Rethinking SharePoint Project Cost Estimation with Azure Machine Learning
Editor’s note: The following post was written by Office Servers and Services MVP John Timney as part of our Technical Tuesday series with support from his technical editor, Office Servers and Services MVP Mark Stokes
Costing SharePoint projects, or any projects for that matter can be really difficult, but what if you could simplify that dramatically by looking at data science and Azure?
Bring on Azure Machine Learning (AML) and you suddenly have an opportunity to amalgamate your legacy cost information to better predict future outlay for pretty much anything. What makes it even better is that it’s not really very hard to start using AML and then to move on to looking at alternative strategies for other types of predictive outcomes, and you don’t have to be an experienced data scientist to dip your toe in the water and get real fiscal potential from drag and drop solutions in Azure.
In this article, we will look at what Machine Learning (ML) is and focus on just enough to get using AML. We’ll briefly show you how to take a dataset of legacy SharePoint project costs and then use AML to predict what future project costs would be without any calculations, and it is remarkably accurate.
What is Machine Learning?
Machine learning is a type of artificial intelligence (AI) that provides computers with the ability to learn without being explicitly programmed. It focuses on the development of computer programs that can teach themselves to grow and change when exposed to new data without having to recode algorithms, or in some cases to even have to build them at all.
As an example: The Stanford Artificial Intelligence Lab built some algorithms that learned to recognize a cat from sampling millions of (cute) cat images on the internet without having any prior concept of a “cat.” I’m not sure what a “cute” cat is specifically as opposed to an ugly one but I expect all cats have similar types of facial properties. The challenge is learning how to craft code to tell us what a cats features might be, when faced with random images.
So ML is the ability to learn from data without writing statements that then force the outcome. As the data changes, so does the learning, and typically the more data the more accurate the learning as more comparisons and evaluations can be carried out by the learning engine.
The example above literally said “here are lots of cat images, learn what features imply a cat so we can compare if a zebra is a cat”. Now, think – how would you even begin to code this? I’m not a coder, but determining Cat from Zebra likely implies lots of “If” statements, or “case” statements – or equally complex code evaluations and pixel comparisons involving whiskers, tails and black and white stripes.
The question with ML though is really one of possibility! What would you like to do that you can't currently do? What do you do now that you would like to do better? It allows you to reshape “What problem am I trying to solve” to “what outcome am I seeking to predict” – “Can I predict the cost of a SharePoint engagement”, because I know what SharePoint engagements characteristics look like”? Can I in fact recognise cat without coding for cat?
Why Learn about Machine learning?
The question then moves to Why Learn about Machine learning and there are some general reasons to consider this:
• Learn it when you can’t easily code it (e.g. for speech recognition)
• Learn it when you can’t easily scale it (e.g. recommendations, Spam detection)
• Learn it when you have to easily adapt/personalize data (e.g. predictive typing)
• Learn it when you can’t easily track it (e.g. robot control)
Never mind detecting pictures of cats, what about child protection and detecting pictures of vulnerable children, how about better and more accurate speech recognition to help in language translation or the fight against terrorism. SPAM is growing at an exponential pace, and we can’t just continue to develop more pattern matches and bigger SPAM engines that fail, so we “learn” what SPAM looks like and predict phishing patterns.
New technology is also already embracing this: Office Delve (https://products.office.com/enus/business/explore-office-delve) uses predictive learning via Office Graph to determine things related to what you are seeking in a search, so likes and personalisation, related things and stuff people you are connected to like that you would also like – it learns not only what you are searching for but stuff about you to add a personal dimension to the results. It learns from your interactions, without needing to be recoded and improves itself as data grows.
What about AI based gaming – we can’t code what you might do next, but we can predict based on known patterns of how people have played and therefore what they might do next and the game can respond and get better as you play – more aggressive and realistic competition. What if we coupled Hololens (https://www.microsoft.com/microsoft-hololens/en-us), with Machine Learning and speech translation to visually interpret actual sign language to speech for non-sign language capable users to interact better with deaf users across the internet, in a different language?
What about handwriting, how does the post office manage with so many handwritten letters? The obvious challenge in text automation is enabling computers to interpret the endless variation in handwriting, given we are all unique.
Let’s take a simple letter F:
How could we analyse the recognition of F? I have no rule in my head that tells me what an F looks like, that’s a learned skill! But I recognise F as I was taught my alphabet as a child.
F simply looks like F! In English anyway, in Arabic it’s an entirely confusing affair for me as we can see here from this snap. I don’t recognise Arabic F, there are four possibilities to basic shape to make it worse, but it also has characteristics that tend to repeat, a loop, a curl a dot!
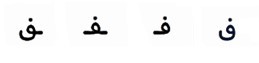
Well, I suppose then if it looks like an F, if it is shaped like an F, if it appears like an F in a word full of letters and the other letters also predicted make up a recognised word, it’s a fair probability that it is an F, its likely more right than it is wrong.
But how many variations are there to F? We would all write that differently, although like the cats face, it’s full of characteristics.
If we can get a computer to make that same prediction using some form of process, that’s very useful, and in fact very valuable to the POST OFFICE and other business dealing with flowing text. Industry has trained computers to accurately read human handwriting. Today, with the help of machine learning, over 98% of all mail is successfully processed by machines. They know and recognise F in its many forms, even in Arabic.
So there is clearly value to the modern I.T Professional understanding about Machine Learning, it helps to solve problem we didn’t know we actually had until we thought how we might want to do something better, or specifically with less development time and thus less effort cost.
A lesson in History
Few of us have much experience in AI and Expert Systems, as we are not data scientists. I spent quite some time working on Expert Systems creating financial forecasting predictions for UK government in the 1990’s, so I almost qualify - but while few I.T Pro are data scientist, a lot has happened since then that makes it a bit easier to use this tech – perhaps you don’t need to be a Data Scientist to do data science!
The ability to actually perform SPAM detection around 1997 was a bit of a milestone event – but it is reaching its limits now and we need a new approach. Can AML better detect spam by learning about SPAM in a new way?
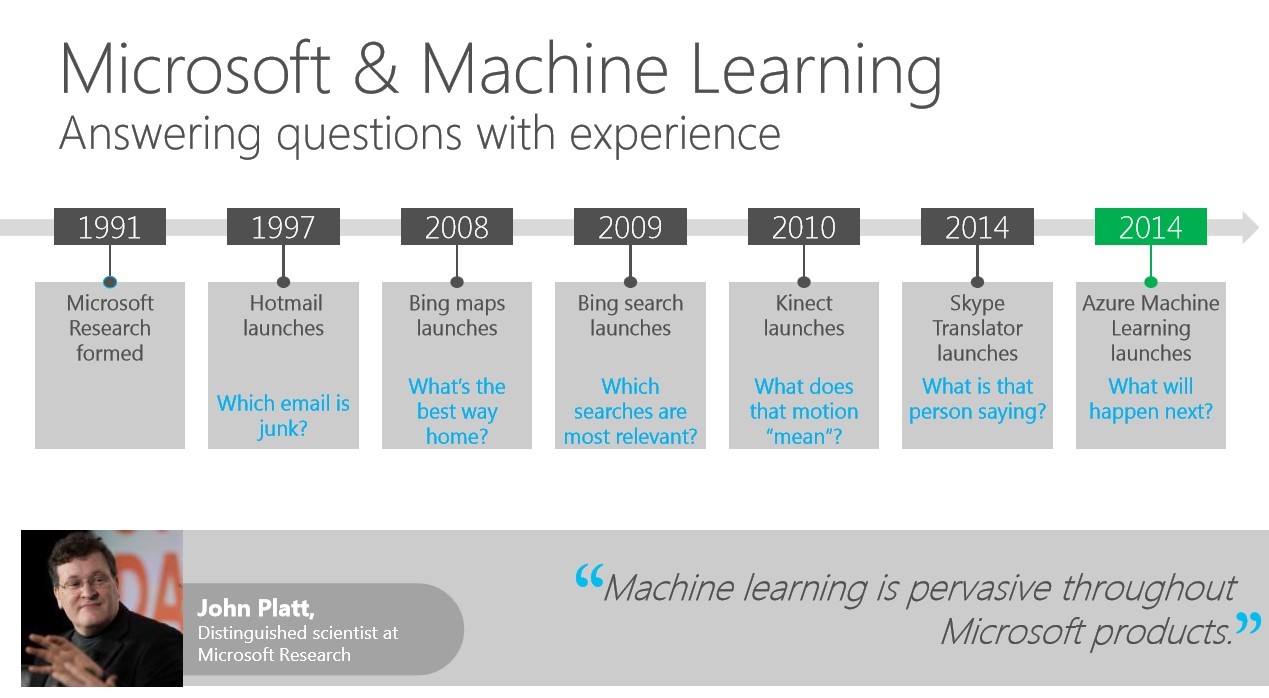
Figure 1 https://download.microsoft.com/documents/hk/technet/techdays2015/Day2/DBI216
Look at how far we have really come already though! By 2008 we can make traffic predictions; by 2010 we can track unplanned user movement in the XBOX; by 2012 we can do Speech to Speech language conversion in REAL TIME, soon to appear in SKYPE.
In 2014 Microsoft launched Azure Machine Learning (AML) – and now I don’t need to invest millions to build similar types of predictive solutions to those so heavily invested in before this. AML is in fact just a hosted cloud service, and a very, very powerful one at that!
Initially, machine learning and Expert Systems generally were very expensive to setup and were a real barrier to entry. Also, data has historically been siloed in industry. That very data we need to do the learning and our view of data silos in organisations meant we needed industry itself to change the way we thought about data stores, data in the CLOUD is now acceptable – generally at least.
Tools to do ML were historically rather typically cumbersome and expensive, or we spent years of effort in developing solutions that were constrained and bound to tight rules and complexity. Data Science was just that – the realm of scientists.
Even when we made the investment to build something to work like ML, it was really constrained by our data centres ability to host or scale, and now even those rules themselves have evolved and changed with Azure hosting and storage.
Thus, history has then led us to a very interesting point, as the Gartner Hype Cycle for 2015 has Machine Learning as something that seriously needs attention by business, as it will mature in 2 to 5 years.
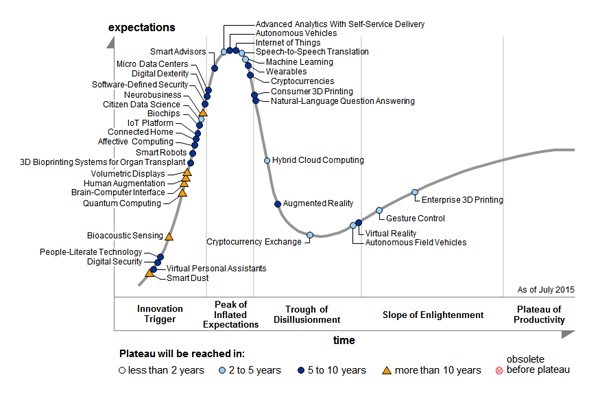
Figure 2 https://www.gartner.com/newsroom/id/3114217
Early adoption is going to be key for I.T. Pros to get familiar with this new Azure cloud service and make their mark, and the possibilities are really quite endless. Which brings us nicely to one possibility – can we predict the cost of SharePoint projects with AML, and more specifically can we do it without writing code or cranking open excel and working out a lot of IF then formulae?
Building a SharePoint Project Cost Engine
Using AML is really quite easy for beginners, but when you open it all up, it looks a bit daunting.
The working environment consists of the AML portal in Azure – the bit that holds all the backend services; ML Studio – a drag and drop interface for building experiments like this and the API service, so we can interact with it remotely and securely.
That technology stack is supported by people, the Azure Ops team who maintain the backend services, data scientists (or at least temporary ones like you and I) that make the experiments and developers, who like to get whizzy with AML through the API.
We will focus on Portal, ML Studio and on being a data scientist and leave the rest aside. It’s not really necessary for our experiment. If you are a developer or a solution architect then you might want to investigate the API side once you’ve got your head around this.
We start by logging into ML Studio, in the Azure portal. You can use a trial account for this, so I’ll assume you have access and can work your way to the below URL and log in:
https://studio.azureml.net/
ML Studio looks like that shown below, and these are experiments I have active currently in my ML studio tenancy:
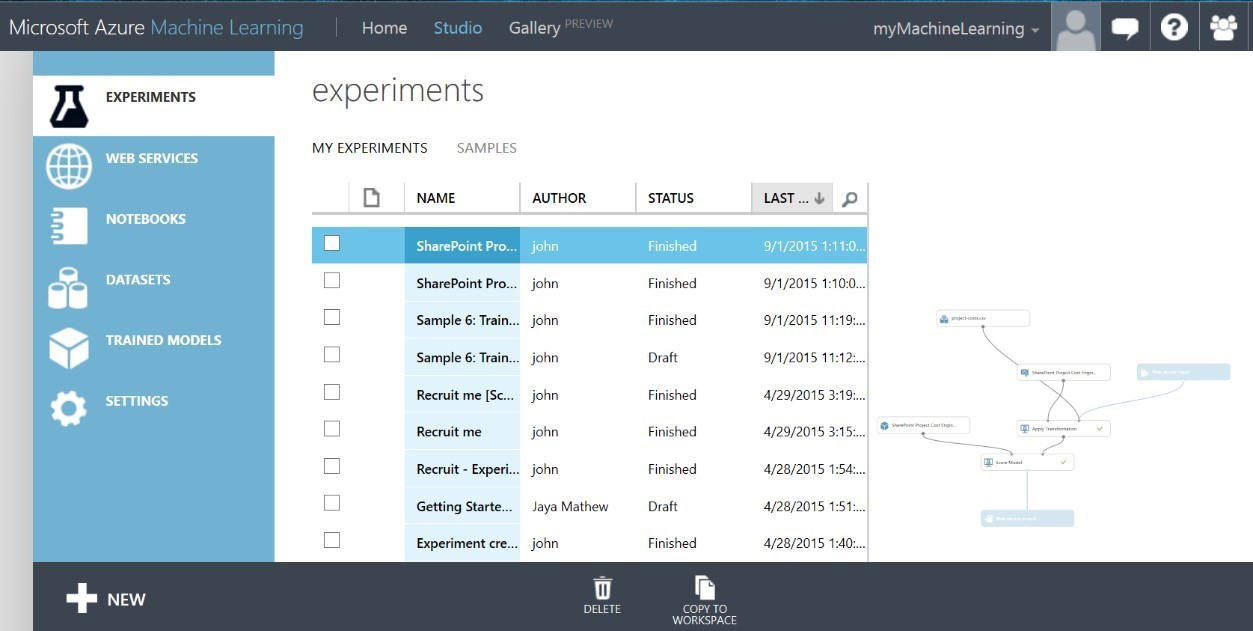
Figure 4 ML Studio
The DataSet
We also need data for AML to consume. Cleverly, you can use the Reader module in AML to load data into an experiment from a Web URL, Hadoop and Hive and a number of Azure sources. We’re just going to pre-load a CSV file in to AML.
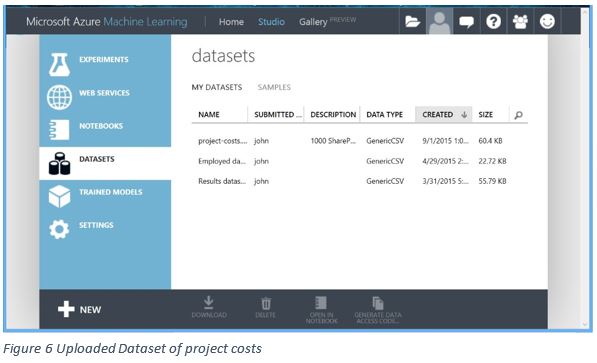
So, let’s take a sample set of fictitious SharePoint project costs as a CSV file, made up of an amalgamation of various priced objects and a final price for the implementation of @1000 projects.

Figure 5 Dataset of project costs
Note: The XLS file is also supplied, it shows how the sample costs were derived using formulae
The CSV contains a typical set of information regarding a SharePoint build: Is it on premises or cloud hosted; what were the data volumes, did we need Azure backup, how many physical or virtual servers were required, how many use cases required configuration, if it was hybrid what was the complexity level, etc. etc. Just like a real project cost analysis and building on experience, the more repeated examples of data you have, the more likely of an accurate prediction of a final implementation price.
We will upload this CSV extract into the datasets section of ML Studio by adding a new Dataset.

Once we have our dataset loaded, we need to build an experiment and consume the dataset.
Interestingly, you can easily view the dataset with the ”Open in Notebook” option at the bottom of the page which opens the Jupyter Python editor ( https://blogs.technet.com/b/machinelearning/archive/2015/07/24/introducing-jupyter-notebooks-in-azure-ml-studio.aspx ) and allows you to code around and filter the data in ML Studio. We do not need that – but it demonstrates the power and investment in ML Studio as this is a fairly recent addition to ML.
If you view the dataset in Excel or in Jupyter (or right click and visualise) you may also notice there are no calculations performed within the dataset, and no formulae applied as this is an extract of just data, decision points and prices. How then can you actually make a cost prediction? Well AML provides lots of modules to choose from to help build experiments, but for this type of experiment we could use a simple Linear Regression module.
The AML manual (https://msdn.microsoft.com/en-us/library/azure/dn905978.aspx) suggests that we should use linear regression when you want a very simple model for a basic predictive task. Sounds about right as Linear Regression tends to work well on high-dimensional, sparse data sets lacking complexity – just like this one! A good start perhaps?
The Experiment
Our experiment really couldn’t be much simpler to demonstrate how easy AML is to start experimenting with, and looking at how we might solve problems differently in this new AI world. We will build our experiment and we will do it with only drag and drop.
Using ML studio, create a new Experiment and select a Blank experiment. It will appear similar to that shown below in Figure 7:
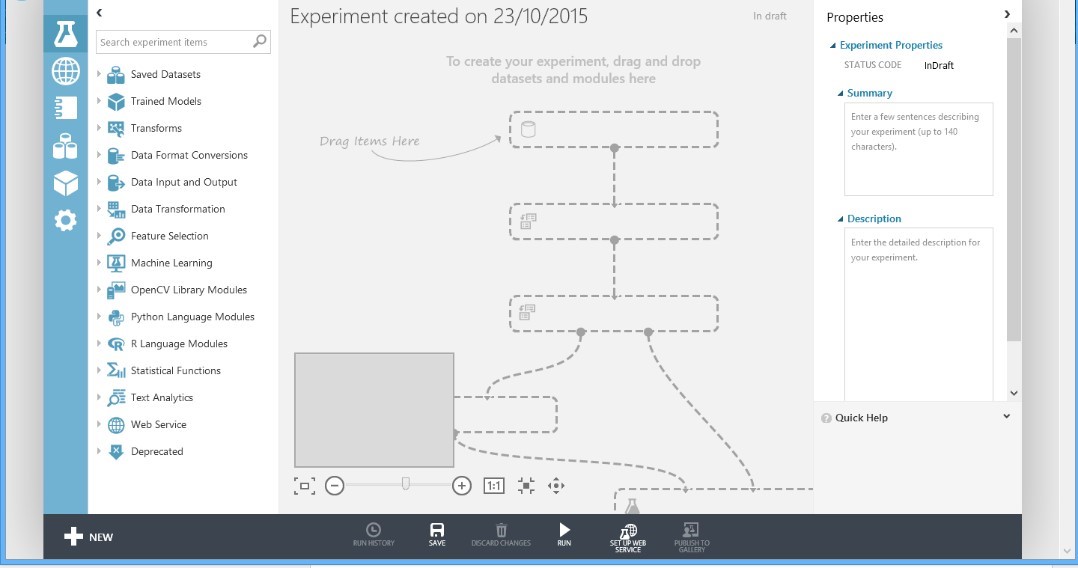
Figure 7 Blank Experiment Screen
You will see, it is telling you to drag and drop and that’s really all we will do.
Drag the Project Costs to the model, and then add the Clean Missing Data module. If you can’t find it, just type project into the Search box and then drag it over. To simplify using ML, Microsoft have created the Search Experiment Items box (top left) so all of the components can be found using search.
Why do we add a Clean Missing Data module, well prediction is based on consistency not guess work and if we have missing data in any single record it can unduly influence the output – so we remove any columns that might corrupt our results?
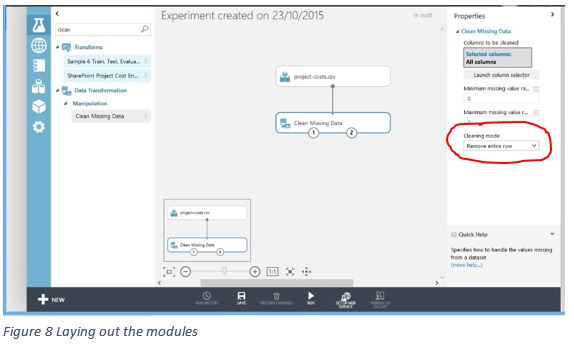
Set the properties for the Clean Missing Data module and in the Cleaning Mode property choose to remove entire row:
There is no SAVE button, it auto-saves in the background for you. There is also no UNDO button.
Replicate the entire experiment (as shown in figure 9) in ML Studio by dragging the component modules and replicating the connections beginning with the previously uploaded dataset.
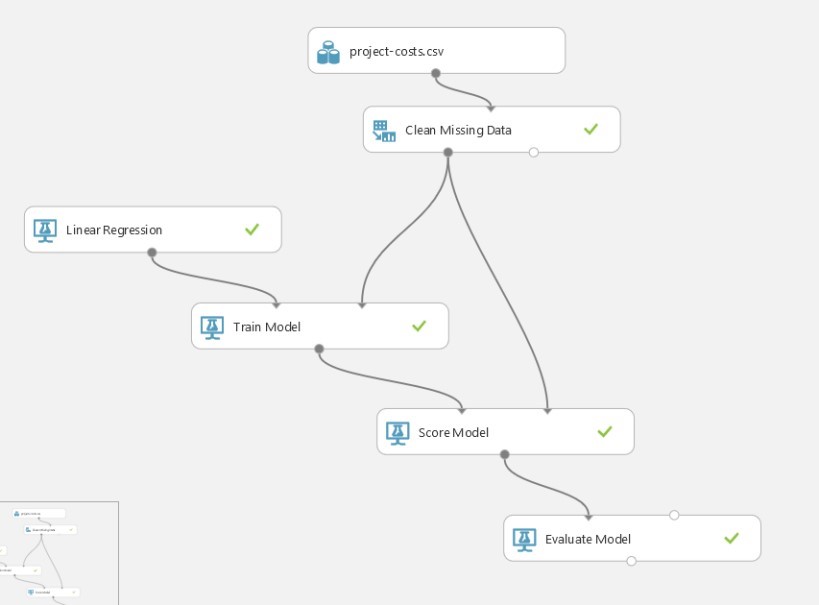
Figure 9 SharePoint Costing Experiment
Interestingly, AML also doesn’t seem to like labels for columns that have spaces or odd characters in them – but it won’t tell you that until you finally try and consume a service you’ve spent an age building!
At this point, you could have also added a Project Column Selector module
(https://msdn.microsoft.com/en-us/library/azure/dn905883.aspx), and limited the scope of inbound data to evaluate from the XLS. For simplicity, we will not do that as we need all inbound data anyway, but it is worth expanding out your experiment once you have the basics under your wing to see what differences you can make.
When you have the Train Model module added, you need to select a column from the dataset to focus on as output for the Linear Regression training activity. Select the ProjectCost label via the properties window via the Launch Column selector.
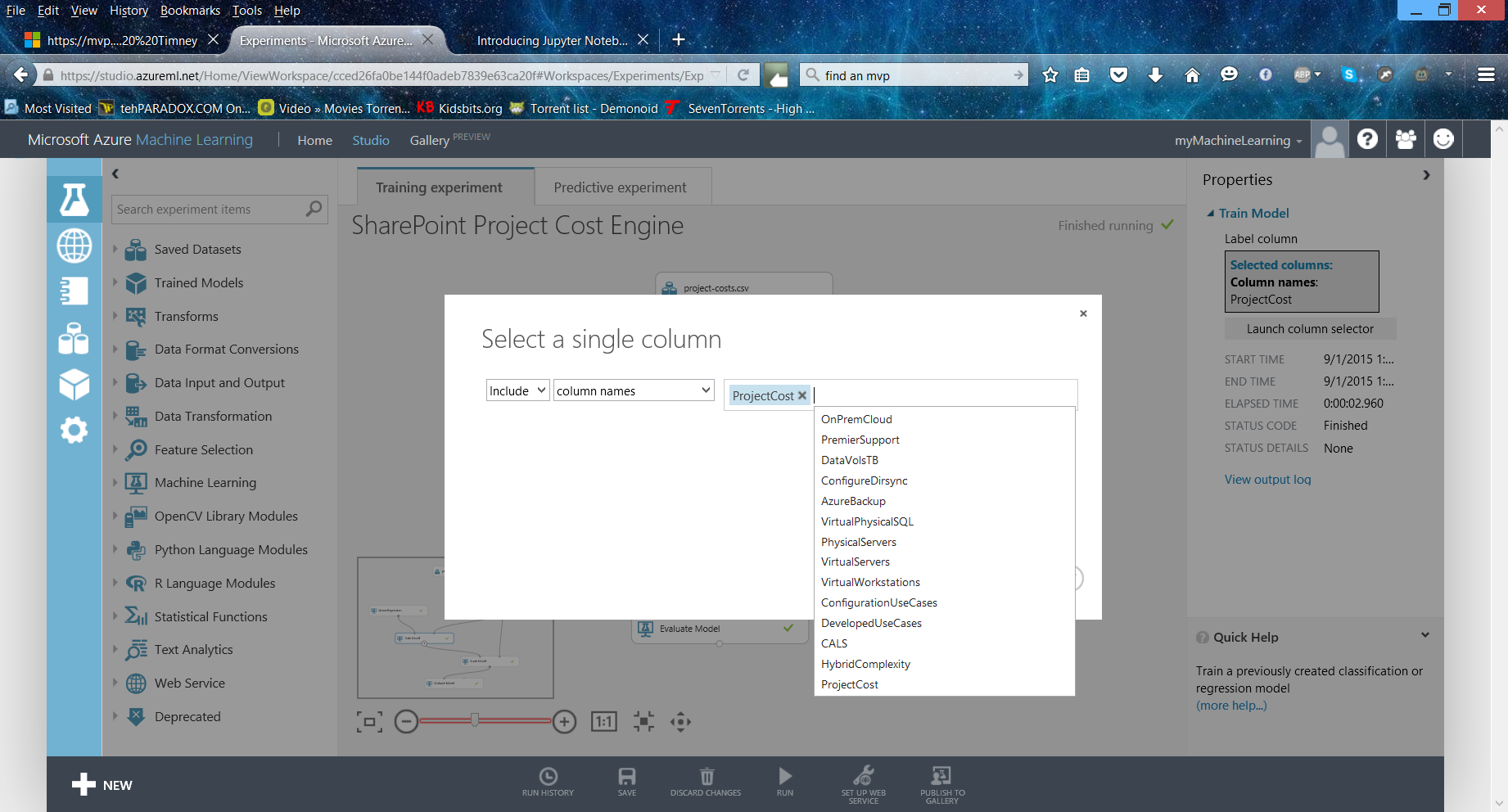
Figure 10 Launch Column selector
This is the single output we actually seek and will eventually be a return value for a web service that AML will automatically create for us to interact with the experiment remotely.
Training a model is like supervised machine learning. You provide a dataset that contains historical data from which AML can then learn patterns. The experiment uses the data to extract statistical patterns and builds a model which it then passes to the scoring module for consumption. You don’t have to write any code to do this, although you can create R code (https://azure.microsoft.com/engb/documentation/articles/machine-learning-r-quickstart/) to make it do more if you need to do that. You’ll also notice that we are only using one training model, and you can use as many as you like and different types of modules to strengthen the outputs once you understand the basics. For this example, one training model is enough.
Once you have it all connected up, and none of the modules are showing warnings you are ready to press the RUN icon at the bottom of the ML Studio screen. When you RUN an experiment you should expect to see lots of green ticks but that is it really. If you are sitting waiting to see something cool before you move on, you might be a bit disappointed.
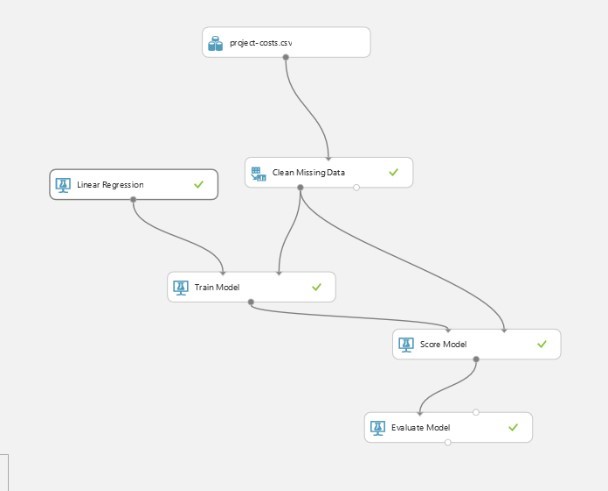
Figure 11 Test Run completed
You want lots of small green ticks to appear in the modules, indicating that AML has successfully executed that module. If you get a RED warning in any module, then go back and check the connections and inputs.
Running the Experiment
So, we have data, and we have an experiment that will consume that data and make predictions. However, we have no easy way to test that experiment at this stage. We need to tell ML to add Web Service endpoints for us.
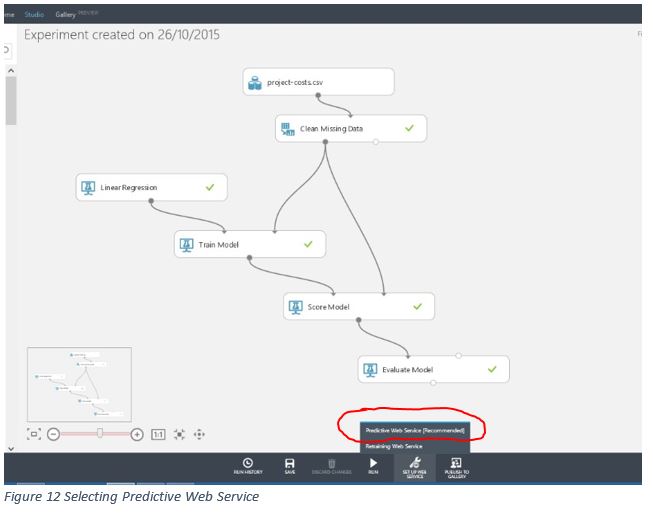
At the bottom of the ML editor screen, there is an icon entitled setup web service, and you need to select Predictive Web Service.
When you select this, ML starts modifying your experiment and adds an entirely new “trained” Predictive Experiment based on your Training Experiment. The Azure "help" dialog may also point out interesting things on the page if this is the first time you have done this.
Studio will add the web services end points so that you can actually interact with it as a remote consumer. Your Studio should then look similar to that in figure 13:
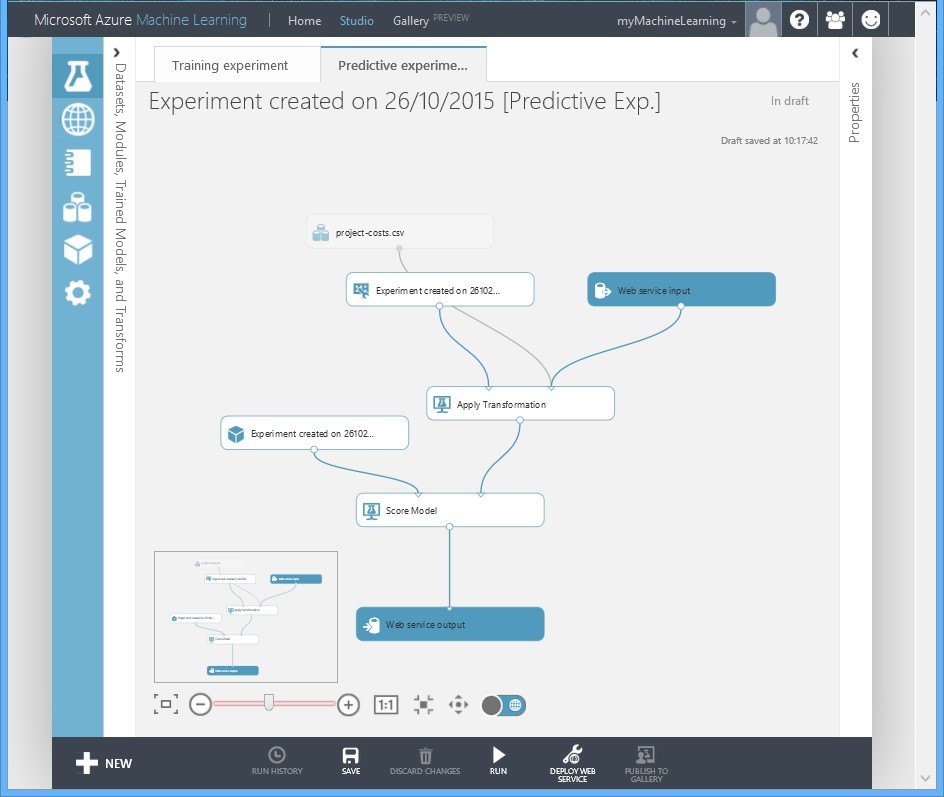
Figure 13 Web Service End-Points automatically added to Predictive Experiment
You have now created an AML Predictive experiment in Azure, and you could even publish that to the AML Gallery to allow other users to consume it. Give it a test RUN before you move to the next step. As before, you want lots of green ticks!
Testing our Model with Inputs
Not much use having a predictive engine, and a stack of legacy SharePoint project data to base predictions on unless we can interact with it. AML also solves that problem for you as it doesn’t want the data scientists to be fiddling with code remotely when they should be spending their time building experiments. AML provides a test harness via Microsoft Excel but to access it we need to deploy the web services we added to our experiment.
Select the Deploy Web Service icon and AML will create a secure interaction method, a secure API key for all you coders, and provides Excel and web based test interfaces.
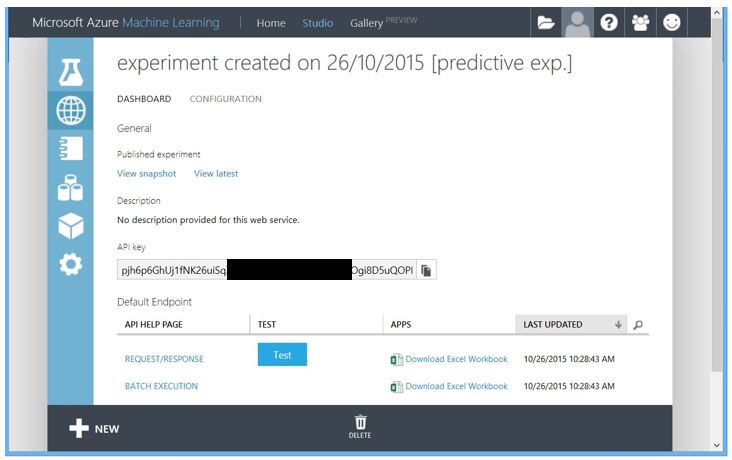
So, you now have a predictive cost engine using a 1000 rows (albeit fictional data) of SharePoint project cost outcomes to experiment with, and predict future project cost outlay.
The web based TEST interface is very basic, if functional. I’d suggest you download the Request/Response Excel file, accept the security caveats when you open Excel and provide some values which it will pass to AML and update a price in real time in the Excel file. Either method should suffice for testing.
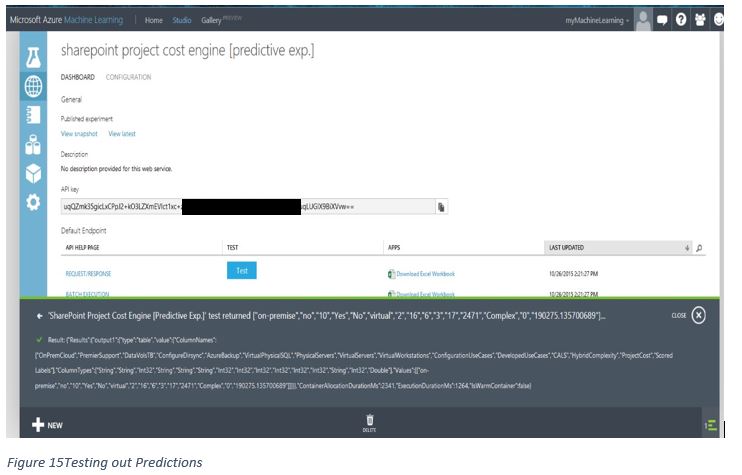
Figure 15Testing out Predictions
Try using the input values in the initial CSV upload and see if you can get both predicted and accurate output. In the example shown in figure 13, if we replicate the first line from the CSV as input using the TEST web service it will predict an accurate value of 190275 for those project variations for the ProjectCost output. Not bad considering we’ve not written a line of code!
Compare variations on your input to the values in the example spreadsheet containing the calculations of how the project costs were derived, see if you can get AML to predict results that are not in the actual CSV values. You can find the spreadsheet on my site: https://www.johntimney.com/?p=215.
Of course, you should not use this to "actually" predict SharePoint project costs for customers. It is an example only and not representative of the actual complexity of calculating SharePoint project costs. Hopefully it has inspired you to go and try AML to build yourself a real costing engine.
Time to play!
https://azure.microsoft.com/en-gb/documentation/services/machine-learning/
Welcome to the new and very much improved world of Data Science.

About the author
John has been in the industry for over 20 years and is currently a Managing Enterprise Architect at Capgemini. John specialises in Enterprise Assurance on large scale Microsoft programs of work, typically involving hundreds of thousands of users, with a strong focus on SharePoint and Office 365, PaaS, IaaS, Azure and Hybrid. He is an international conference speaker and has in his past life co-authored a number of technology related books on fields as diverse as SharePoint, .Net and Java development. John manages the North East branch of the SharePoint User Group in the UK. Follow him @jtimney.