Going Social with DocumentDB
Editor’s note: The following post was written by Windows Development MVP Matias Quarantaas part of our Technical Tuesday series.
Down the rabbit hole
Living in a massive-interconnected society means that, at some point in life, you become part of a Social Network. We use Social Networks to keep in touch with friends, colleagues, family, or sometimes to share our passion with people with common interests.
As engineers or developers, we might have wondered how do these Networks store and interconnect our data, or might have even been tasked to create or architecture a new Social Network for a specific niche market yourselves. That’s when the big question arises: How is all this data stored?
Let’s suppose that we are creating a new and shiny Social Network, where our Users can Post articles with related media like, Pictures, Videos or even Music. Users can Comment on posts and give Points for rating. There will be a Feed of posts that users will see and be able to interact with on our main website landing. This doesn’t sound really complex (at first), but for the sake of simplicity, let’s stop there (we could delve into custom user feeds affected by relationships, but it exceeds the goal of this article).
So, how do we store this and where?
Many of you might have experience on SQL databases or at least have a notion of relational modelling of data and you might be tempted to start drawing something like this:
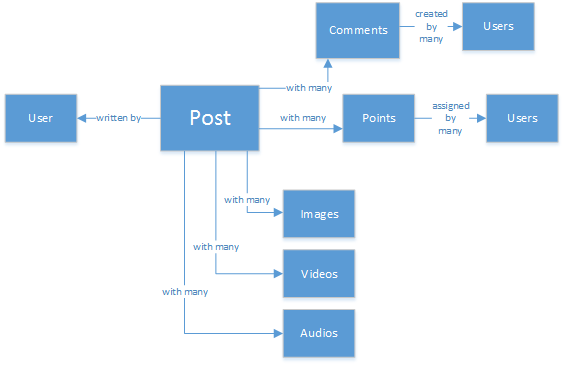
A perfectly normalized and pretty data structure… that fails.
Don’t take it wrong; I’ve worked with SQL databases all my life, they are great, but like every pattern, practice and software platform, it’s not perfect for every scenario.
Why does it fail? Let’s look at the structure of a single Post. If I wanted to show that Post in a website or application, I’d have to do a query with… 8 table Joins (!) just to show one single Post, now, picture a stream of posts that dynamically load and appear on the screen and you might see where I am going.
We could, of course, pay for a humongous SQL instance with enough power to solve thousands of queries with these many joins to serve our content, but truly, why would we? We are not on the Apollo 13 thankfully, and we do not need to fit a square SQL engine into our circular data.

The NoSQL Road
There are special Graph databases that can run on Azure but they are far from cheap and require IaaS services (Infrastructure-as-a-Service, Virtual Machines mainly) and maintenance. I’m going to aim this post at a lower cost solution that will work for most scenarios, running on Azure’s NoSQL database DocumentDB. Using a NoSQL approach, storing data in JSON format and applying denormalization, our previously complicated Post can be transformed into a single Document:
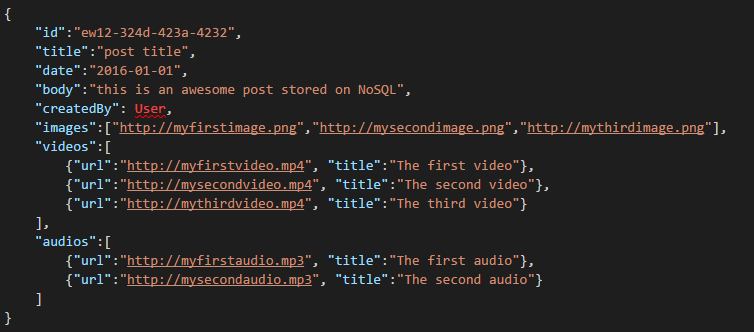
And it can be obtained with a single query, with no Joins. This is much more simple and straightforward, and, budget-wise, it requires fewer resources to achieve a better result.
Azure DocumentDB makes sure that all the properties are indexed with its Automatic Indexing, which can even be customized. The schema-free approach lets us store Documents with different and dynamic structures, maybe tomorrow we want Posts to have a list of Categories or Hashtags associated with them, DocumentDB will handle the new Documents with the added attributes with no extra work required by us.
Comments on a Post can be treated as just other Posts with a Parent (this simplifies our Object mapping).
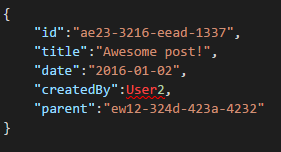
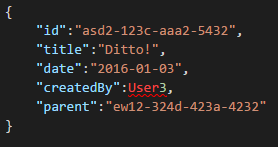
And all social interactions can be stored on a separate object as counters:
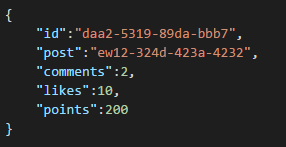
Creating feeds is just a matter of creating Documents that can hold a list of post ids with a given relevance order:
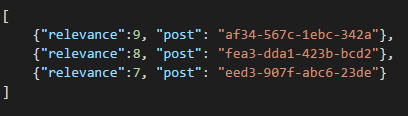
We could have a “latest” stream with posts ordered by creation date, a “hottest” stream with those posts with more likes in the last 24 hours, we could even implement a custom stream for each user based on logics like Followers and Interests, and it would still be a list of posts. It’s a matter of how to build these lists, but the reading performance remains unhindered. Once we acquire one of these lists, we issue a single query to DocumentDB using the IN operator to obtain pages of posts at a time.
The Feed streams could be built using Azure App Services’ background processes: Webjobs. Once a Post is created, background processing can be triggered by using Azure Storage Queues and Webjobs triggered using the Azure Webjobs SDK, implementing the post propagation inside streams based on our own custom logic.
Points and Likes over a post can be processed in a deferred manner using this same technique to create an eventually consistent environment.
The “Ladder” pattern and Data duplication
As you might have noticed in the JSON document that references a Post, there are multiple occurrences of a User. And you’d have guessed right, this means that the information that represents a User, given this denormalization, might be present in more than one place.
In order to allow for faster queries, we incur in Data Duplication. The problem with this side-effect is that if by some action, a User’s data changes, we need to find all the activities he ever did and update them all. Doesn’t sound very practical, right?
Graph databases solve it in their own way, we are going to solve it by identifying the Key attributes of a User that we show in our application for each activity. If we visually show a Post in our application and show just the Creator’s name and picture, why store all of the User’s data in the “createdBy” attribute? If for each comment we just show the User’s picture, we don’t really need the rest of his information. That’s where something I call the “Ladder pattern” comes into play.
Let’s take a User information as an example:
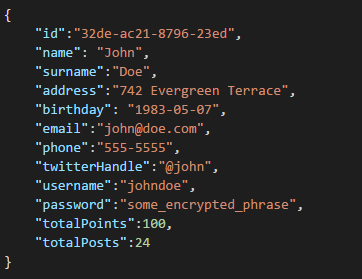
By looking at this information, we can quickly detect which is critical information and which isn’t, thus creating a “Ladder”:

The smallest step is called a UserChunk, the minimal piece of information that identifies a User and it’s used for Data Duplication. By reducing the size of the duplicated data to only the information we will “show”, we reduce the possibility of massive updates.
The middle step is called the User, it’s the full data that will be used on most performance-dependent queries on DocumentDB, the most accessed and critical. It includes the information represented by a UserChunk.
The largest is the Extended User. It includes all the critical User information plus other data that doesn’t really require to be read quickly or its usage is eventual (like the login process). This data can be stored outside of DocumentDB, in Azure SQL Database or Azure Storage Tables.
Why would we split the User and even store this information in different places? Because storage space in DocumentDB is not infinite and from a performance point of view, the bigger the documents, the costlier the queries. Keep documents slim, with the right information to do all your performance-dependent queries for your Social Network, and store the other extra information for eventual scenarios like, Full Profile Edits, Logins, even Data Mining for usage analytics and Big Data initiatives. We really don’t care if the data gathering for Data Mining is slower because it’s running on a slower Azure SQL Database, we do concern though that our users have a fast and slim experience. A User, stored on DocumentDB, would look like this:
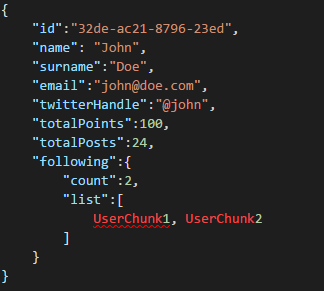
And when an edit arises where one of the attributes of the Chunk is affected, it’s easy to find the affected documents by using queries that point to the indexed attributes (SELECT * FROM posts p WHERE p.createdBy.id == “edited_user_id”) and then updating the Chunks.
The Search Box
Users will generate, luckily, a lot of content. And we should be able to provide the ability to search and find content that might not be directly in their content streams, maybe because we don’t follow the creators, or maybe we are just trying to find that old post we did 6 months ago.
Thankfully, and because we are using Azure DocumentDB, we can easily implement a search engine using Azure Search in a couple of minutes and without typing a single line of code (other than obviously, the search process and UI).
Why is so easy?
Azure Search implements what they call, Indexers, background processes that hook in your data repositories and automagically add, update or remove your objects in the indexes. They support an Azure SQL Database indexers, Azure Blobs indexers and thankfully, Azure DocumentDB indexers. The transition of information from DocumentDB to Azure Search is straightforward, both store information on JSON format, we just need to create our Index and map which attributes from our Documents we want indexed and that’s it, in a matter of minutes (depends on the size of our data), all our content will be available to be searched upon, by the best Search-as-a-Service solution in Cloud Infrastructure.
For more information about Azure Search, you can visit the Hitchhiker’s Guide to Search.
The underlying knowledge
After storing all this content that grows and grows every day, we might find ourselves thinking: What can I do with all this stream of information from my users?
The answer is straightforward: Put it to work and learn from it.
But, what can we learn? A few easy examples include Sentiment Analysis, Content Recommendations based on a user’s preferences or even an automated Content Moderator that ensures that all the content published by our Social Network is safe for the family.
Now that I got you hooked, you’ll probably think you need some PhD in math science to extract these patterns and information out of simple databases and files, but you’d be wrong.
Azure Machine Learning, part of the Cortana Analytics Suite, is the a fully managed cloud service that lets you create workflows using algorithms in a simple drag-and-drop interface, code your own algorithms in R or use some of the already-built and ready to use APIs such as: Text Analytics, Content Moderator or Recommendations.
Conclusion
This article tries to shed some light into the alternatives of creating Social Networks completely on Azure with low-cost services and providing great results by encouraging the use of a multi-layered storage solution and data distribution called “Ladder”.
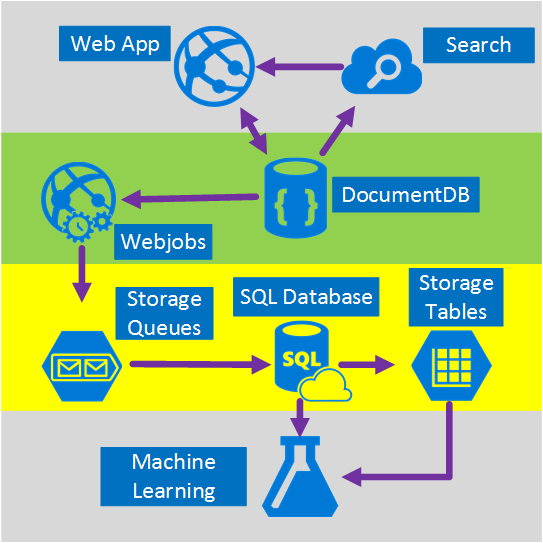
The truth is that there is no silver bullet for this kind of scenarios, it’s the synergy created by the combination of great services that allow us to build great experiences: the speed and freedom of Azure DocumentDB to provide a great social application, the intelligence behind a first-class search solution like Azure Search, the flexibility of Azure AppServices to host not even language-agnostic applications but powerful background processes and the expandable Azure Storage and Azure SQL Database for storing massive amounts of data and the analytic power of Azure Machine Learning to create knowledge and intelligence that can provide feedback to our processes and help us deliver the right content to the right users.

About the author
Matias is a Microsoft MVP, Azure & Web Engineer, open source contributor and firm believer in the freedom of knowledge.