SQL Server 2014 DML Triggers: Tips & Tricks from the Field
Editor’s note: The following post was written by SQL Server MVP Sergio Govoni
SQL Server 2014 DML Triggers: Tips & Tricks from the Field
SQL Server 2014 DML Triggers are often a point of contention between Developers and DBAs, between those who customize a database application and those who provides it. They are often the first database objects investigated when the performance degrades. They seem easy to write, but writing efficient Trigger, though complex have a very important characteristic: they allow solving problems that cannot be managed in any other application layer. Therefore, if you cannot work without them, in this article you will learn tricks and best practices for writing and managing them efficiently.
All examples in this article are based on AdventureWorks2014 database that you can download from codeplex website at this link.
Introduction
A Trigger is a special type of stored procedure: it is not called directly, but it is activated on a certain event with special rights that allow you to access in-coming and out-coming data that are stored in special virtual tables called Inserted and Deleted. Triggers exist in SQL Server since the version 1.0, even before CHECK constraint. They always work in the same unit-of-work of the T-SQL statement that has called them. There are different types of Triggers: Logon Trigger, DDL Trigger and DML Trigger; the most known and used type is Data Manipulation Language Trigger, also known as DML Trigger. This article treats only aspects related to DML Triggers.
There are many options that modify run time Triggers’ behavior, they are:
Each of these options has, of course, a default value in respect to the best practices of Triggers development. The first three options are server level options and you can change their default value using sp_configure system stored procedure, whereas the value of the last one can be set at the database level.
Are Triggers useful or damaging?
What do you think about Triggers? In your opinion, based on your experience, are they useful or damaging?
You will meet people who say: “Triggers are absolutely useful” and other people who say the opposite. Who is right? Reading the two bulleted lists you will find the main reasons of the two different theory about Triggers.
People say that Triggers are useful because with them:
- You can develop customize business logics without changing the user front-end or the Application code
- You can develop an Auditing or Logging mechanism that could not be managed so efficiently in any other application layer
People say that Triggers are damaging because:
- They can execute a very complex pieces of code silently
- They can degrade performance very much
- Issues in Triggers are difficult to diagnose
As usual the truth is in the middle. I think that Triggers are a very useful tool that you could use when there are no other ways to implement a database solution as efficiently as a Trigger can do, but the user has to test them very well before the deployment in a production environment.
Triggers activation order
SQL Server has no limitation about the number of Triggers that you can define on a table, but you cannot create more than 2.147.483.647 objects per database; so that the total of Table, View, Stored Procedure, User-Defined Function, Trigger, Rule, Default and Constraint must be lower than, or equal to this number (that is the maximum number that will be represented by the integer data type).
Now, supposing that we have a table with multiple Triggers, all of them ready to fire on the same statement type, for example on the INSERT statement: “Have you ever asked yourself which is the exact activation order for those Triggers?” In other worlds, is it possible to guarantee a particular activation order?
The Production.Product table in the AdventureWorks2014 database has no Triggers by design. Let’s create, now, three DML Triggers on this table, all of them active for the same statement type: the INSERT statement. The goal of these Triggers is printing an output message that allows us to observe the exact activation order. The following piece of T-SQL code creates three sample DML AFTER INSERT Triggers on Production.Product table.
USE [AdventureWorks2014];
GO
-- Create Triggers on Production.Product
CREATE TRIGGER Production.TR_Product_INS_1 ON Production.Product AFTER INSERT
AS
PRINT 'Message from TR_Product_INS_1';
GO
CREATE TRIGGER Production.TR_Product_INS_2 ON Production.Product AFTER INSERT
AS
PRINT 'Message from TR_Product_INS_2';
GO
CREATE TRIGGER Production.TR_Product_INS_3 ON Production.Product AFTER INSERT
AS
PRINT 'Message from TR_Product_INS_3';
GO
Let’s see all Triggers defined on Production.Product table, to achieve this task we will use the sp_helptrigger system stored procedure as shown in the following piece of T-SQL code.
USE [AdventureWorks2014];
GO
EXEC sp_helptrigger 'Production.Product';
GO
The output is shown in the following picture.

Picture 1 – All Triggers defined on Production.Product table
Now the question is: Which will be the activation order for these three Triggers? We can answer to this question executing the following INSERT statement on Production.Product table, when we execute it, all the DML INSERT Triggers fire.
USE [AdventureWorks2014];
GO
INSERT INTO Production.Product
(
Name, ProductNumber, MakeFlag, FinishedGoodsFlag, SafetyStockLevel,
ReorderPoint, StandardCost, ListPrice, DaysToManufacture, SellStartDate,
RowGUID, ModifiedDate
)
VALUES
(
N'CityBike', N'CB-5381', 0, 0, 1000, 750, 0.0000, 0.0000, 0, GETDATE(),
NEWID(), GETDATE()
);
GO
The output returned shows the default Triggers activation order.
Message from TR_Product_INS_1
Message from TR_Product_INS_2
Message from TR_Product_INS_3
As you can see in this example, Triggers activation order coincides with the creation order, but by design, Triggers activation order is undefined.
If you want to guarantee a particular activation order you have to use the sp_settriggerorder system stored procedure that allows you to set the activation of the first and of the last Trigger. This configuration can be applied to the Triggers of each statement (INSERT/UPDATE/DELETE). The following piece of code uses sp_settriggerorder system stored procedure to set the Production.TR_Product_INS_3 Trigger as the first one to fire when an INSERT statement is executed on Production.Product table.
USE [AdventureWorks2014];
GO
EXEC sp_settriggerorder
@triggername = 'Production.TR_Product_INS_3'
,@order = 'First'
,@stmttype = 'INSERT';
GO
At the same way, you can set the last Trigger fire.
USE [AdventureWorks2014];
GO
EXEC sp_settriggerorder
@triggername = 'Production.TR_Product_INS_2'
,@order = 'Last'
,@stmttype = 'INSERT';
GO
Let’s see the new Triggers activation order by executing another INSERT statement on Production.Product table.
USE [AdventureWorks2014];
GO
INSERT INTO Production.Product
(
Name, ProductNumber, MakeFlag, FinishedGoodsFlag, SafetyStockLevel,
ReorderPoint, StandardCost, ListPrice, DaysToManufacture, SellStartDate,
RowGUID, ModifiedDate
)
VALUES
(
N'CityBike Pro', N'CB-5382', 0, 0, 1000, 750, 0.0000, 0.0000, 0, GETDATE(),
NEWID(), GETDATE()
);
GO
The returned output shows our customized Triggers activation order.
Message from TR_Product_INS_3
Message from TR_Product_INS_1
Message from TR_Product_INS_2
In this session you have learnt how to set the activation of the first and of the last Trigger in a multiple DML AFTER INSERT Triggers scenario. Probably, one question has come to your mind: “May I set only the first and the last Trigger?” The answer is: “Yes, currently you have the possibility to set only the first Trigger and only the last Trigger for each statement on a single table”; as a friend of mine says (he is a DBA): “You can set the activation only of the first and of the last Trigger because you should have three Triggers maximum for each statement on a single table! The sp_settriggerorder system stored procedure allows you to set the first and the last Trigger fires, so that the third one will be in the middle, between the first and the last”.
Triggers must be thought to work on multiple rows
One of the most frequent mistakes I have seen during my experience in Triggers debugging and tuning is: the author of the Trigger doesn’t consider that his Trigger will work on multiple rows, sooner or later! I have seen many Triggers, especially those ones that implement domain integrity constraints, which were not thought to work on multiple rows. This mistake, in certain cases, produces the storing of incorrect data (an example will follow).
Suppose that you have to develop a DML AFTER INSERT Trigger to avoid to store values lower than 10 in the SafetyStockLevel column of the Production.Product table in the AdventureWorks2014 database. This customized business logic may be required to guarantee no production downtime in your company when a supplier is late in delivering.
The following piece of T-SQL code shows the CREATE statement for the Production.TR_Product_StockLevel Trigger.
USE [AdventureWorks2014];
GO
CREATE TRIGGER Production.TR_Product_StockLevel ON Production.Product
AFTER INSERT AS
BEGIN
/*
Avoid to insert products with value of safety stock level lower than 10
*/
BEGIN TRY
DECLARE
@SafetyStockLevel SMALLINT;
SELECT
@SafetyStockLevel = SafetyStockLevel
FROM
inserted;
IF (@SafetyStockLevel < 10)
THROW 50000, N'Safety Stock Level cannot be lower than 10!', 1;
END TRY
BEGIN CATCH
IF (@@TRANCOUNT > 0)
ROLLBACK;
THROW; -- Re-Throw
END CATCH;
END;
GO
A very good habit, before applying Triggers and changes (in general) in the production environment, is to spend time to test the Trigger code, especially for the borderline cases and values. So, in this example you have to test if this Trigger is able to reject each INSERT statement that tries to store values lower than 10 into SafetyStockLevel column of the Production.Product table. The first test you can do, for example, is trying to insert one wrong value to observe the error caught by the Trigger. The following statement tries to insert a product with SafetyStockLevel lower than 10.
USE [AdventureWorks2014];
GO
-- Test one: Try to insert one wrong product
INSERT INTO Production.Product
(Name, ProductNumber, MakeFlag, FinishedGoodsFlag, SafetyStockLevel,
ReorderPoint, StandardCost, ListPrice, DaysToManufacture,
SellStartDate, rowguid, ModifiedDate)
VALUES
(N'Carbon Bar 1', N'CB-0001', 0, 0, 3 /* SafetyStockLevel */,
750, 0.0000, 78.0000, 0, GETDATE(), NEWID(), GETDATE());
As you expect, SQL Server has rejected the INSERT statement because the value assigned to SafetyStockLevel is lower than 10 and the Trigger Production.TR_Product_StockLevel has blocked the statement. The output shows that Trigger worked well.
Msg 50000, Level 16, State 1, Procedure TR_Product_StockLevel, Line 17
Safety Stock Level cannot be lower than 10!
Now you have to test the Trigger for statements that try to insert multiple rows. The following statement tries to insert two products: the first product has a wrong value for SafetyStockLevel column, whereas the value in second one is right. Let’s see what happens.
USE [AdventureWorks2014];
GO
-- Test two: Try to insert two products
INSERT INTO Production.Product
(Name, ProductNumber, MakeFlag, FinishedGoodsFlag, SafetyStockLevel,
ReorderPoint, StandardCost, ListPrice, DaysToManufacture,
SellStartDate, rowguid, ModifiedDate)
VALUES
(N'Carbon Bar 2', N'CB-0002', 0, 0, 4 /* SafetyStockLevel */,
750, 0.0000, 78.0000, 0, GETDATE(), NEWID(), GETDATE()),
(N'Carbon Bar 3', N'CB-0003', 0, 0, 15 /* SafetyStockLevel */,
750, 0.0000, 78.0000, 0, GETDATE(), NEWID(), GETDATE());
GO
The output shows that the Trigger has worked well again, SQL Server has rejected the INSERT statement because in the first row the value 4 for the SafetyStockLevel column is lower than 10 and it can’t be accepted.
Msg 50000, Level 16, State 1, Procedure TR_Product_StockLevel, Line 17
Safety Stock Level cannot be lower than 10!
If you have to deploy your Trigger as soon as possible, you could convince yourself that this Trigger works properly, after all you have already done two tests and all wrong rows were rejected. You decide to apply the Trigger in the production environment; but what happens if someone or an application tries to insert two products, in which there is one wrong value put in an order that differs from the one you used in the previous test? Let’s see the following INSERT statement in which the first row is right and the second one is wrong.
USE [AdventureWorks2014];
GO
-- Test three: Try to insert two rows
-- The first row one is right, but the second one is wrong
INSERT INTO Production.Product
(Name, ProductNumber, MakeFlag, FinishedGoodsFlag, SafetyStockLevel,
ReorderPoint, StandardCost, ListPrice, DaysToManufacture,
SellStartDate, rowguid, ModifiedDate)
VALUES
(N'Carbon Bar 4', N'CB-0004', 0, 0, 18 /* SafetyStockLevel */,
750, 0.0000, 78.0000, 0, GETDATE(), NEWID(), GETDATE()),
(N'Carbon Bar 5', N'CB-0005', 0, 0, 6 /* SafetyStockLevel */,
750, 0.0000, 78.0000, 0, GETDATE(), NEWID(), GETDATE());
GO
The last INSERT statement has been completed successfully, but inserted data do not respect the domain constraint implemented by the Trigger, as you can see in the following picture.
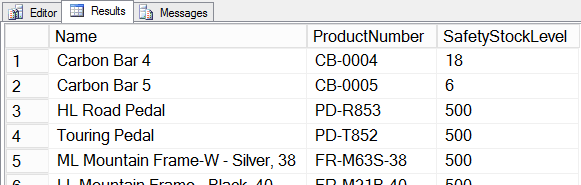
Picture 2 – Safety stock level domain integrity violated for product named “Carbon Bar 5”
The safety stock level value for the product named “Carbon Bar 5” doesn’t respect the business constraint implemented by the Trigger Production.TR_Product_StockLevel; this Trigger hasn’t been thought to work on multiple rows. The mistake is in the following assignment line:
SELECT
@SafetyStockLevel = SafetyStockLevel
FROM
Inserted;
The local variable named @SafetyStockLevel can contain only one value from the SELECT on the Inserted virtual table and this value will be the SafetyStockLevel value corresponding to the first row that is returned from the statement. If the first row (that one returned from the query) has a suitable value in the SafetyStockLevel column, the Trigger will consider right the others as well. In this case, not allowed values (lower than 10) from the second row on, will be stored anyway!
How can the Trigger’s author fix this issue? He can fix it by checking SafetyStockLevel value on all rows in the Inserted virtual table, and if the Trigger finds just one value which is not allowed it will return an error. Below here, there is the version 2.0 of the Trigger Production.TR_Product_StockLevel, it fixes the issue changing the previous SELECT statement in an IF EXISTS SELECT statement.
USE [AdventureWorks2014];
GO
ALTER TRIGGER Production.TR_Product_StockLevel ON Production.Product
AFTER INSERT AS
BEGIN
/*
Avoid to insert products with value of safety stock level lower than 10
*/
BEGIN TRY
-- Testing all rows in the Inserted virtual table
IF EXISTS (
SELECT ProductID
FROM inserted
WHERE (SafetyStockLevel < 10)
)
THROW 50000, N'Safety Stock Level cannot be lower than 10!', 1;
END TRY
BEGIN CATCH
IF (@@TRANCOUNT > 0)
ROLLBACK;
THROW; -- Re-Throw
END CATCH;
END;
GO
This new version is thought to work on multiple rows and it always works properly. However the best implementation for this business logic is by using CHECK constraint that is the best way to implement customize domain integrity. The main reason to prefer CHECK constraints instead of the Triggers, when you have to implement customize domain integrity, is that all constraints (such as CHECK, UNIQUE and so on) will be checked before the execution of the statement that fires it. On the contrary, AFTER DML Triggers will fire after the statement has been executed. As you can imagine, for performance reasons, in this scenario, the CHECK constraint solution is better than the Trigger solution.
Trigger debug
The most important Programming Languages have debugging tools integrated into the development tool. Debugger usually has a graphic interface that allows you to inspect the variables values at run-time to analyze source code and program flow row-by-row and finally to manage breakpoints.
Each developer loves debugging tools because they are very useful when a program fails in a calculation or when it returns into an error. Now, think about a Trigger that performs a very complex operation silently. Suppose that this Trigger works into a problem; probably, this question comes to your mind: “Can I debug a Trigger” and if it is possible, “How can I do it?”
Debugging a Trigger is possible with Microsoft Visual Studio development tool (except Express edition).
Consider the first version of the Trigger Production.TR_Product_StockLevel created in the section “Triggers must be thought to work on multiple rows” at the beginning of this article. As you have already seen, the first version of that Trigger doesn’t work well with multiple rows because it hadn’t been thought to work with multiple rows. The customer in which you deployed that Trigger complains that some products have the safety threshold saved in the SafetyStockLevel column lower than 10. You have to debug that DML AFTER INSERT Trigger, below here you will learn how to do it.
The first step to debug a Trigger is to create a stored procedure that encapsulates the statement that is able to fire the Trigger that you want to debug. Right, we have to create a stored procedure that performs an INSERT statement to the Production.Product table of the AdventureWorks2014 database. The following piece of T-SQL code creates the Production.USP_INS_PRODUCTS stored procedure in the AdventureWorks2014 database.
USE [AdventureWorks2014];
GO
CREATE PROCEDURE Production.USP_INS_PRODUCTS
AS BEGIN
/*
INSERT statement to fire Trigger TR_Product_StockLevel
*/
INSERT INTO Production.Product
(Name, ProductNumber, MakeFlag, FinishedGoodsFlag, SafetyStockLevel,
ReorderPoint, StandardCost, ListPrice, DaysToManufacture,
SellStartDate, rowguid, ModifiedDate)
VALUES
(N'BigBike8', N'BB-5388', 0, 0, 10 /* SafetyStockLevel */,
750, 0.0000, 78.0000, 0, GETDATE(), NEWID(), GETDATE()),
(N'BigBike9', N'BB-5389', 0, 0, 1 /* SafetyStockLevel */,
750, 0.0000, 62.0000, 0, GETDATE(), NEWID(), GETDATE());
END;
The second step consists in the execution of the stored procedure, created in the previous step, through Microsoft Visual Studio.
Open Microsoft Visual Studio and surf into SQL Server Object Explorer, open the AdventureWorks2014 database tree, expand Programmability folder and try to find out the Production.USP_INS_PRODUCTS stored procedure into Stored Procedures folder. Next, press right click on Production.USP_INS_PRODUCTS stored procedure, a context pop-up menu will appear and when you select the item “Debug Procedure…”, a new SQL Query page will be open and it will be ready to debug the stored procedure as you can see in the following picture.
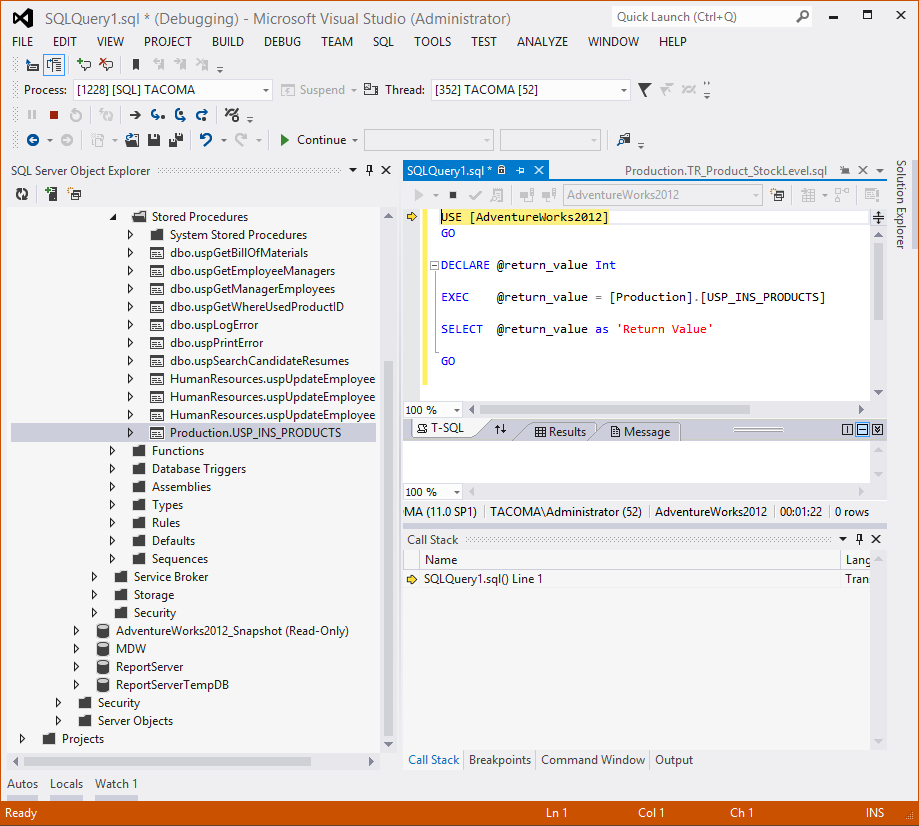
Picture 3 – Debugging USP_INS_PRODUCTS stored procedure through Microsoft Visual Studio
The execution pointer is set to the first executable instruction of the T-SQL script automatically generated by the Visual Studio Debugger Tool. Using step into debugger function (F11) you can execute the Production.USP_INS_PRODUCTS stored procedure step-by-step up to the INSERT statement that will fire the Trigger you want to debug. If you press step into button (F11) when the execution pointer is on the INSERT statement, the execution pointer will jump into the Trigger, on the first executable statement, as shown in the following picture.
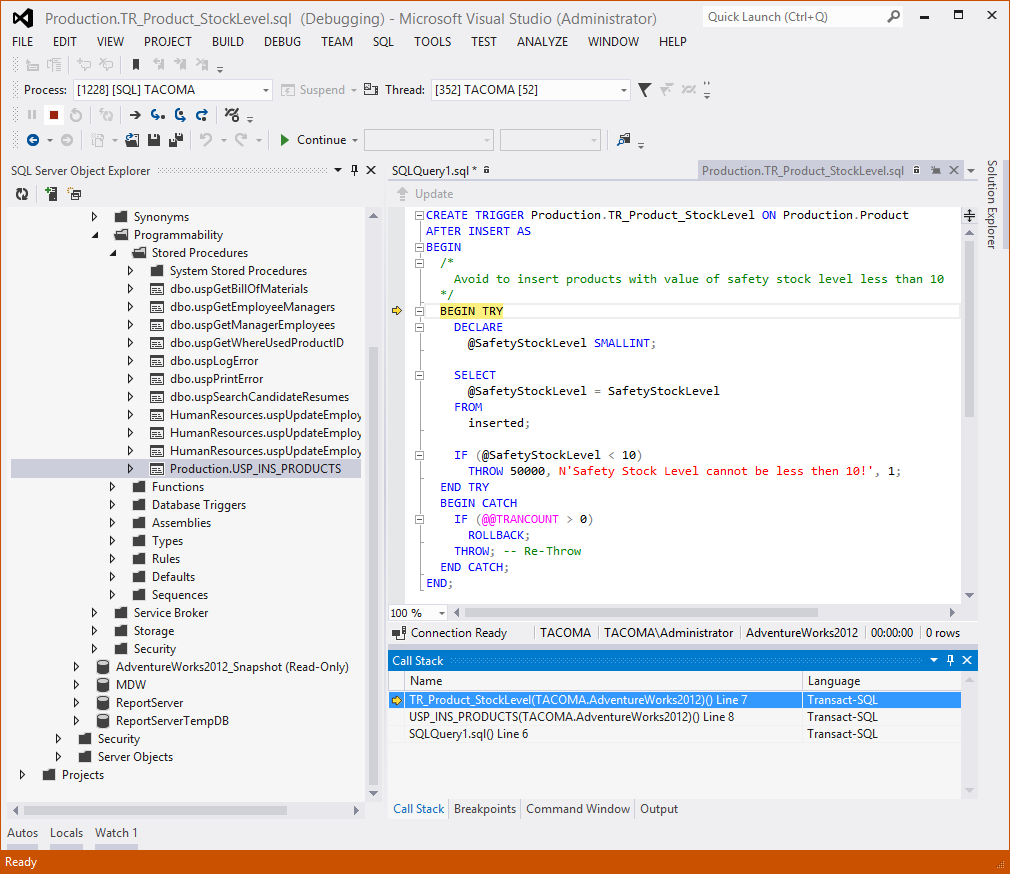
Picture 4 – Breakpoint within a Trigger
Debugger execution pointer is now on the first executable statement of the Trigger, now you can execute the Trigger’s code and observe variables content step-by-step. In addition, you can see the exact execution flow and the number of rows affected by each statement. If multiple Triggers fire on the same statement, the Call Stack panel will show the execution chain and you will be able to discover how the Trigger’s code works.
Statements that each Trigger should have
A Trigger is optimized when its duration is brief, it always works within a transaction and its locks will remain active till the transaction will is committed or rolled back. As you can imagine, the more time the Trigger needs to execute, the higher the possibility that the Trigger will lock another process in the system will be.
The first thing you have to do to ensure that the Trigger execution will be short is to establish if the Trigger has to do something or not. If there are no rows affected in the statement that has called the Trigger, this means that there are no things for the Trigger to do. So, the first thing that a Trigger should do is to check the number of rows affected by the previous statement. The system variable @@ROWCOUNT allows you to know how many rows have been changed by the previous DML statement. If the previous DML statement hasn’t changed the rows, the value of the system variable @@ROWCOUNT will be zero, so that there are no things that the Trigger has to do except giving back the control flow to the caller by the RETURN (T-SQL) command.
The following piece of code should be placed at the beginning of all Triggers.
IF (@@ROWCOUNT = 0)
RETURN;
Checking the @@ROWCOUNT system variable allows you to verify if the number of rows affected is the number you expect, if not, the Trigger can give back the control flow to the caller. In a Trigger active on multiple statement, you can query the virtual table Inserted and Deleted to know the exact number of inserted and updated (or deleted) rows.
After that, you should consider that for each statement executed, SQL Server sends back to the client the number of rows affected, so if you aren’t interested about the number of rows affected by each statement within a Trigger, you can set to ON the NOCOUNT option at the beginning of the Trigger and at the end you can flip back the value to OFF. In this way, you will reduce network traffic dramatically.
In addition, you could check if interested columns are updated or not. The UPDATE (T-SQL) function allows you to know if the column passed by is updated or not (within an update Trigger) and if the column is involved into an INSERT statement (within an insert Trigger). If the column is not updated, the Trigger has another chance to give back the control flow to the caller or it goes on. In general, an update Trigger has to do something when a column is updated and its values are changed; if there are no changed values, probably the Trigger has another chance to give back the control flow to the caller. You can check if the values are changed by querying the virtual tables Inserted and Deleted.
Summary
Triggers seem easy to write, but writing efficient Triggers as demonstrated is not simple task. A best practice is to test them thoroughly before the deployment in your production environment. A good habit is putting inside them lots of comments, especially before complex statements that may confuse even the trigger writer.
About the author
.png)
Since 1999 Sergio Govoni has been a software developer; in the 2000 he received degrees in Computer Science from The Italy State University. He has worked for over 11 years in a software house that produces multi-company ERP on Win32 platform. Today, at the same company, he is a program manager and software architect and he is constantly involved on several team projects, where he takes care of the architecture and the mission-critical technical details.
Since 7.0 version he has been working with SQL Server and he has a deep knowledge of Implementation and Maintenance Relational Databases, Performance Tuning and Problem Solving skills. He also works training people on SQL Server and its related technologies, writing articles and participating actively, as speaker, at conference and workshops UGISS (www.ugiss.org), the first and most important Italian SQL Server User Group. He has the following certifications: MCP, MCTS SQL Server.
Sergio lives in Italy and loves to travel around the world. When he is not at work to deploy new software and increase his knowledge of Technologies and SQL Server, Sergio enjoys spending time with his friends and with his family. You can meet him at conferences or Microsoft events. Follow him on Twitter or read his blogs in Italian and English
About MVP Mondays
.jpg)
The MVP Monday Series is created by Melissa Travers. In this series we work to provide readers with a guest post from an MVP every Monday. Melissa is a Community Program Manager, formerly known as MVP Lead, for Messaging and Collaboration (Exchange, Lync, Office 365 and SharePoint) and Microsoft Dynamics in the US. She began her career at Microsoft as an Exchange Support Engineer and has been working with the technical community in some capacity for almost a decade. In her spare time she enjoys going to the gym, shopping for handbags, watching period and fantasy dramas, and spending time with her children and miniature Dachshund. Melissa lives in North Carolina and works out of the Microsoft Charlotte office.