MVP Monday - SQL Server High Availability in Windows Azure Iaas
Editor’s note: The following post was written by Cluster MVP David Bermingham
SQL Server High Availability in Windows Azure Iaas
When deploying SQL Server in Windows Azure you must consider how to minimize both planned and unplanned downtime. Because you have given up control of the physical infrastructure, you cannot always determine when maintenance periods will occur. Also, just because you have given control of your infrastructure to Microsoft it does not guarantee that you are not susceptible to some of the same types of outages that you might expect in your own data center. To minimize the impact of both planned and unplanned downtime Microsoft provides what are called Fault Domains and Upgrade Domains. By leveraging Upgrade Domains and Fault Domains and deploying either SQL Server AlwaysOn Availability Groups (AOAG) or AlwaysOn Failover Cluster Instances (AOFCI) you can help minimize both planned and unplanned downtime in your SQL Server Windows Azure deployment. Throughout this document when I refer to a SQL Server Cluster, I am referring to both AOAG and AOFCI. When needed, I will refer to AOAG and AOFCI specifically.
Fault Domains are essentially “a rack of servers”, with no common single point of failure between different Fault Domains, including different power supplies and network switches. An Update Domain ensures that when Microsoft is doing planned maintenance, only one Update Domain is worked on at a given time. This eliminates the possibility that Microsoft would accidentally reboot all of your servers at the same time, assuming that each server is in a different Update Domain.
When you provision your Azure VM instances in the same Availability Set, you are ensuring that each VM instance is in a different Update Domain and Fault Domain…to an extent. You probably want to read Manage The Availability of Virtual Machines to completely understand how VMs get provisioned in different Fault Domains and Update Domains. The important part of the availability equation is ensuring that each VM participating in your SQL Server cluster is isolated from each other, ensuring that the failure of a single Fault Domain or maintenance in an Update Domain does not impact all of your Azure instances at the same time.
So that is all you need to know….right? Well, not exactly. Azure IaaS does not behave exactly like your traditional infrastructure when it comes to clustering. In fact, before July of 2013, you could not even create a workable cluster in Azure IaaS. It wasn’t until then that they released hotfix KB2854082 that made it possible. Even with that hotfix there are still a few considerations and limitations when it comes to highly available SQL Server in Windows Azure.
Before we dive into the considerations and limitations, you need to understand a few basic Azure terms. These are not ALL the possible terms you need to know to be an Azure administrator, but these are the terms we will be discussing that are specific to configuring highly available SQL Server is Azure IaaS.
Virtual Network
Before you begin provisioning any virtual machines, you will need to configure your Virtual Network such that all your SQL Server Cluster VMs can reside in the same Virtual Network and Subnet. There is an easy Virtual Network Wizard that will walk you through the process of creating a Virtual Network. Additional information about Virtual Networking can be found here.
https://azure.microsoft.com/en-us/services/virtual-network/
If you are considering a Hybrid Cloud deployment where you stretch your on premise network to the Azure Cloud for disaster recovery purposes, you may want to review my blog post below. https://clusteringformeremortals.com/2014/01/07/extending-your-datacenter-to-the-azure-cloud-azure/
As you will see below, It is required that each SQL Server cluster must reside in a dedicated Cloud Service (see Cloud Service section below) and clients must connect to from outside of the Cloud Service. When creating subnets, I would create a small subnet for each cluster I plan to create. These subnets will only hold a handful of VMs and will be used exclusively for the Cloud Services that contain your SQL Server clusters.
Availability Set
As previously mentioned, an Availability Set is used to define Fault Domains and Update Domains. When provisioning your SQL Servers and File Share Witness (more on this later) make sure put all of your virtual machines in the same Availability Set. Availability Sets are described as follows…
“An availability set is a group of virtual machines that are deployed across fault domains and update domains. An availability set makes sure that your application is not affected by single points of failure, like the network switch or the power unit of a rack of servers.”
Cloud Service
Before you go Bing “Azure Cloud Service”, you need to understand that there is the overall marketing term “Cloud Service”, which is all fine and good, but not what we are talking about here. A Cloud Service in Azure IaaS is a very specific feature that is described as follows…
“A cloud service is a container for one or more virtual machines you create. You can create a cloud service for a single virtual machine, or you can load balance multiple virtual machines by placing them in the same cloud service.”
The other thing about a Cloud Service is that it is addressable by a single public IP address. All virtual machines residing in a Cloud Service can be reached by the Public IP associated with the Cloud Service and the endpoint ports defined when you create the virtual machine. Later in this article we will also learn that it is this public IP address that will be used instead of the traditional Cluster IP Resource for connectivity to the cluster.
The thing to remember about highly available SQL Servers is that when creating highly available SQL Server instances, you will want to place ALL of your SQL instances and the File Share Witness in the same Cloud Service. It is required that you have a different Cloud Service for each additional SQL Server Clusters that you create. I also recommend that you reserve that Cloud Service for only the SQL Server cluster nodes and the File Share Witness. You will see later in this article that all SQL Server cluster clients will need to reside outside of the cluster’s Cloud Service, which is just one of the reasons to keep only the SQL cluster nodes and File Share Witness in a dedicated Cloud Service.
You can create a Cloud Service, join an existing Cloud Service, create an Availability Set or join an Availability Set at the time you provision your Virtual Machines as shown in Figure 1 below.
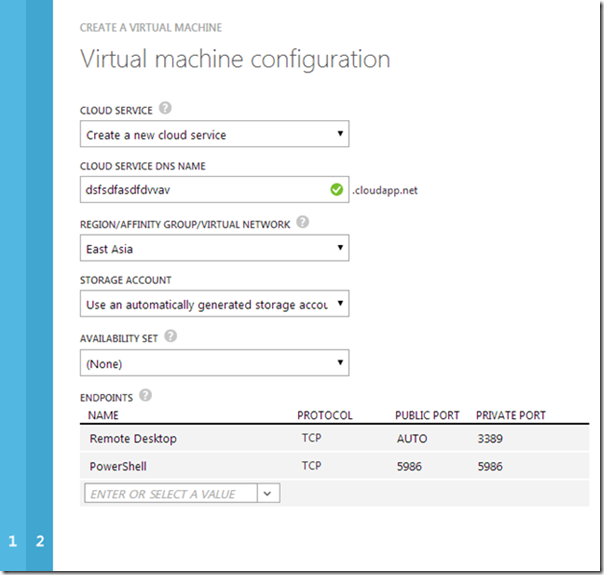
Figure 1 - Cloud Service and Availability Set are defined when creating your virtual machine
Configuration of SQL Cluster
Now that we have a base understanding of some of the Azure terminology, we are ready to begin the cluster installation. Whether you are configuring an AlwaysOn Availability Group Cluster or an AlwaysOn Failover Cluster Instance, you will need to start with a basic cluster configuration. If you are using Windows Server 2012 R2, you are good to go. If you are using Windows Server 2012 or Windows Server 2008 R2, you will first need to install hotfix KB2854082on each cluster node.
Assuming you have minimally completed the pre-requisites below, you are ready to create your cluster.
Pre-requisites
1. Create your Azure Virtual Network
2. Provisioned three VMS. We’ll call these VMs SQL1, SQL2 and DC1 for simplicity through the rest of this document
3. These VMs should all reside in the same Cloud Service and Availability Set
4. Applied hotfix KB2854082 if necessary (pre-Windows 2012 R2)
5. Created a Windows Domain and joined all servers to the domain
Creating a cluster is pretty straight forward; I won’t go into great detail here as it is the same as creating an onsite cluster. The one major difference is at the end of the process. You will see that the Cluster Name resource will fail to come online. The reason the Cluster Name Resource fails to come online is that Azure VMs get their IP Address information from DHCP, which will issue the same IP to the cluster. When the non-RFC-compliant DHCP service in Azure issues a duplicate IP address the Cluster IP Address resource to fail to come online. In order to fix this, you will need to manually specify another address that is not in use in the subnet. Because we have no control over the DHCP scope, I would choose an IP address that is near the end of the scope. This is another reason why I like to limit the Cloud Service to just the cluster nodes, so I don’t accidentally provision another VM that uses an IP address I have already specified for my cluster.
Because there is no shared storage in Azure, you will notice that the quorum configuration defaulted to Node-Majority. Node-majority for a two node cluster is certainly not optimal. You will need to configure a File Share Witness (FSW). In my example configuration, I configured the FSW on DC1. Wherever you configure the FSW you should ensure that the FSW is in the same Availability Set as the cluster nodes. This ensures that don’t have a failure of a cluster node and the FSW at the same time.
Now that you have configured the basic cluster, you will need to decide whether you want to deploy an AlwaysOn Availability Group (AOAG), or whether you want to deploy an AlwaysOn Failover Cluster Instance (AOFCI). To deploy an AlwaysOn Failover Cluster Instance you will need to use a 3rd party, cluster integrated replicated volume resource, such as SIOS DataKeeper Cluster Edition as there is currently no shared storage option in Azure suitable for clustering.
AOAG or AOFCI?
This post assumes that you are familiar with SQL Server AlwaysOn options, if not you should review High Availability Solutions (SQL Server)
While AOAG can meet the needs of many, there are certainly situations where AOAG does not fulfill the requirements. The chart below highlights some of the limitations of AOAG in comparison to AOFCI with SIOS DataKeeper Cluster Edition.
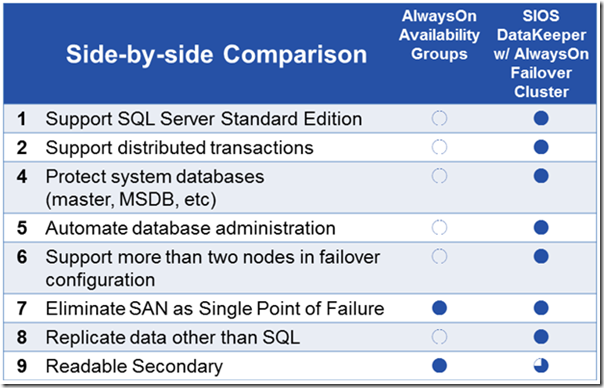
Figure 2 - AOAG vs. AOFCI with DataKeeper
In my experience, the two biggest reasons why people are deploying AOFCI rather than AOAG is the support for SQL Server Standard Edition and because it protects the entire SQL Server Instance rather than just the user defined databases. The later reason becomes even more important after you discover that Windows Azure only supports one client access point, meaning with AOAG all of your database must reside in a single Availability Group. It is also much easier to create one AOFCI and have every database, including System and MSDB, be replicated and protected rather than having to manually manage Agent Jogs, SQL user accounts and each database manually as you do with AOAG.
Configuring AOFCI and AOAG
Once again, the basic configuration of AOFCI or AOAG in the Azure Cloud is pretty much identical to how you would configure these services with on premise servers. (For detailed instructions on deploying a #SANLess cluster with DataKeeper visit my article Creating a SQL Server 2014 AlwaysOn Failover Cluster (FCI) Instance in Windows Azure IaaS). The difference comes when you are configuring the client access point. As we saw with the initial cluster creation process, the Cluster Name resource will fail to come online because the DHCP service will hand out a duplicate IP address. However, instead of simply specifying another address in the same subnet, you will need to set the Client Access Point IP address to be the same as the Cloud Service’s public IP address, with a host specific subnet mask of 255.255.255.255. Clients will then access this SQL Cluster via load-balanced VM endpoints with direct server return. The directions outlined in the Configuring the Client Access Point section below will tell you exactly how to put this all together.
Configuring the Client Access Point
Configuring the client access point and the load balanced endpoint is probably the most confusing or misunderstood part of creating SQL Server clusters in Windows Azure, or at least it was for me. If you are configuring AOAG you are in luck, there is a great article that walks you through this process Step-by-Step.
https://msdn.microsoft.com/en-us/library/dn425027.aspx
However, if you want to configure AOFCI, you have to take some of the information supplied in that article and apply it to AOFCI rather than an AOAG. You can follow Steps 1 through 3 as described in https://msdn.microsoft.com/en-us/library/dn425027.aspx to create the load balanced endpoints. However, when you get to Step 4 you will have to make adjustments since you will already have configured a client access point as part of your SQL Server Cluster Role configuration. On Step 4, “Create the availability group listener”, you can skip 1-6 and continue with 7 through 10 to change the IP address of the SQL Server Cluster resource. Once the IP address has been changed, you can bring the SQL Server Failover cluster instance online.
Accessing the SQL Cluster in Azure
As previously described, the SQL Server cluster must be accessed from outside of the Cloud Service via the load balanced endpoint. Depending upon which server is active, the load balanced endpoint will redirect all client requests to the active server. At the end of the day, your SQL Server cluster should look something like Figure 3 shown below.
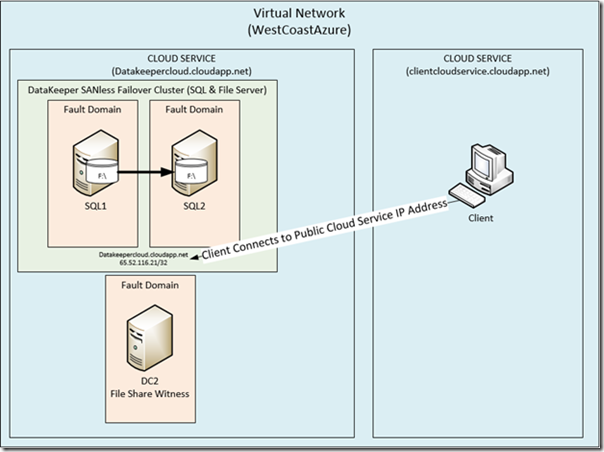
Figure 3 - Clients accessing the SQL Server Cluster
What about Hybrid Cloud?
While this blog post is focused on High Availability in the Azure Cloud, it is certainly possible to build Disaster Recovery configurations which have some SQL cluster nodes in Azure and some nodes on premise. For more information on Hybrid Cloud configurations, read my article Creating a multi-site cluster in Windows Azure for Disaster Recovery. That article describes Hybrid Cloud solutions such as those pictured in Figure 4 below.
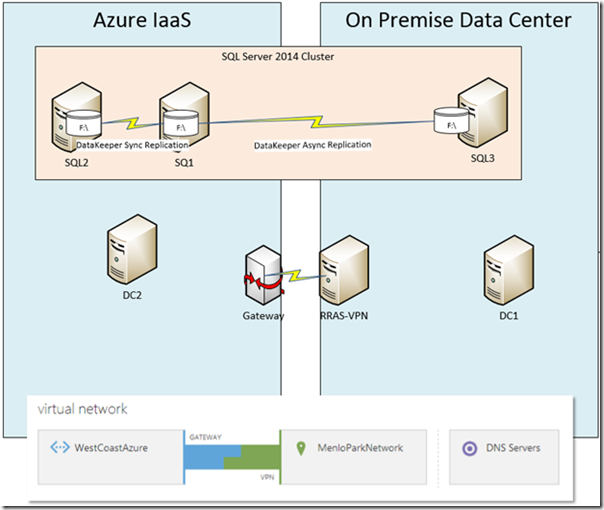
Figure 4 - Hybrid Cloud for Disaster Recovery
Summary
Windows Azure IaaS is a powerful platform for deploying business critical applications. All of the tools required to build a highly available infrastructure are in place. Knowing how to leverage those tools, especially in regards to providing High Availability for SQL Server, can take a little research and trial and error. I hope that this article has helped point you in the right direction and has reduced the amount of research and trial and error that you will have to do on your own. As with most Cloud Service, new features become available very rapidly and the guidance in the article may become outdated or even wrong in some cases rather rapidly. For the latest guidance, please refer to my blog Clustering for Mere Mortals where I will attempt to update guidance as things in Azure evolve.
About the author

David Bermingham is recognized within the technology community as a high availability expert and has been honored by his peers by being elected to be a Microsoft MVP in Clustering since 2010. David’s work as director of Technical Evangelist at SIOS has him focused on evangelizing Microsoft high availability and disaster recovery solutions as well as providing hands on support, training and professional services for cluster implementations. David hold numerous technical certifications and draws from over twenty years of experience IT, including work in the finance, healthcare and education fields, to help organizations design solutions to meet their high availability and disaster recovery needs. David has recently begun speaking on deploying highly available SQL Servers in the Azure Cloud and deploying Azure Hybrid Cloud for disaster recovery.
About MVP Mondays
The MVP Monday Series is created by Melissa Travers. In this series we work to provide readers with a guest post from an MVP every Monday. Melissa is a Community Program Manager, formerly known as MVP Lead, for Messaging and Collaboration (Exchange, Lync, Office 365 and SharePoint) and Microsoft Dynamics in the US. She began her career at Microsoft as an Exchange Support Engineer and has been working with the technical community in some capacity for almost a decade. In her spare time she enjoys going to the gym, shopping for handbags, watching period and fantasy dramas, and spending time with her children and miniature Dachshund. Melissa lives in North Carolina and works out of the Microsoft Charlotte office.