Entity Framework Core and Cross-Database Support
Editor's note: The following post was written by Visual Studio and Development Technologies MVP Shay Rojansky as part of our Technical Tuesday series with support from his technical editors, Data Platform MVP Erik Ejlskov Jensen, and Diego Vega, a member of the Entity Framework Team.
Just last week, Microsoft released Entity Framework (EF) Core 1.1.
EF Core is a total rewrite of EF 6.x, Microsoft’s mature and stable O/RM product. And while EF 6.x continues to be maintained, is more fully-featured, and is in fact the recommended choice for many scenarios, EF Core will be the innovative product to keep your eye on in the future. Aside from being more lightweight and modular, EF Core is also very portable - not only across platforms (like Linux/Mac with .NET Core), but it’s also portable across databases.
Supporting different databases is nothing new; EF 6.x providers exist for MySQL, PostgreSQL, Oracle and many other systems. However EF 6.x is somewhat constrained in what it allows database providers to do, preventing users from accessing important database features.
This article will explore how EF Core's modular design and focus on cross-database support exposes some exciting database-specific features - specifically in Npgsql, an open-source EF Core provider for the PostgreSQL database. Very little prior knowledge of EF is assumed.
Type mapping
The fundamental purpose of any O/RM, is to transparently map objects and their properties to tables and columns. This includes mapping property types (CLR types in .NET) to database data types (a CLR string needs to be mapped to an `nvarchar` column in SQL Server, but in PostgreSQL the corresponding data type is called `text`). While EF 6.x allows database providers to define these mappings, the set of supported CLR types (or more precisely, entity model primitive types) is a closed list. So if a database has a data type not supported in the list, it cannot be supported by EF 6.x.
PostgreSQL happens to have quite a rich type system. It comes with built-in support for network address types (inet, macaddr), time interval, (equivalent to CLR TimeSpan), as well as some other non-standard types. You can create columns of these types just like you would an int column, and get all the advantages of a natively-supported type - such as validation, efficient storage and network transfer.
It's also worth mentioning that PostgreSQL supports extensions, which can add data types, functions, server-side languages and other features to your database; the most notable example of an extension is PostGIS, which provides spatial (GIS) support. Other extensions provide rich data types for different domains. This effectively makes PostgreSQL data types a totally open list.
The ability to have IP address columns may not seem like much, so let's look at something more compelling.
It is sometimes necessary for an entity to have an array of values. It could be a set of tags on your blog post, or some arbitrary set of numbers that mean something to your application. The traditional relational approach for this is to create a separate table and have a one-to-many relationship. While this works, it can be extremely cumbersome and heavy performance wise. All you really wanted was a simple array in your row. This sometimes leads people to do ugly hacks, such as storing an array in a single string with a delimiter. This situation isn't ideal.
PostgreSQL has first-class support for array data types. You can define arrays of any supported data type, and of any dimension. There's also a rich set of operators and functions to query and manipulate arrays, and you can even index array values to a large extent. This is part of PostgreSQL’s general support for some NoSQL patterns - more precisely, non-relational ones. Unfortunately, EF 6.x's constrained type model prevents you from accessing these awesome features.
EF Core's type mapping model is much more open and extensible. Providers have full control over which CLR types they support, and how they map them to database types, and vice versa. The 1.1.0 version of Npgsql EF Core provider allows you to define entity classes such as the following: 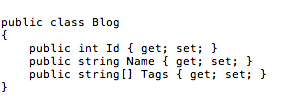
This will map to the following PostgreSQL table: 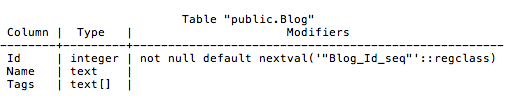
The same extensibility is also present in the scaffolding process, where EF Core reverse-engineers a code model from an existing database (AKA database-first), allowing Npgsql to scaffold C# array properties from PostgreSQL array properties.
Mapping Operations
Being able to map arbitrary types is great, but it's not all EF can do. One of the major advantages of EF is the ability to translate standard LINQ queries to SQL, allowing you to write the following sort of code: 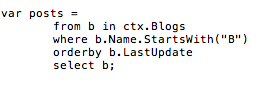
This will produce the SQL you expect - EF will recognize `.StartsWith()` and translate it using the SQL LIKE operator, running the filter in the database rather than client-side.
Continuing our example from above, what if we wanted to get all blogs which have at least one tag? Like I mentioned, PostgreSQL provides array operators and functions - and among them is `array_length()`, which can do just that. Unfortunately, getting an array length is a special C# expression type that can't be mapped to SQL in the current version of EF Core - but a fix for this has already been merged and this scenario will be supported in 1.2.
But rather than discussing soon-to-be-unsupported features, let's talk about something you can do today. You've already seen some basic string filters can be translated to SQL's LIKE operator. But PostgreSQL also happens to support full-brown regular expressions in SQL statements, allowing you to write the following: 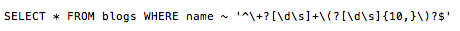
This will select all blogs whose names contains a phone number. Regular expressions are much more powerful than SQL LIKE, so arbitrary string tests can be executed in the database. This is very important for performance - without database support for regular expressions, you're forced to pull in all blogs from your database and perform the string testing in your application, which could be very heavy if you have a lot of blogs. On the other hand, make sure you're not overloading your database by executing complicated regular expressions on too many values.
EF Core's SQL translation has allowed the Npgsql provider to cleanly translate `Regex.IsMatch`. This means that you can write .NET's regular expression API just as you would normally, and have the Npgsql EF Core provider translate that for you. The above SQL, for example, can be generated with the following LINQ query: 
While the ability to map arbitrary CLR methods opens up lots of exciting possibilities, a warning is in order. EF Core includes a cool new feature, called client evaluation of query parts. While if some part of your LINQ query can't be translated to SQL in EF 6.x, a NotSupportedException is thrown. But EF Core on the other hand, will simply perform the problematic bit client-side, and pull in all the necessary data from the server. While this is very useful in many scenarios, it can lead to big performance issues if you’re not careful.
Imagine you have an existing EF Core application sending regular expressions to PostgreSQL, and you're trying to port it to SQL Server, or some other database. The LINQ query above will continue working flawlessly, except it will start evaluating client-side, pulling in all blog details into your application (EF Core will at least emit warnings about this). As always, you should carefully take a look at the SQL being generated by your application (with the help of logging). You can also choose to disable client evaluation altogether.
To be fair, translating operations to SQL functions can also be done in EF 6.x. And the Npgsql EF 6.x provider supports this. But EF 6.x doesn't allow you to translate any plain, old CLR methods, like `Regex.IsMatch()`; `String.StartsWith()`, because they’re included in a special list that can't be extended by providers. Instead, you must use specially-annotated function proxies - like `NpgsqlTextFunctions.MatchRegex()`- which are much less elegant. EF Core can translate much larger expression classes than just function calls.
As a side note, another "NoSQL-ish" type that PostgreSQL has supported for a long while is JSON. Like with arrays, JSON support includes a rich set of functions and operators that allow you to query against JSON documents. With EF Core's new translation capabilities, it would be possible to set up translations from a CLR JSON API (e.g. Newtonsoft.Json) to these PostgreSQL operators, and execute complex JSON filtering and extraction in the database without leaving C# and LINQ. You can track (and vote) for this capability here.
Migrations
As a final example of cross-database extensibility, let's take a look at migrations.
EF doesn't just map entities to tables. It can also create those tables and optionally modify their schemas as your code model evolves - like if you add columns, for example. When creating tables, columns and indices, there's a wealth of database-specific features and parameters that users can tweak and tune. And once again, EF 6.x and most other O/RMs constrain their users to whatever is universally supported.
EF Core solves this problem by allowing arbitrary "annotations" to be specified in your code model. For example, SQL Server 2014 supports the concept of memory-optimized tables, which are kept entirely in memory, in addition to being persisted to disk for durability. EF Core 1.1 allows you to setup your entity as follows in your model configuration: 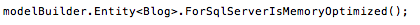
This will add an annotation that the SQL Server provider will pick up, and will cause your Blog table to be created accordingly. Note that on Npgsql, the annotation is simply ignored and has no effect.
Let's look at another example. When creating an index, PostgreSQL allows you to specify its type, or "method". By default, PostgreSQL creates b-tree indices which are suitable for most purposes, but in certain cases you may wish to tweak this choice. For example, GIN indices allow you to index elements inside arrays or JSON objects, enabling you to quickly filter columns that contain value. Similarly, GIST indices allow you to index geometric data types, indexing things like whether a circle is contained within a box, etc. Choosing the right or wrong index method can have a significant impact on the performance of your application. Here's the documentation if you're interested in learning more.
Npgsql's EF Core provider allows you to do the following: 
This will cause your indices to be created with the following DDL: 
Granted, choosing an index method is an advanced feature that most developers won't need. But EF Core makes it possible for those who will.
Conclusion
Using an O/RM is always a tradeoff: you gain productivity, but have to relinquish some control over what you can do. To a certain extent, this is analogous to using a high-level language like C# rather than one like C. And like with programming languages, performance-sensitive applications sometimes forego O/RMs entirely, preferring to hand-code optimized SQL. In addition to increasing productivity, O/RMs aim to abstract away the specific databases they support and provide a single, common API. While this makes applications more portable, it typically ends up restricting their users to the least common denominator supported by standard databases. EF Core's extensible architecture and strong cross-database alleviates this issue at least to some extent. All in all, it's possible to go much further than before in exposing database-specific types, query features and other database aspects.
 Shay Rojansky was originally a committed Linux and open source enthusiast with years of experience in Java, Python, C/C++, among others. But he dipped his toes in the C#/.NET world and hasn't looked back since. He's worked in .NET in a variety of domains - from high-performance algorithmic trading, web programming, to data access and ORMs - and is lead dev on .NET support for the PostgreSQL database (Npgsql).
Shay Rojansky was originally a committed Linux and open source enthusiast with years of experience in Java, Python, C/C++, among others. But he dipped his toes in the C#/.NET world and hasn't looked back since. He's worked in .NET in a variety of domains - from high-performance algorithmic trading, web programming, to data access and ORMs - and is lead dev on .NET support for the PostgreSQL database (Npgsql).
Other activities include working as a logistician with Doctors Without Borders, translating philosophy books, and political activism.
Follow him on Twitter @shayrojansky