BizTalk Integration Development Architecture: Artifact Composition
Editor’s note: The following post was written by Microsoft Integration MVP Leonid Ganeline
BizTalk Integration Development Architecture: Artifact Composition
This is the second in series of articles.
The first article is “BizTalk Integration Development Architecture”.
Artifact composition describes several aspects of the BizTalk Integration architecture:
- Naming conventions
- Folder structure
- Shared Artifacts
Change Management, Update Rule
Integration is a never-ended endeavor. The BizTalk Integration embraces many unrelated projects, created by different developer teams with different skill sets and with different requirements. It is almost impossible to create architecture rules which could survive all this way. One smart way is to hire the most experienced developer/architect who creates a good starting rule set and architecture patterns, so it would embrace the best existed practices as soon as possible. But the changes and modifications are inevitable.
One way to fight this problem is a rule about updates. J
Is it a problem or not? Let’s see an example:
The BizTalk Integration includes 50 BizTalk applications which were created through 10 year development effort. The 25th application was the Notification application which is used as a notification hub for all other applications. All 25+th new applications use this Notification application. But the old applications do not use it. They use several “unconventional” notification methods.
Now one of these old applications should be modified for some unrelated reasons. Resources were found for the modification. What about this Notification hub? Should it be a part of this modification or should not?
The Update rule could be:
Each application update should include all architecture updates which were happened between now and the last application update.
It sounds familiar. This rule mimics the definition of the service pack which usually includes all up-to-date fixes. With this rule we keep the applications in good shape, we easily track the legacy applications, we track the up-to-date fixes.
Tip: Keep a table with applications as rows and the architecture updates as columns, and we always know the current state of updates.
It could be some different rule. For example, the architecture update should be implemented immediately on all applications which satisfy some criteria.
Any Update rule is much better than no rule at all. When we develop a standalone application we don’t know if this application version is the last version or the application is going to live for years with many updates on this way. But the BizTalk Integration is always never-ended process, so the Update rule is a good candidate for a good architecture.
Naming conventions
Naming Conventions are placed in a separate document. Please, use these naming conventions as source information.
Folder Structure
The folder structure copycats the artifact hierarchy. Because the namespaces also copycat the artifact hierarchy, the folder structure looks like the namespace structure.
The namespace is the better formal representation of the hierarchy, so I copy the folder structure from the namespaces not the opposite way.
The main rule is:
Folder structure and folder names should be a copy of a namespace or the namespace pieces [a copy of the artifacts saved into the folders].
Seems complex, but it is simpler if we use pictures to demonstrate this rule.
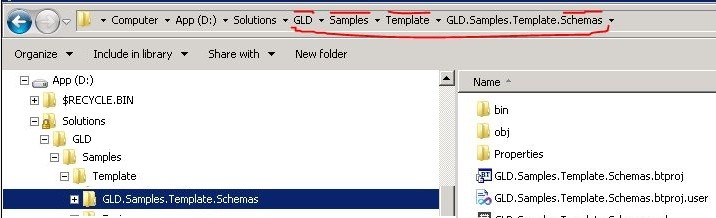
The name of the project could be just Schemas, but the full project namespace as a name is better. Here two rules are “fighting” for dominance.
One rule is: names of a project, a project assembly, a project namespace, and a project folder should be the same.
The second rule is: Folder name should be equal to the correspondent part of the namespace.
The first rule is a winner.
So we use the folders names: GLD, Samples, and Template for all projects which namespace started with “GLD.Samples.Template”. But for the Schema project folder we use “GLD.Samples.Template.Schemas” not “Schemas”.
If we group several projects inside single solution, we follow the same rule for the additional group folder names.
For example, we group the projects inside the Shared.Schemas solution by a system name, which is CRM or Internal or SAP or Shipping. So we create subfolders for each group:

Do not forget to use the same rule for the solution folders inside Visual Studio:

This rule is very important for the big BizTalk Integration. Imagine a hundred applications and a hundred Visual Studio solutions. You are going to investigate and fix an error. All you know is the assembly name, it is GLD.Samples.Shared.Classes.Shipping. If you are a developer, you instantly know that you have to open the GLD.Samples.Shared.Classes Visual Studio solution to look to the code. If you are an administrator, you instantly know that you have to check the GLD.Samples.Shared.Classes BizTalk application. If you the source code manager, you instantly know where this code is saved on TFS or Git.
If you have ever searched an assembly GLD.Samples.Shared.Classes.Shipping and finally find out code in the GLD.Samples.Sap project which was placed in the GLD.Shipping solution, you completely spoil your time. If you start to investigate the assembly relations in such mess, you are completely doomed.
Shared Artifacts
To Share or Not To Share?
There are several aspects. We are considering this question from different points of view: development, deployment, operations.
Too many shared artifacts results in too complex relations between assemblies, projects and applications. Artifacts should be shared only for a good reason.
The BizTalk Server controls the relations between assemblies in very strict rules. One of this rule is: If we want to redeploy a shared assembly, we have to previously undeploy all assemblies which reference our shared assembly. That rule is super important in the big BizTalk Integration.
Development usually pushes us to share artifacts to use more compact and organized code.
Deployment, from the other side, pushes us to denormalize code, because shared code complicates deployment and redeployment.
Please, consider both sides before starting to implement a shared component.
If we share, we reuse, which couples code. Changes in shared artifacts could trigger changes in the sharing artifacts.
If we don’t share, we broke relation between artifacts. Changes in isolated artifacts do not change anything outside those artifacts.
It is possible to share without creating relation between artifacts, if we share template, pattern, idea, not the code, not the artifact itself.
Schemas
As discussed a schema is a very special artifact. It plays the contract role in the BizTalk applications. Services in SOA architecture do not share code, they share contracts. For BizTalk development this means we share schemas between systems, we share schemas between applications.
The schemas are good candidates for sharing. Quite few schemas are designed not to be shared and used only for internal purposes.
So, if schemas belong to an external system are generated by an [adapter] wizard, they are/will be shared in the most cases. Place them in a Shared.Schemas application under a separate project.
If schemas are canonical schemas, place them in a Shared.Schemas application in the Canonical project group under a separate project.
If schemas are shared only inside single application, they could be placed in a separate project of the current solution. If all application artifacts are placed in one project, the schemas also could be placed in this project.
Let’s see a real-life example.
Shared Schemas Architecture Example
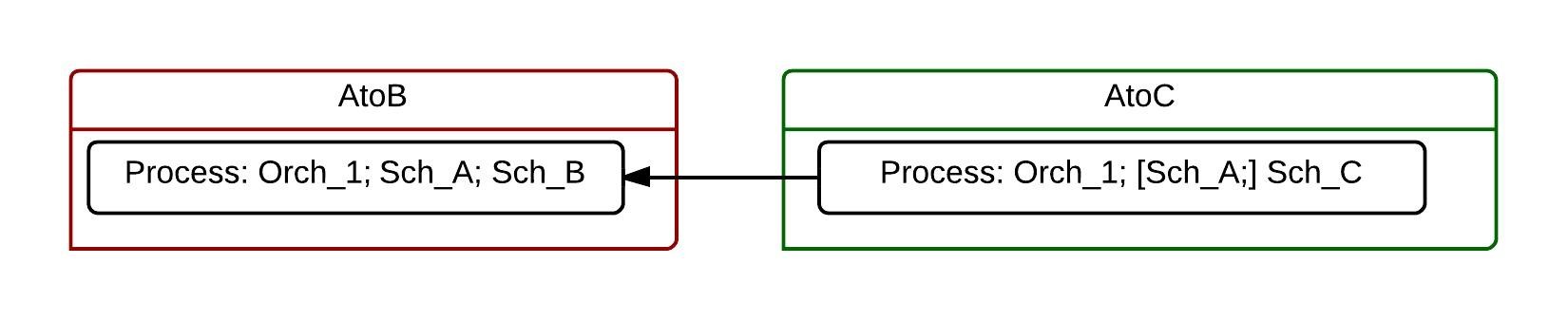
Application AtoB was created the first. It transfers data between systems A and B. Next was the AtoC application and it exchanges data between systems A and C. Both applications use the Sch_A schema. BizTalk uses schema not in the application namespace but in the global namespace. That means BizTalk cannot recognize a schema if it was deployed in several applications. A schema should be deployed only once, if we want to use this schema in the ports. This rule protects us from severe design errors but it also forces us to share schemas.
For our example that means, we cannot deploy Sch_A into both applications. The naïve approach is to reference AtoB.Process assembly from the AtoC.Process. I mentioned this placing Sch_B in the brackets on the picture.
So far so good.
Then we found out a bug in AtoB application, not in the Sch_A but in Orch_1. We fixed it and want to deploy a new AtoB.Process assembly. No so good, because first we have to undeploy AtoC application because it references the AtoB. That is not good. Now AtoC is related to any modifications in AtoB not only to the Sch_A.
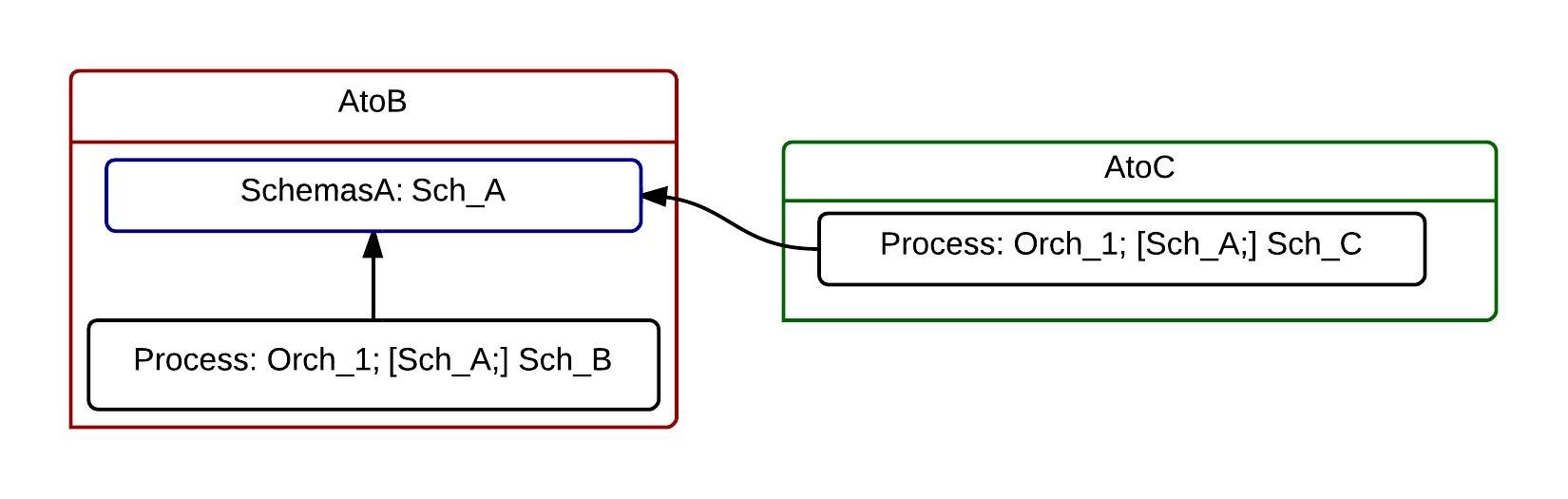
Let’s fix it. We extracted schema Sch_A into a separate project/assembly. Now we don’t have to redeploy AtoC.Process when we change something in Sch_B or in Orch_1, but only if we change Sch_A.
But it still doesn’t look right. From the design standpoint the Sch_A does not belong to the AtoB application. It does not belong to the AtoC application either. Both applications us it, but it is an independent of them. Only system A dictates how the Sch_A schema looks like. Owners of this system can change it, not the owners/developers of the AtoB and AtoC applications.
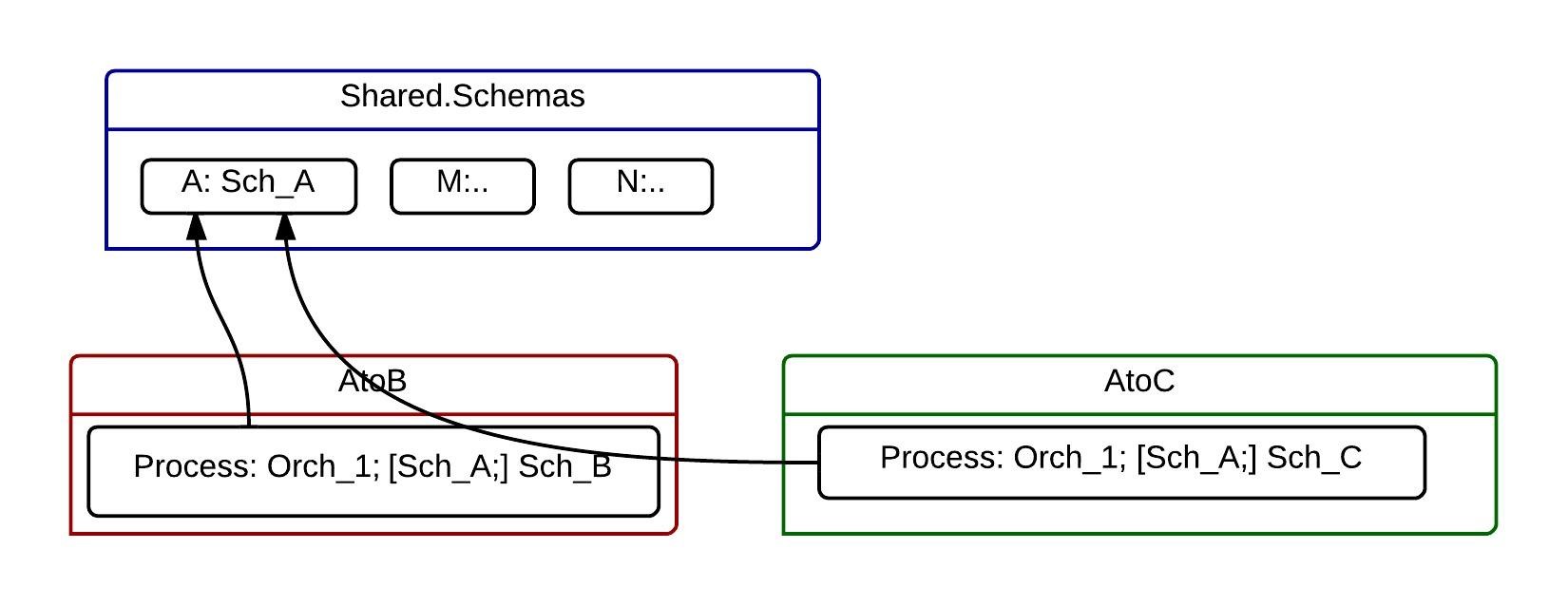
Let’s change our design to show this ownership. A new Shared.Schemas application was created, which holds all schemas that belong to the integrated systems. Our Sch_A was placed into a separate, independent projects. Now AtoB and AtoC both reference this Shared.Schemas.A assembly.
Isn’t is something wrong? How do our changes simplify our development, deployment, operations? Looks like now we have one more application and one more reference (from AtoB to the Shared.Schemas.A). How it could be simpler?
The key word here is “changes”. If our applications will never be changed we don’t need these “improvements”. Actually we don’t need AtoB and AtoC but just one application holding all artifact.
But when we start to modify our applications we immediately start to understand that “loose coupling” is not just funny words.
Next step is to ask a question “why is the Sch_A schema so special and not the Sch_C and Sch_B schemas”? All those schemas belongs to the integrated systems not to the integrating applications.
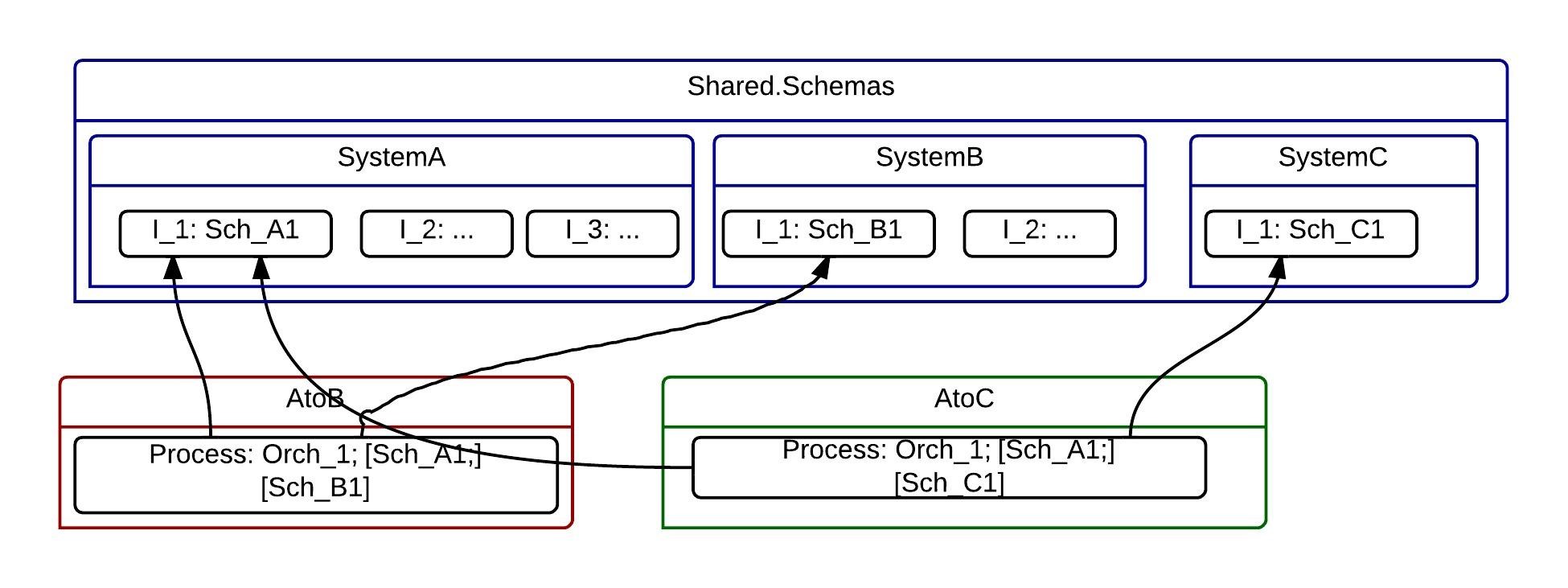
Let’s change our design to fix this. Now schemas of all systems are placed into separate assemblies. Moreover, we found out these systems have (or could have) several interfaces, not only a single interface, hence we got several assemblies for each interface. I use an interface term here as a separate data contract/schema. For sure, if it is a two-way interface (as request-response), both the request and response schemas belong to the same assembly.
Again, the resulted design looks more complex but it is more appropriate for the real life. And it models the real relations.
Next step in our design is to mention that we integrated two systems, B and C, with one system A. What happens if we add one more system or replace one of the system? Seems the canonical data model fits here perfectly.
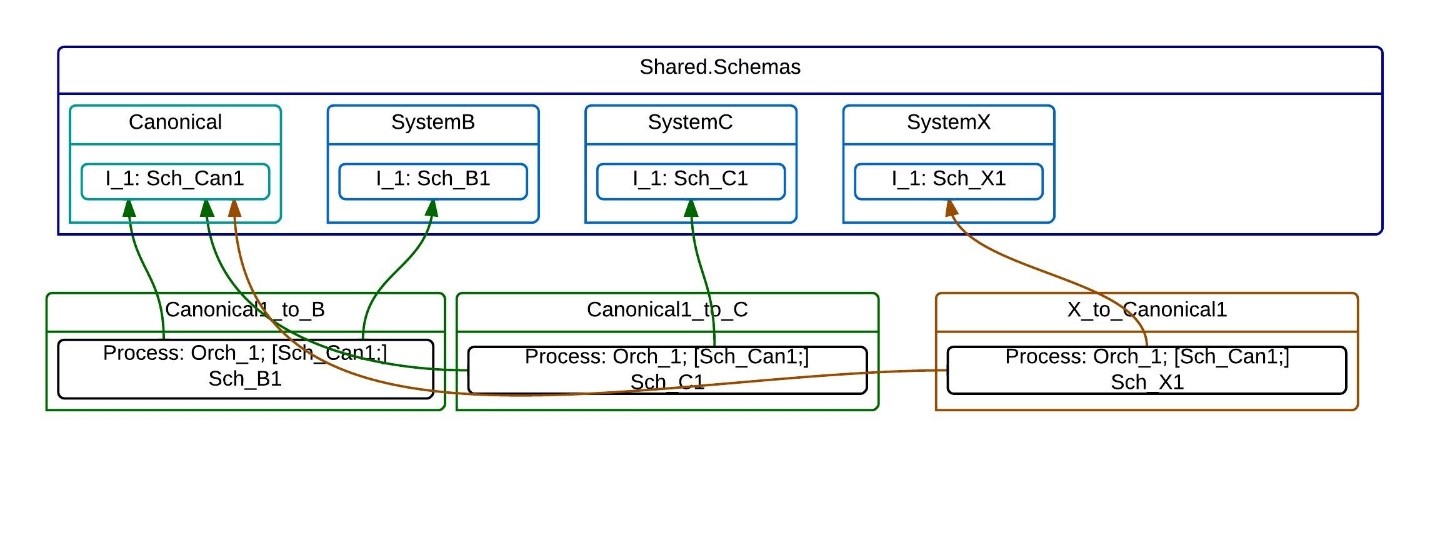
Let’s create a canonical schema for this interface (I_1 interface) and link the systems through this canonical schema. Now each application deals exactly with one system. Each application deals with implementation details of this single system. Changes in this system will not force us to modify another applications. Before that if system A does change its interface, we have to modify both AtoB and AtoC applications. Now, we change only X_to_Canonical1. I intentionally changed the A application name to the X, to show, that we can easily add Y, Z, etc. systems to the picture without changing any other application.
Canonical data model is not a universal, required design pattern. It works if we have one-to-many or many-to-many integration interfaces between systems. It doesn’t make sense to use it if we have one-to-one interface.
Here is a template Shared.Schemas application code which can save us some precious development time.
.NET classes
.NET classes can be shared between the BizTalk applications. It doesn’t create the “redeployment hell” as it could happen with sharing other BizTalk artifacts: schemas, maps, orchestrations, pipelines, etc.
If we need to modify a .NET assembly, we just re-GAC it. This does not require to undeploy all related assemblies.
One recommendation: Do not share .NET class right away. Try it in one application as a local class for this application. Try it in the next application. When this class is stabilized, when you feel it will not be changed too much in the future, extract it in a shared project. Usually those shared assemblies are placed inside one Shared.Classes application.
Here is a template Shared.Classes application code which can save us some precious development time.
Maps, Orchestrations, Pipelines, etc.
Other BizTalk artifacts, not the schemas, are not good for sharing.
We share the pipelines, maps, orchestrations, rules only in very special occasions, usually as the components of the BizTalk shared infrastructure. One example is a notification service that manages notifications: formats notifications, filters notifications, sents them as emails, SMS-s, twitts, etc. Always consider to share artifacts as a service.
Maps are usually totally local to the application. It is a really bad thing to share maps between applications from the design point of view.
If you want to share the orchestration, do not share the orchestration assembly between applications. Share it as a service.
If you call or start an orchestration from another application, you have to reference the orchestration assembly. So consider to use another architecture pattern, like direct binding. That means the calling orchestration just publishes (sends) messages and the called orchestrations subscribe to these messages. If you want to pass the additional parameters with message use the message context properties. The message context also can be used to create the “custom binding” when subscriptions have additional predicates which match for example the originator orchestration name.
The pipelines also should not be shared between applications. But the pipeline components can be shared.
About the author

With 9+ years BizTalk Server experience Leo is working as a BizTalk Developer, Architect, and System Integrator.
He got awards: The Microsoft Most Valuable Professional [MVP] Awards 2007, 2008, 2009, 2010, 2011, and 2012 in BizTalk Server; The Microsoft MVP Award
2013 in Microsoft Integration.
Leo is a Moderator of the BizTalk Server General forum on the Microsoft MSDN site, he is a blogger [https://geekswithblogs.net/LeonidGaneline/ and https://ganeline.wordpress.com/] and
author of the Microsoft TechNet articles and MSNS Gallery/Samples.
About MVP Monday
The MVP Monday Series is created by Melissa Travers. In this series we work to provide readers with a guest post from an MVP every Monday. Melissa is a Community Program Manager, formerly known as MVP Lead, for Messaging and Collaboration (Exchange, Lync, Office 365 and SharePoint) and Microsoft Dynamics in the US. She began her career at Microsoft as an Exchange Support Engineer and has been working with the technical community in some capacity for almost a decade. In her spare time she enjoys going to the gym, shopping for handbags, watching period and fantasy dramas, and spending time with her children and miniature Dachshund. Melissa lives in North Carolina and works out of the Microsoft Charlotte office.