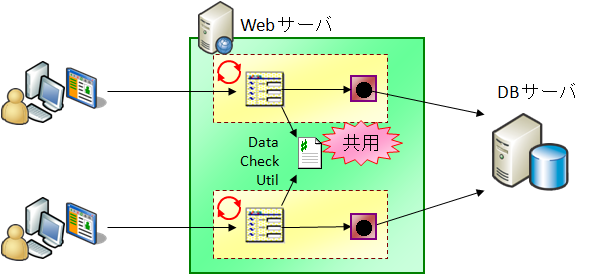
結論から先に書くと、このような処理は問題なく動作します。なぜ DataCheckUtil クラス内の static メソッドが同時に複数スレッドから呼び出されても問題なく動作するのかというと、それは、実際には上図のように複数スレッドから同一のオブジェクトが使われるわけではないからです。(つまり、簡単にいえば上の図は正確なイラストではないのですね^^)
このことを説明するために、.NET アプリケーションにおけるメモリ管理の話を少ししたいと思います。(ちなみに以下の話は Java などでもほぼ同じです。)
[スタックメモリとヒープメモリ]
.NET や Java では、データをメモリに格納する際、スタックメモリとヒープメモリと呼ばれる 2 種類のメモリをうまく使い分けます。
- スタックメモリ(ローカルデータ変数を保持するための空間。容量が比較的小さい。)
- ヒープメモリ(参照型のデータのインスタンスを保持するための空間。容量が非常に大きい。)
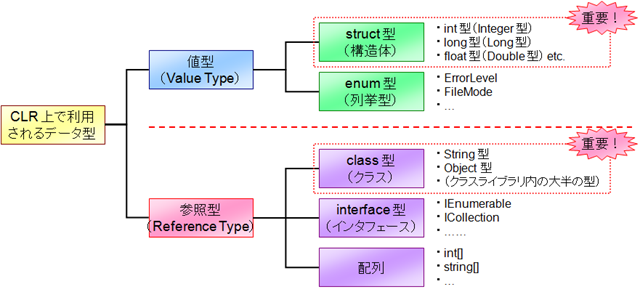
.NET では、データ変数の型は、値型と参照型に大別されます。値型のデータ変数(例えば int 型や double 型のデータ変数)を宣言した場合、その変数領域はスタックメモリ内に確保され、そこに実際のデータが格納されます。しかし、参照型のデータ変数(例えば string 型など)を宣言した場合には、実体はヒープメモリに格納され、変数の箱にはそのヒープメモリ内のアドレスのみが保存される、という形になります。
class Program
{
static void Main(string[] args)
{
double b = 135.25;
string a = "ABCDE";
}
}
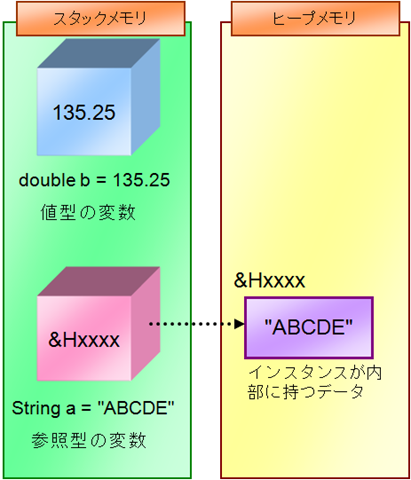
このような対策がなされているのは単純な理由で、
- スタックメモリは容量が少ない。
- double 型のような小さなデータ(数バイト程度)を保持することは問題がない。
- string 型のように巨大なデータ(文字列は場合によっては数 M バイトに膨れ上がることもある)を保持すると、あっという間にメモリ不足を起こしてしまう。
というわけです。
[クラスのインスタンスを作成する場合]
さて、.NET や Java では、クラスは参照型になります。このため、以下のようなコードを書いて実行すると、メモリイメージは下図のようになります。
class Program
{
static void Main(string[] args)
{
A objA = new A();
objA.MethodX();
objA.MethodY();
}
}
public class A
{
private int a = 10;
private string b = "Akama";
public void MethodX()
{
Console.WriteLine("Method X");
a++;
}
public void MethodY()
{
b = "nobuyuki";
}
}
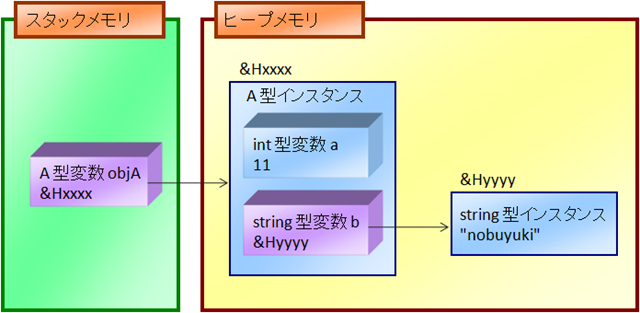
- クラス A のインスタンスが、ヒープメモリ空間内に作成される。
- ヒープメモリ空間内のオブジェクトインスタンス内には、オブジェクトの内部データである int 型変数 a と string 型変数 b のデータ格納領域ができる。
- int 型変数 a は値型なので、実体がそのまま入る。string 型変数 b は参照型なので、アドレス値が格納される。
さて、ここまでがいわゆる入門者向けの説明なのですが、実はここで初心者がハマるよくある誤解が、インスタンスのところにコードがコピーされて実行される、というものです。
一般的に、クラスとインスタンスの関係は、鯛焼きの型と鯛焼きの関係だと言われます。(分かりにくいような気もしますが^^)
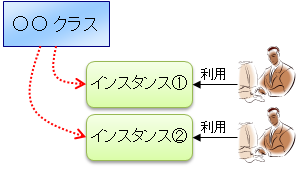
ここで注意しなければならないのは、クラスはアプリケーション実行コードを含んでいるが、インスタンスは実行コードを含んではいない、という点です。つまり、下図のような理解は間違いです。
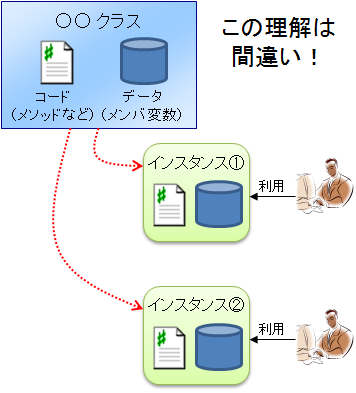
実は、ヒープメモリに作成されるインスタンスには、実行コードが含まれておらず、データ変数のみが格納されています。アプリケーション実行コードは一か所にのみ存在し、インスタンスごとには保持されていません。
[スタックメモリとコールスタック]
ではなぜ実行コードがコピーされなくても正しく処理できるのか? これを説明するためには、もう一つ、スタックメモリとコールスタックについて解説する必要があります。
そもそもなぜスタックメモリは 「スタックメモリ」 と呼ばれているのか? それは、このスタックメモリというのがコールスタックを管理しているものだからです。コールスタックとインストラクションコードを理解するために、まず以下のようなサンプルコードを取り上げてみましょう。
1: class Program
2: {
3: static void Main(string[] args)
4: {
5: int a = 0;
6: int b = 0;
7: Console.WriteLine("Nobuyuki");
8: Console.WriteLine("Akama");
9: Console.WriteLine("Microsoft");
10: Console.WriteLine("Consulting");
11: Console.WriteLine("Services");
12: }
13: }
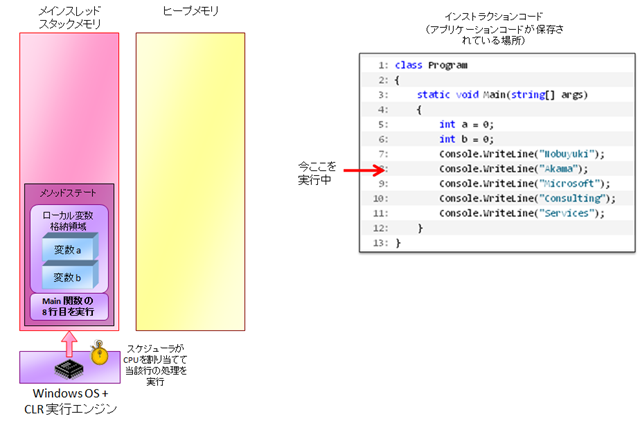
このようなアプリケーションは、次のように実行されます。
- アプリケーションコードは、メモリ内の特定領域(ヒープでもスタックでもないところ)に保持されている。
- Main() 関数が動作すると、メインスレッドに対してスタックメモリ領域が作成され、このスタックメモリ内に、現在実行している行番号と、ローカル変数が保持される。
- このスレッドに CPU が割り当てられると、CPU が当該行のコードを実行し、次の行へとどんどん進んでいく。(ちなみに現在の実行行番号のことを、インストラクションポインタと呼びます。)
- 結果として、インストラクションポインタ(図中の → マーク)が順次下方向に動いていき、そこに書かれている処理命令が、スタックメモリ内のデータに対して実施される、という形になります。
では今度は、あるメソッドから別のメソッドが呼び出される例として、次のようなものを考えてみます。
class Program
{
static void Main(string[] args)
{
int a = 0;
MethodX();
}
static void MethodX()
{
int b = 0;
MethodY();
}
static void MethodY()
{
int c = 0;
}
}
この場合、アプリケーションは Main → MethodX() → MethodY() とネストして呼び出されていくことになるのですが、この場合は下図のような動きをします。
- まず、Main() 関数が動いていくと、実行行が 3, 4, 5, 6 行目と進んでいく。 これにより、インストラクションコードの処理が、スタックメモリ内のデータに対して実施される。
- 6 行目まで達すると、MethodX() が呼び出される。すると、スタックメモリ内にもう一つ、メソッドステートが重ねられ、この中身が 9, 10, 11, 12 行目と進んでいく。
- 12 行目まで達すると、MethodY() が呼び出される。すると...(以下略)
- そしてメソッドが終了すると、メソッドステートが消されて元に戻っていく。(このようにスタックメモリにはメソッドの処理状態が積み重ねられていくために、「スタックメモリ」と呼ばれている)
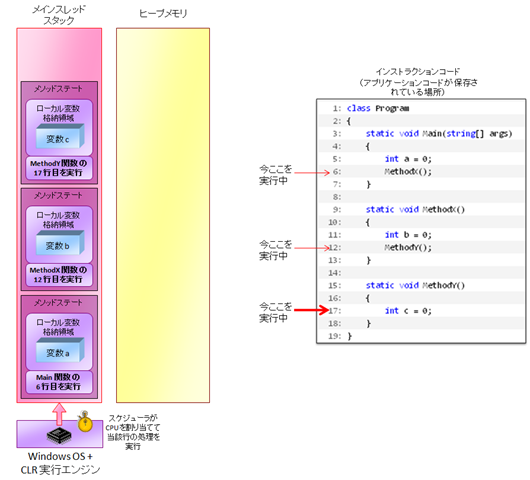
つまり、ここまでの話からわかるように、
- 実行コードとデータ変数領域は、物理的にはわかれている。
- 実行コードに書かれている処理が、スタックメモリやヒープメモリ内におかれたデータに対して実施される。
という形になっています。(=コードが物理的に各スレッドやインスタンスにコピーされて動いているわけではない)
[オブジェクトインスタンスがかかわる場合のコールスタック]
さて、上図はオブジェクトインスタンスがかかわらない場合のコールスタックですが、ではオブジェクトインスタンスがかかわるとどのようになるのか? 具体例を示すと、次のようになります。(ちょっと分かりにくいと思いますので、しっかり図とコードを見てください。自分で一度、イラストを描いてみるのもよいと思います。)
1: public class A
2: {
3: private int a;
4: private string b;
5:
6: public void MethodX()
7: {
8: Console.Write...
9: a++;
10: }
11:
12: public void MethodY()
13: {
14: b = "nobuyuki";
15: }
16: }
17:
18: public class Program
19: {
20: static void Main()
21: {
22: A a = new A();
23: a.MethodX();
24: }
25: }
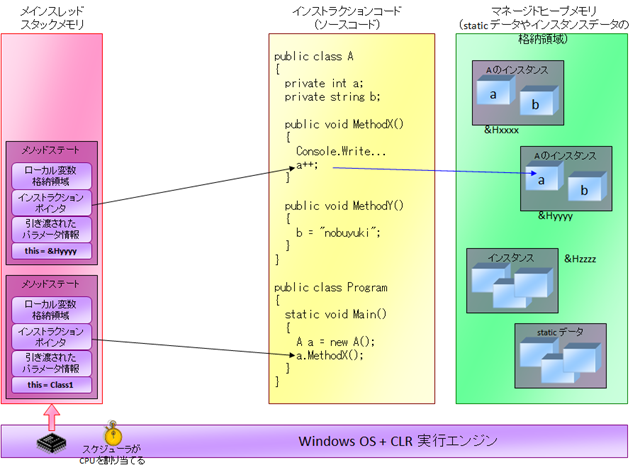
キーポイントを示すと、以下のようになります。
- メソッドステートの中に、「今、どのインスタンスを処理しているのか?」のデータが含まれるようになる。一方、インストラクションポインタ(=現在の実行行番号)は、あくまで行番号を示している。
- 実際の処理は、インストラクションポインタと、処理対象インスタンスデータの二つによって行われる。例えば上図の場合、"a++"の処理は、現在の処理対象インスタンスである &Hyyyy のインスタンスに対して行われることになる。
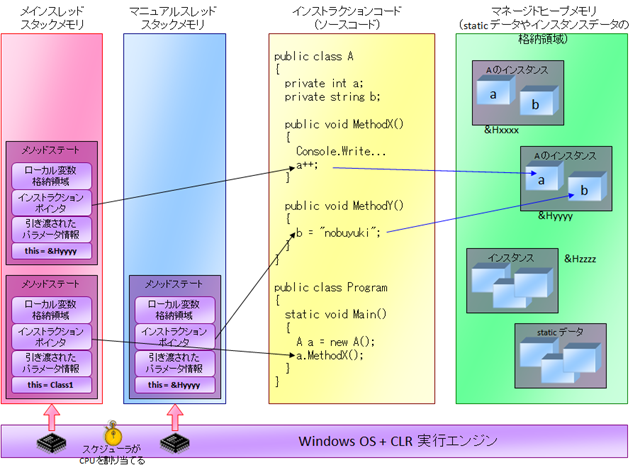
[マルチスレッドアプリにおけるスタックメモリとヒープメモリの図]
さて、以上はシングルスレッドアプリケーションの場合について解説しましたが、マルチスレッドアプリケーションの場合には、
- スタックメモリは、スレッドごとに作成される。
- ヒープメモリは、複数のスレッド間で共有される。
- インストラクションコードは、複数のスレッド間で共有される。
という動きをします。よって、例えばメインスレッド以外にマニュアルスレッドが動作しているようなマルチスレッドアプリのメモリ構造は、下図のようなイメージなります。
ではここで、Web アプリケーションを例にとって考えてみましょう。たとえば、以下のようなコードを持つ A.aspx ファイルがマルチスレッドで実行された場合を考えてみます。この場合にどんなメモリ配置になるのかを描いてみてください。
1: public partial class _Default : System.Web.UI.Page
2: {
3: private int a = 0;
4: static protected int c = 0;
5:
6: protected void Page_Load(object sender, EventArgs e)
7: {
8: int b = 0;
9: a++;
10: b++;
11: c++;
12: MethodX(a, b);
13: }
14:
15: protected void MethodX(int d, int e)
16: {
17: d++;
18: e++;
19: }
20: }
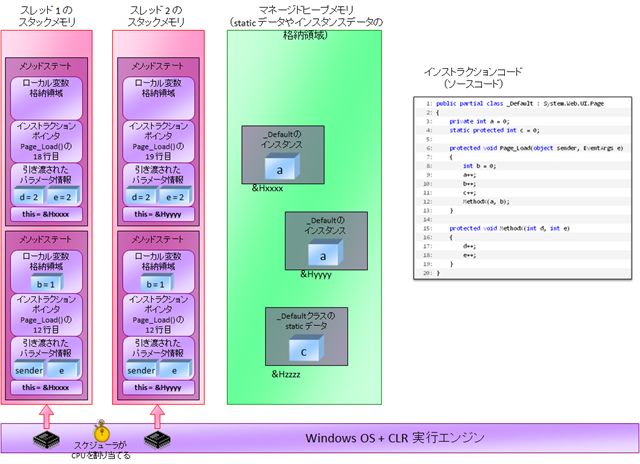
この例からわかるように、
- メソッド内部で宣言されるローカル変数やメソッド引数については、スレッドごとにデータ変数領域が作られる。
- しかし、static 宣言されたデータ変数については、全体で一つしかない。
という形になっています。このため、実は上記のコードの場合、データ変数 c を操作する 11 行目の処理を 2 つ以上のスレッドが同時に処理した場合にトラブルが起こる(ロストアップデートなど)可能性があります。上記のコードの場合には、11 行目の c++ というコードを複数スレッドが同時に実行しないようにするために、以下のようなスレッド間同期制御コードを書かなければなりません。
protected void Page_Load(object sender, EventArgs e)
{
int b = 0;
a++;
b++;
lock (typeof(_Default))
{
c++;
}
MethodX(a, b);
}
※ lock 構文についてはここでは説明しませんので、興味がある方は書籍などで調べてみてください。
さて、ここまでの話を統合して、最初の質問に戻りましょう。例えば UI 層のチェックメソッドを以下のように static メソッドとして実装した場合を考えてみます。
public class DataCheckUtil
{
public static bool CheckEmailString(string email)
{
if (Regex.IsMatch(email, @"\w+([-+.']\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*") == true)
{
return true;
}
else
{
return false;
}
}
}
これが Web アプリケーションのようなマルチスレッドアプリケーションで複数スレッドから同時に呼び出されたとして問題があるのか? ……もう答えは明らかですね。マルチスレッドアプリケーションで複数スレッドからこのメソッドが呼び出されても、全く問題がありません。
[スレッドセーフなメソッド]
以上のことから、次のようなことが言えます。
- static データ変数などを(lock 処理などをせずに)無造作に操作しているメンバメソッドは、マルチスレッド動作させた場合にトラブルが出る危険性がある。
- ローカル変数しか操作していないようなメソッドは、マルチスレッド動作せても問題がない。(※ ローカル変数が参照型で、そのオブジェクトインスタンスを別スレッドからも操作しせてたらダメですが;)
一般に、マルチスレッドアプリケーションにおいて複数スレッドから同時に呼び出されたとしても問題が発生しないメソッドのことを、スレッドセーフなメソッドと呼びます。Java や .NET の基本的なクラスライブラリの多くはスレッドセーフに設計されていますが、すべてがスレッドセーフとは限りません。このため、安易にマルチスレッド動作アプリケーション(例えば Web アプリケーションや Web サービス)からクラスライブラリを使うと、トラブルが起こる危険性があるわけです。
とはいえ、.NET の中でも我々が普段使うようなメソッドについてはほとんどがスレッドセーフに作られています。例えば Int32 型のドキュメントを見てみると、すべてのメンバがスレッドセーフに作られている、と明記されています。このため、例えば Int32.Parse() メソッドなどを無造作に呼び出しても、トラブルは発生しません。
[最後にクイズ]
では、最後にクイズを出しておきたいと思います。以下に示す クラス X の 3 つのメソッドは、それぞれスレッドセーフでしょうか?
public class X
{
private int a;
static private int b;
public void MethodA(int c)
{
string d = "Nobuyuki";
c++;
d = "Akama";
Console.WriteLine(c);
Console.WriteLine(d);
}
public void MethodB(string x)
{
x = "Microsoft Consulting Services";
b++;
Console.WriteLine(b);
}
public bool MethodC(string y)
{
a--;
return (y.Length > 5);
}
}
正解は……ないしょです。(え?w) みなさんで考えてみてくださいね。
[まとめ]
というわけで、今回のエントリのまとめです。
- アプリケーションコードは、インスタンスごとやスレッドごとにコピーされて実行されるわけではない。
- スタックメモリは、スレッドごとに作成され、コールスタックが管理される。
- パラメータ引数やメソッド内部ローカル変数は、スタックメモリ内にデータ変数領域が作られる。
- ヒープメモリは、スレッド間で共有され、インスタンス内部データや static データなどが管理される。
- マルチスレッドアプリケーションで、複数スレッドから呼び出しても異常動作を起こさないメソッドを、スレッドセーフなメソッドと呼ぶ。
- .NET Framework のクラスライブラリは、すべてがスレッドセーフというわけではない。
スレッドとオブジェクトインスタンスの関係は、私もオブジェクト指向を学習し始めた当初に相当悩んだ部分で、このエントリでは偉そうに書いてますが;、ぶっちゃけホントにわからなかったです……。今回書いたような話は非常に基礎的なことでありながらも、「なんとなく」で済ませてしまっている方も多いのではないかと思いますが、正確な理解には欠かせない部分なので、ぜひ一度は自分で絵などを描いてみて、理解していただければと思います。
# ってむちゃくちゃ長いエントリになってしまった……
# 結構ちゃんと説明しようと思うと大変な話なんですよねぇ、この話。